持证人简介:贺渲雯 ,CDA 数据分析师一级持证人,互联网行业数据分析师
今天我将为大家带来一个关于用户私域用户质量数据分析的案例分享,主要围绕三部分来进行阐述。
学习入口:https://edu.cda.cn/goods/show/3853?targetId=6765&preview=0
01 私域用户质量数据分析
我们以一家专注于私域运营的企业为案例,这家企业的运营模式主要通过社群拉新实现用户增长,主要采用线上拉新的模式获取用户。
线上拉新模式主要是由商务拓展(BD)团队寻找商家合作,由商家邀请用户加入社群。
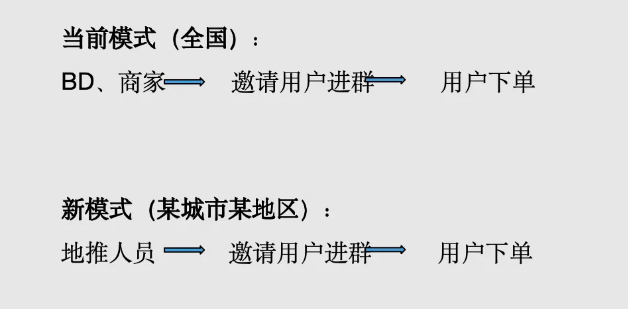
之后,企业还推出了一种地推拉新模式,即线下拉新。线下拉新由地推人员邀请用户进群,用户进群后同样可以领取优惠券并下单。
因此,需要对线上拉新和线下拉新两种模式下的用户各项指标进行对比分析,以评估其交易转化情况。
我们先来分析下关注用户的物理特征,包括末次访问城市、90天内下单情况以及末单物理城市等。
本次线下拉新试点选择在长沙进行。数据显示,末次访问城市中,仅有70%的用户位于长沙,其余30%的用户来自其他城市。
在90天内有下单行为的用户占比65%,还有35%的用户没有下单行为。
从城市来看,62%的订单收货地址在长沙,3%的订单收货地址来自其他城市。
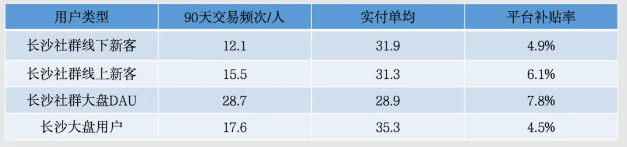
我们从三个交易指标进行分析:90天内人均交易频次、客单价和平台补贴率。

从数据可以看出,活跃用户的交易频次更高,而线下新客和线上新客的交易频次相对较低。
综合来看,与长沙社群活跃用户以及整体新客交易数据对比,本次线下拉新成功的用户具有以下特征:交易频次更低、实付客单更高、平台补贴率更低。
用户转化分析
对比线下进群(地推模式)和线上拉新(全国范围的线上模式)这两种模式下的用户数、纯新用户占比、退群情况、领券和核销情况。
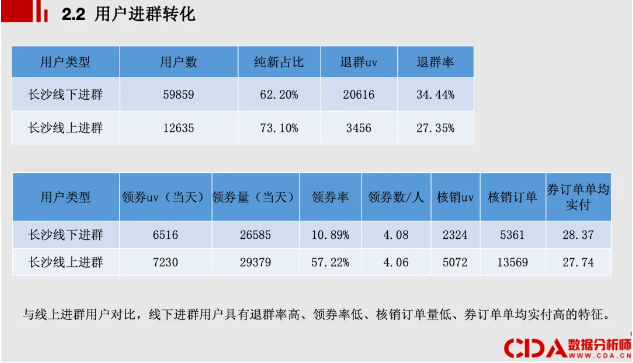
用户数:
纯新用户占比:
退群情况:
领券和核销情况:
综合来看,与线上进群用户对比,线下进群用户具有以下特征:
通过以上分析,我们可以看到,线下拉新模式虽然在用户数和退群率上表现较好,但在领券率和核销订单量上表现较差。
02 同期群分析的应用
同期群分析是一种量化行为指标的方法,通过分析不同群体在特定时间段内的行为变化,来衡量指定对象组的持续性行为差异。

在社群运营中,活跃率是一个极为重要的指标,而同期群分析能够帮助我们深入了解用户在社群中的每日活跃情况。
用户质量对比
地推模式下的用户质量并未达到预期,其退群率、领券率和核销率等关键指标均低于线上拉新模式。
具体来看:
- 退群率:地推模式的退群率较高,表明用户留存情况不佳。
- 领券率:地推模式的领券率较低,反映出用户参与度不足。
- 核销率:地推模式的核销率同样低于线上模式,说明用户转化效率较低。
这表明,尽管地推模式在用户数量上可能有优势,但从用户活跃度和转化效率来看,线上拉新模式的用户质量更高。
线上线下模式分析
同期群分析通过量化行为指标,分析不同群体在特定时间段内的行为变化,帮助我们衡量用户在社群中的活跃情况。
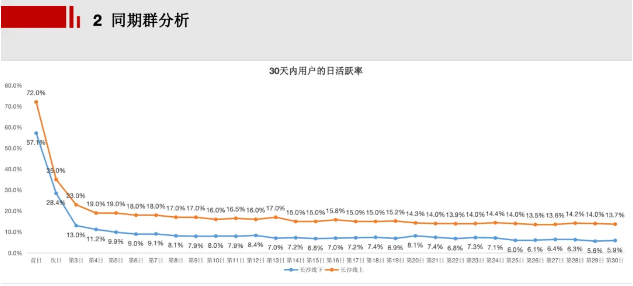
通过同期群分析,我们发现:
- 次日及后续日数:线上模式的活跃率下降较为缓慢,维持在14%左右;而地推模式的活跃率下降较快,最终维持在6%左右。
这进一步证实了线上拉新模式在用户活跃度方面的优势。
03 数据分析模型及方法
给大家介绍3种非常实用的数据分析模型:
1. 帕累托分析模型案例
帕累托分析模型基于帕累托原则(80/20法则),通过识别和聚焦于最重要的20%因素来优化资源和提升效率。
举个例子,假设我们是一家电子商务公司,想要分析造成订单延迟的原因,并使用帕累托分析模型确定最主要的问题因素。
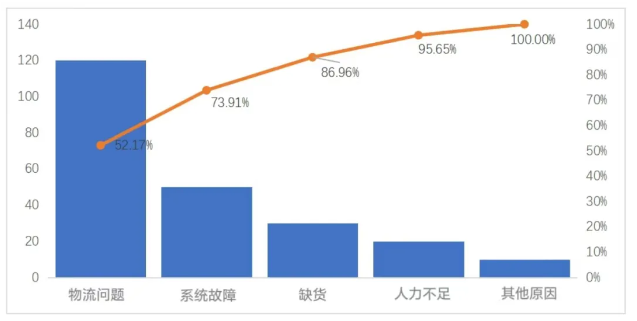
根据帕累托图,我们发现物流问题和系统故障占据了主要的比例,合计占据了约80%的订单延迟原因。因此,我们可以将重点放在解决这两个问题上,以最大程度地缩短订单的延迟时间。
在使用帕累托分析模型时,需要注意以下几点:
- 数据质量:模型的分析结果取决于数据的准确性和完整性,因此需要确保数据来源可信。
- 原因分类:对问题原因进行准确的分类是关键,避免将不同类型的原因混淆在一起造成分析失真。
- 统计偏差:有时候某些原因可能被忽视或者过度估计,需要进行合理的统计校正,以确保结果的可靠性。
2. 波士顿矩阵模型案例
波士顿矩阵模型是一种经典的产品组合分析工具,用于评估企业产品组合中各个产品的市场增长率和市场份额。

举个例子,假设我们是一家消费电子公司,拥有多款产品,现在我们来模拟数据并应用波士顿矩阵模型进行分析。
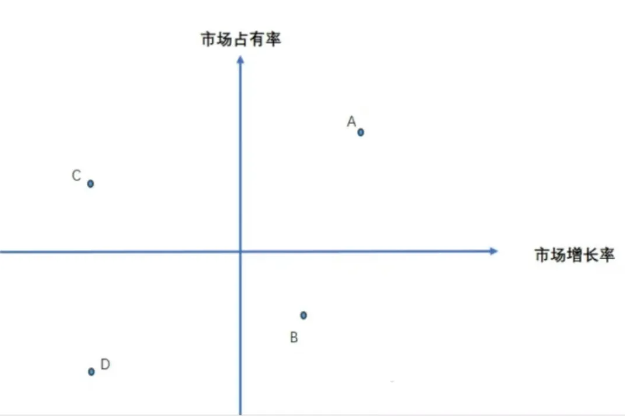
通过这张图,我们可以将各产品定位到波士顿矩阵的不同象限中。
比如:产品A定位为明星产品,产品B为问题产品, 产品C为现金牛,产品D为瘦狗产品。根据不同定位,我们可以制定相应的战略,比如加大对产品B的市场投入以提升其市场份额,优化产品C的成本结构以提高利润率等。
数据分析模型和方法有很多,在工作中可以根据实际需要灵活选择。
漏斗模型是用户行为分析中最重要的模型之一,用于跟踪用户在完成特定目标过程中的流失情况。
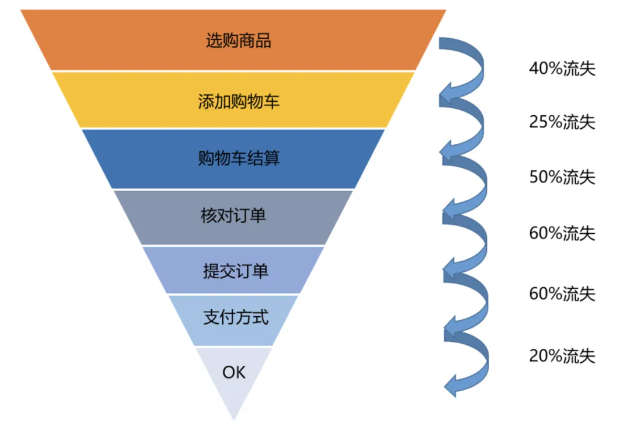
其核心步骤包括:
- 分解关键步骤:如商品浏览、加入购物车、进入支付页面等。
- 收集数据:统计每个步骤的用户数量及完成率,计算转化率。
- 提出优化建议:通过优化用户体验、简化操作流程等方式,提高转化率。
学习入口:https://edu.cda.cn/goods/show/3853?targetId=6765&preview=0
推荐学习书籍
《CDA一级教材》适合CDA一级考生备考,也适合业务及数据分析岗位的从业者提升自我。完整电子版已上线CDA网校,累计已有10万+在读~

免费加入阅读:https://edu.cda.cn/goods/show/3151?targetId=5147&preview=0











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330