朴素贝叶斯算法的python实现方法
本文实例讲述了朴素贝叶斯算法的python实现方法。分享给大家供大家参考。具体实现方法如下:
朴素贝叶斯算法优缺点
优点:在数据较少的情况下依然有效,可以处理多类别问题
缺点:对输入数据的准备方式敏感
适用数据类型:标称型数据
算法思想:
比如我们想判断一个邮件是不是垃圾邮件,那么我们知道的是这个邮件中的词的分布,那么我们还要知道:垃圾邮件中某些词的出现是多少,就可以利用贝叶斯定理得到。
朴素贝叶斯分类器中的一个假设是:每个特征同等重要
函数
loadDataSet()
创建数据集,这里的数据集是已经拆分好的单词组成的句子,表示的是某论坛的用户评论,标签1表示这个是骂人的
createVocabList(dataSet)
找出这些句子中总共有多少单词,以确定我们词向量的大小
setOfWords2Vec(vocabList, inputSet)
将句子根据其中的单词转成向量,这里用的是伯努利模型,即只考虑这个单词是否存在
bagOfWords2VecMN(vocabList, inputSet)
这个是将句子转成向量的另一种模型,多项式模型,考虑某个词的出现次数
trainNB0(trainMatrix,trainCatergory)
计算P(i)和P(w[i]|C[1])和P(w[i]|C[0]),这里有两个技巧,一个是开始的分子分母没有全部初始化为0是为了防止其中一个的概率为0导致整体为0,另一个是后面乘用对数防止因为精度问题结果为0
classifyNB(vec2Classify, p0Vec, p1Vec, pClass1)
根据贝叶斯公式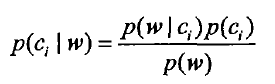 计算这个向量属于两个集合中哪个的概率高
计算这个向量属于两个集合中哪个的概率高
代码如下:
#coding=utf-8
from numpy import *
def loadDataSet():
postingList=[['my', 'dog', 'has', 'flea', 'problems', 'help', 'please'],
['maybe', 'not', 'take', 'him', 'to', 'dog', 'park', 'stupid'],
['my', 'dalmation', 'is', 'so', 'cute', 'I', 'love', 'him'],
['stop', 'posting', 'stupid', 'worthless', 'garbage'],
['mr', 'licks', 'ate', 'my', 'steak', 'how', 'to', 'stop', 'him'],
['quit', 'buying', 'worthless', 'dog', 'food', 'stupid']]
classVec = [0,1,0,1,0,1] #1 is abusive, 0 not
return postingList,classVec
#创建一个带有所有单词的列表
def createVocabList(dataSet):
vocabSet = set([])
for document in dataSet:
vocabSet = vocabSet | set(document)
return list(vocabSet)
def setOfWords2Vec(vocabList, inputSet):
retVocabList = [0] * len(vocabList)
for word in inputSet:
if word in vocabList:
retVocabList[vocabList.index(word)] = 1
else:
print 'word ',word ,'not in dict'
return retVocabList
#另一种模型
def bagOfWords2VecMN(vocabList, inputSet):
returnVec = [0]*len(vocabList)
for word in inputSet:
if word in vocabList:
returnVec[vocabList.index(word)] += 1
return returnVec
def trainNB0(trainMatrix,trainCatergory):
numTrainDoc = len(trainMatrix)
numWords = len(trainMatrix[0])
pAbusive = sum(trainCatergory)/float(numTrainDoc)
#防止多个概率的成绩当中的一个为0
p0Num = ones(numWords)
p1Num = ones(numWords)
p0Denom = 2.0
p1Denom = 2.0
for i in range(numTrainDoc):
if trainCatergory[i] == 1:
p1Num +=trainMatrix[i]
p1Denom += sum(trainMatrix[i])
else:
p0Num +=trainMatrix[i]
p0Denom += sum(trainMatrix[i])
p1Vect = log(p1Num/p1Denom)#处于精度的考虑,否则很可能到限归零
p0Vect = log(p0Num/p0Denom)
return p0Vect,p1Vect,pAbusive
def classifyNB(vec2Classify, p0Vec, p1Vec, pClass1):
p1 = sum(vec2Classify * p1Vec) + log(pClass1) #element-wise mult
p0 = sum(vec2Classify * p0Vec) + log(1.0 - pClass1)
if p1 > p0:
return 1
else:
return 0
def testingNB():
listOPosts,listClasses = loadDataSet()
myVocabList = createVocabList(listOPosts)
trainMat=[]
for postinDoc in listOPosts:
trainMat.append(setOfWords2Vec(myVocabList, postinDoc))
p0V,p1V,pAb = trainNB0(array(trainMat),array(listClasses))
testEntry = ['love', 'my', 'dalmation']
thisDoc = array(setOfWords2Vec(myVocabList, testEntry))
print testEntry,'classified as: ',classifyNB(thisDoc,p0V,p1V,pAb)
testEntry = ['stupid', 'garbage']
thisDoc = array(setOfWords2Vec(myVocabList, testEntry))
print testEntry,'classified as: ',classifyNB(thisDoc,p0V,p1V,pAb)
def main():
testingNB()
if __name__ == '__main__':
main()
希望本文所述对大家的Python程序设计有所帮助。
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330