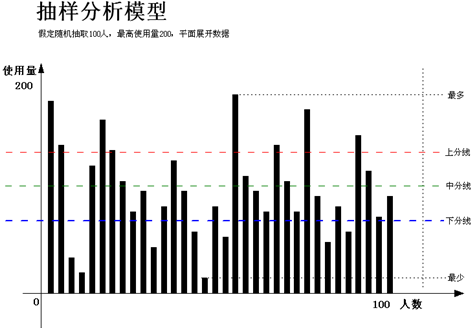
数据分析中常用的数据模型 一、抽样分析模型 建模方法 首先确定统计的时间段,暂定为15天;从数据库中随机抽取若干名用户作为分析样本建立分析模型,模型图中假定抽样人数为100人,15天内最高使用量 ...
2017-11-09
SPSS混合模型:线性混合模型 一、线性混合模型(分析-混合模型-线性) 1、概念:“线性混合模型”过程扩展了一般线性模型,因此允许数据表现出相关的和不恒定的变异性。因此,线性混合模型提供了不仅能够就 ...
2017-11-08
python数据结构之二叉树的统计与转换实例 这篇文章主要介绍了python数据结构之二叉树的统计与转换实例,例如统计二叉树的叶子、分支节点,以及二叉树的左右两树互换等,需要的朋友可以参考下 一、获取二叉树 ...
2017-11-08
Python利用前序和中序遍历结果重建二叉树的方法 本文实例讲述了Python利用前序和中序遍历结果重建二叉树的方法。分享给大家供大家参考,具体如下: 题目:输入某二叉树的前序遍历和中序遍历的结果,请重建出 ...
2017-11-08Python探索之创建二叉树 这篇文章主要介绍了Python探索之创建二叉树,Python的相关内容,小编是初窥门径。这里分享给大家一些简单知识,供需要的朋友参考。 问题 创建一个二叉树 二叉树有限多个节点的集合, ...
2017-11-08SPSS广义线性模型:广义估计方程 一、广义估计方程: 1、概念:广义估计方程过程对广义线性模型进行了扩展,以允许分析重复的测量或其他相关观察数据,例如聚类数据。 2、示例。公共卫生官员 ...
2017-11-08python中requests爬去网页内容出现乱码问题解决方法介绍 最近在学习python爬虫,使用requests的时候遇到了不少的问题,比如说在requests中如何使用cookies进行登录验证,这可以查看这篇文章。这篇要解决的问题 ...
2017-11-07
SPSS生存函数-Kaplan-Meier 一、Kaplan-Meier生存分析(分析-生存函数-Kaplan-Meier) 1、概念:在多数情况下,您都会希望考察两个事件之间的时间分布,比如雇用时长(员工从雇用到离开公司的时间 ...
2017-11-07SPSS对数线性模型:模型选择 一、模型选择对数线性分析(分析-对数线性模型-模型选择) 1、概念“模型选择对数线性分析”过程分析多阶交叉制表(列联表)。它使用成比例拟合的迭代算法将分层对数线 ...
2017-11-07理解Python中的类与实例 面向对象最重要的概念就是类(Class)和实例(Instance),必须牢记类是抽象的模板,比如Student类,而实例是根据类创建出来的一个个具体的“对象”,每个对象都拥有相同的方法,但各自 ...
2017-11-07python正则表达式re之compile函数解析 这篇文章主要介绍了python正则表达式re之compile函数解析,介绍了其定义,匹配模式等相关内容,具有一定参考价值,需要的朋友可以了解下。 re正则表达式模块还包括一些 ...
2017-11-07python里使用正则表达式的组嵌套实例详解 这篇文章主要介绍了python里使用正则表达式的组嵌套实例详解的相关资料,希望通过本文能帮助到大家,需要的朋友可以参考下 由于组本身是一个完整的正则表达式,所以可以 ...
2017-11-06
SPSS分析:Bootstrap 一、原理: 非参数统计中一种重要的估计统计量方差进而进行区间估计的统计方法,也称为自助法。其核心思想和基本步骤如下: 1、采用重抽样技术从原始样本中抽取一定数量 ...
2017-11-06
SPSS最优尺度:非线性典型相关性分析 一、非线性典型相关性分析(分析-降维-最优尺度) 1、概念:非线性典型相关性分析对应于使用最优尺度的分类典型相关性分析。此过程的目的是确定分类变量集相互 ...
2017-11-06
数据分析—问卷调查从模型到算法 每个人心中都有一个完美的另一半,如何去找到这个自己心中最认可的另一半,在慢慢人生旅途中,我们所经历过的事情,都在影响着我们的决定,影响着我们对另一半的选择,这将是 ...
2017-11-06
数据分析漏斗模型浅谈 学习数据分析的朋友应该都听过漏斗模型,但真正了解的可能并不多。因为它不仅仅是一个模型,更是一种可以普遍适用的方法论,或者说是一种思维方式。 今天主要谈谈漏斗模型的本质、漏斗 ...
2017-11-06
SPSS分析:复杂样本 一、概念: 复杂样本在很多方面与简单随机样本不同。在简单随机样本中,各抽样单元是直接从整个总体中采用不放回方式以等概率(WOR)随机选择的。相比之下,给定的复杂样本具有以 ...
2017-11-05
SPSS最优尺度:分类回归 一、分类回归(分析-回归-最佳尺度) 1、概念:分类回归通过为类别指定数值来量化分类数据,从而生成转换后变量的最优线性回归方程。分类回归也用缩写词CATREG来表示(代表 ...
2017-11-05
最常用的四种大数据分析方法 本文主要讲述数据挖掘分析领域中,最常用的四种数据分析方法:描述型分析、诊断型分析、预测型分析和指令型分析。 当刚涉足数据挖掘分析领域的分析师被问及,数据挖掘分析人员 ...
2017-11-05Python Nose框架编写测试用例方法 本文主要介绍nose框架编写自动化测试用例的方法。 2. Nose编写测试用例方法 nose会自动识别源文件,目录或包中的测试用例。 任何匹配testMatch正则表达式(默认为(?:^|[\\b_\\ ...
2017-11-05【核心关键词】软件、洞察力、大数据、产品、经验、硬件、流量、创新、决策、数据安全、网络安全、数据分析、决策制定、数据挖 ...
2026-06-18在方案选型、效果复盘、产品评估、供应商筛选等各类业务决策场景中,仅凭单一指标下结论往往会陷入 “以偏概全” 的误区。多维度 ...
2026-06-18 很多数据分析师精通Excel单元格操作,但当被问到“表结构数据的基本处理单位是什么”“字段和记录的本质区别”“为什么表结 ...
2026-06-18在数据分析、用户运营与业务增长的工作体系中,漏斗拆解是最基础也最高频的问题定位方法。很多业务场景下,我们只能看到最终的转 ...
2026-06-17在数据库开发、数据清洗与报表统计场景中,数值类型转换为日期是高频刚需操作。业务系统常以 Unix 时间戳、整型日期(如20240617 ...
2026-06-17 数据分析师八成以上的时间在和数据表格打交道,但许多人拿到Excel后习惯性地先算、先分析,结果回头发现漏了一列关键数据, ...
2026-06-17【核心关键词】数据库、电商、知识、产品、数据产品、监管业务、产品经理、业务系统、用户行为分析、用户分析、数据分析、电商 ...
2026-06-16在 Python 动态类型与面向对象的编程体系中,变量定义与类实例化是构建代码逻辑的两大核心基石。变量是数据存储、传递与运算的基 ...
2026-06-16 很多数据分析师每天与Excel打交道,但当被问到“表格结构数据和表结构数据有什么区别”“数据类型误判会引发哪些分析错误” ...
2026-06-16在 MySQL 查询性能优化体系中,索引是降低查询耗时、提升数据库吞吐的核心手段。其中联合索引与覆盖索引是实际开发中最高频的两 ...
2026-06-15在数据仓库建设与商业智能分析体系中,维度建模是应用最广泛的建模方法论,而事实表与维度表是维度建模的两大核心构件,共同构成 ...
2026-06-15 很多数据分析师能熟练计算指标,但当被问到“这家企业的核心业务目标是什么”“如何把模糊的战略目标拆解为可量化的指标”“ ...
2026-06-15在数据分析、业务监控、运营复盘等场景中,列值趋势计算是核心需求之一。无论是分析销售额的月度增长、用户活跃的变化趋势、库存 ...
2026-06-12在数字经济深度渗透的当下,消费者的购买行为已从过去的 “被动接受” 转变为 “主动决策”。流量红利消退、获客成本攀升、用户 ...
2026-06-12CDA三级认证是三个级别中的塔尖,全面考察数据战略、团队领导和复杂项目的综合能力。它所对应的《敏捷数据挖掘》教材,不再局限 ...
2026-06-12在游戏产业的商业逻辑中,付费玩家是支撑游戏生存与发展的核心支柱。行业普遍遵循 “二八定律”:20% 的付费玩家贡献了游戏 80% ...
2026-06-11【核心关键词】企业、定位、传统、产品、互联网、可视化、业务侧、数字化、结构化、数据分析、传统制造业、市场状态、发展空间 ...
2026-06-11 解读《CDA二级教材:量化策略分析(2025)》的全景结构与学习逻辑 ” CDA二级认证是企业招聘数据分析师时最常提及的证书门槛 ...
2026-06-11【核心关键词】药企、可视化、营销、分类、数据分析师、销售数据、业务人员、指导方向、分析报告、营销数据、营销医生 【专访摘 ...
2026-06-10在统计学分析、问卷调研、实验验证、业务复盘等场景中,卡方检验与 T 检验是应用最广泛的两类基础假设检验方法。前者专门处理分 ...
2026-06-10





