大数据精准营销中的个性化推荐与应用
亚马逊通过个性化推荐所获取的交易额占总交易额的20%;双十一期间,天猫和淘宝通过对数据的挖掘,使用了“千人千面”的个性化推荐;阿里CEO张勇在之后的媒体沟通会上肯定赞扬了个性化推荐所取得的成绩…….。
这一切表明,个性化推荐所突显的作用越来越受到企业的重视。
何为个性化推荐?概括来说“人-场景-商品”这三个维度是人性化推荐的基础。推荐的过程就是通过寻找这三个维度之间的相关性,提供“人-场景-商品”的最佳组合。
个性化推荐可分为两类:基于内容的推荐、协同过滤推荐,下面我们来分别了解一下。
一、基于内容的推荐(Content-based Recommendations)
第一步是统计相应的内容材料,确定样本集的正例和负例。举个栗子:如果要将iphone6s 推荐给相应的客户,那么样本集正例就是那些购买过iphone6s的人,样本集负例就是那些没购买过iphone6s的人。
第二步就是引用学习算法,基于内容的推荐的学习算法主要有:Rocchio算法、决策树算法、线性分类算法、朴素贝叶斯算法、GBDT。这些学习算法都可以在网上找到相应的代码,可以根据相应的数据特点和所要应用的商业场景选择相应的学习算法。
第三步是确定模型的特征变量,这需要先为每一个item(场景下的商品)提取出相应的特征数据,并且统计样本中的人对于每一个item的特征偏好(喜欢和不喜欢),这样学习算法可以算出特征变量对于模型的卡方和增益,卡方越大,说明该特征变量对于模型样本的区分度越高,增益越大,说明该特征变量给模型带来的信息熵越高。举个栗子:对于”iphone6s目标客户“模型,有地域、收入、年龄、学历、历史购买均单价等特征变量,其中卡方的大小:收入>历史购买均单价>学历>年龄>地域,那么对于“iphone6s目标客户“模型来说,特征变量的重要性大小:收入>历史购买均单价>学历>年龄>地域。需要说明的是;选择特征变量时,要结合样本集的数据量,因为当样本集数据量过大,而特征变量太少,就会导致内容推荐模型欠拟合,当样本集数据量太少,而特征变量又多,则会导致内容推荐模型过拟合。过拟合和欠拟合都会影响推荐模型的准确性。
第四步是训练模型,可以通过调参数的方式优化模型的正确率,正确率越高,表示模型的质量越高。
简要的说:基于内容的推荐是就是通过机器学习产生相应的规则模型,然后用模型预测用户在特定场景下对商品的偏好度。
基于这样的思维方式,我们可以在各个场景下针对不同的商品构建出不同的模型,有了这些模型集,当新的用户进来,跑下各个模型,就可以判断该用户是哪个商品的目标客户,从而判断给她推荐什么商品。
二、协同过滤(Collaborative Filtering Recommendation)
第一种是基于用户的协同过滤,这种一般基于用户有足够的社会属性数据。举个栗子:用户凯文对iphone6s没有相应信息记录,那么可以(采用皮尔森系数)找到和凯文社会属性相似的晓华, 统计晓华对iPhone6s 的偏好度( 对比晓华对于所有商品的偏好度)。最后预测出凯文对于iphone6s的偏好度。
第二种是基于物品的协同过滤,这种多应用于电商业务中,再举个栗子:用户凯文对于iphone6s没有相应的信息记录,那么可以(采用余弦算法)找到和iPhone6s具有相同的产品特征的商品x, 统计凯文于商品x的偏好度(对比凯文对于所有商品的偏好度),最后预测出凯文对于iphone6s的偏好度。
协同过滤的算法主要有:皮尔森算法,杰西卡算法,余弦距离相似算法,欧式距离算法等。在此不做赘述,本文重点对个性化推荐相关分类内容进行阐述,以此抛砖引玉,期待与大家进一步深入探讨。
三、案例
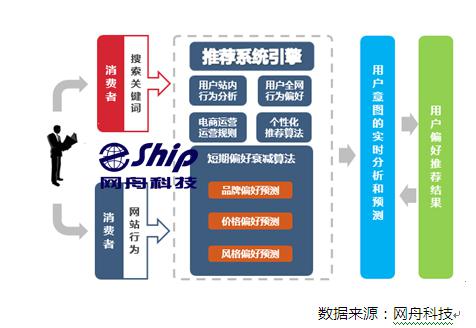
网舟科技为客户提供的个性化荐服务,通过对用户线上线下数据的聚类、关联和协同过滤,建立了不同使用场景的推荐机制,实现推荐引擎从传统的大众化推荐向差异化推荐转变,协助企业实现智能商品导购,提升了用户购买过程的体验,增加了商品的销量。通过分析大量用户行为日志,精准把握消费偏好,针对用户整个浏览过程中的各个页面,给用户提供个性化页面展示。在用户购买最佳的时间,为用户推荐最适合的商品,从而提高网站的点击率和转化率。达到拉动销售额增长,增加交叉/向上销售,提升客户满意度的效果(如图所示)。
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330