
CDA 数据分析师证书含金量几何?一文为你讲清楚 在当今数字化时代,数据成为了企业决策和发展的重要依据。数据分析师这一职业应运而生,他们能够对海量数据进行收集、整理、分析,并为企业提供有价值的决策建议。 ...
2025-06-13
CDA 数据分析师:数字化时代的关键人才 在当今数字化浪潮席卷全球的时代,数据已然成为驱动企业发展、推动行业变革的核心要素。从金融机构的风险评估,到零售企业的精准营销;从医疗行业的疾病预测,到电信领域的网 ...
2025-06-13
CDA 数据分析师报考条件全解析 在大数据和人工智能时代,数据分析师成为了众多行业追捧的热门职业。CDA(Certified Data Analyst)数据分析师认证作为一套科学化、专业化、国际化的人才考核标准,受到了广泛关注。想 ...
2025-06-13
“纲举目张,执本末从。”若想在数据分析领域有所收获,一套合适的学习教材至关重要。一套优质且契合需求的学习教材无疑是那关键的“纲”与“本”。《CDA一级教材:精益业务数据分析》严格按照考试大纲编写,既适合C ...
2025-06-09
2025 年,数据如同数字时代的 DNA,编码着人类社会的未来图景,驱动着商业时代的运转。从全球互联网用户每天产生的2.5亿TB数据,到制造业的传感器、金融交易、医疗病历等各个领域的海量信息,数据的量级每年都在呈指 ...
2025-05-27
CDA数据分析师证书考试体系(更新于2025年05月22日) CDA(Certified Data Analyst),是指在金融、电信、零售、制造、能源、医疗医药、旅游、咨询等行业从事数据的采集、清洗、处理、分析并能制作业务报告、提供数 ...
2025-05-26解码数据基因:从数字敏感度到逻辑思维 每当看到超市货架上商品的排列变化,你是否会联想到背后的销售数据波动?三年前在零售行业做运营的小李就是这样开启转型之路的。这个总爱琢磨"为什么促销活动后客单价反而下降 ...
2025-05-23
在本文中,我们将探讨 AI 为何能够加速数据分析、如何在每个步骤中实现数据分析自动化以及使用哪些工具。 数据分析中的AI是什么? 数据分析中的AI的核心是应用人工智能 (AI) 来分析大量数据。这使数据分析师和科学 ...
2025-05-20当数据遇见人生:我的第一个分析项目 记得三年前接手第一个数据分析项目时,我面对Excel里密密麻麻的销售数据手足无措。那些跳动的数字就像调皮的精灵,明明每个都认识,组合起来却读不懂它们的秘密。直到我学会用Py ...
2025-05-20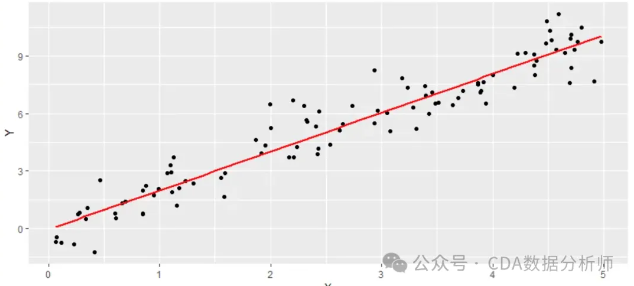
在数字化运营的时代,企业每天都在产生海量数据:用户点击行为、商品销售记录、广告投放反馈…… 这些数据就像散落的拼图,而相关性分析正是将它们拼接成完整画面的关键工具。通过量化数据间的关联程度,我们能够发 ...
2025-05-19
在当今数字化营销时代,小红书作为国内领先的社交电商平台,其销售数据蕴含着巨大的商业价值。通过对小红书销售数据的深入分析,商家可以精准把握市场动态,优化营销策略,从而提升销售业绩。 本文将详细展示小红书 ...
2025-05-16
Excel作为最常用的数据分析工具,有没有什么工具可以帮助我们快速地使用excel表格,只要轻松几步甚至输入几项指令就能搞定呢? 今天给大家介绍两种通过AI做Excel数据分析的方法,帮你快速实现整理数据、分析数据、制 ...
2025-05-15
数据,如同无形的燃料,驱动着现代社会的运转。从全球互联网用户每天产生的2.5亿TB数据,到制造业的传感器、金融交易、医疗病历等各个领域的海量信息,数据的量级每年都在呈指数级增长。 面对如 ...
2025-05-15大数据是什么_数据分析师培训 其实,现在的大数据指的并不仅仅是海量数据,更准确而言是对大数据分析的方法。传统的数据分析,是通过提出假设然后获得相应数据,最后通过数据分析来验证假设。而大数据不是 ...
2025-05-14
CDA持证人简介: 万木,CDA L1持证人,某电商中厂BI工程师 ,5年数据经验1年BI内训师,高级数据分析师,拥有丰富的行业经验。 学习入口:https://edu.cda.cn/goods/show/3878?targetId=6829&preview=0 一、电商备 ...
2025-05-13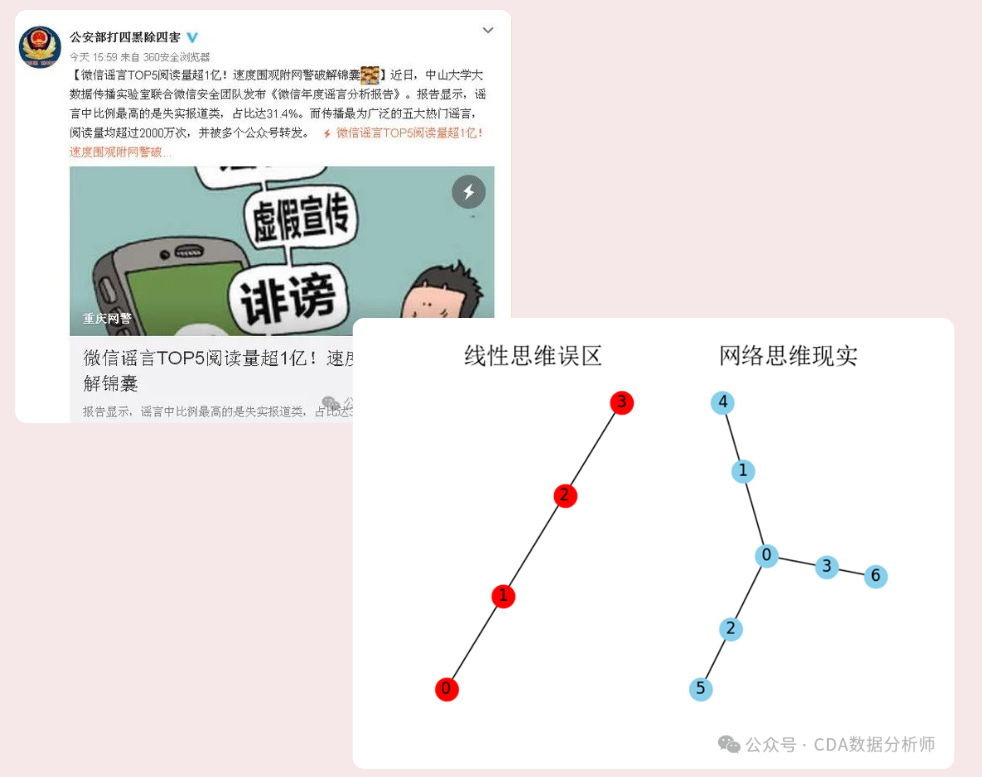
CDA持证人简介: 王明月 ,CDA 数据分析师二级持证人,2年数据产品工作经验,管理学博士在读。 学习入口:https://edu.cda.cn/goods/show/3898?targetId=6856&preview=0 一、思维模型的价值 在生活、工作和学习中 ...
2025-05-12
CDA持证人简介: 杨贞玺 ,CDA一级持证人,郑州大学情报学硕士研究生,某上市公司数据分析师。 学习入口:https://edu.cda.cn/goods/show/3893?targetId=6850&preview=0 一、智慧城市数字化应用概述 要了解智慧城 ...
2025-05-09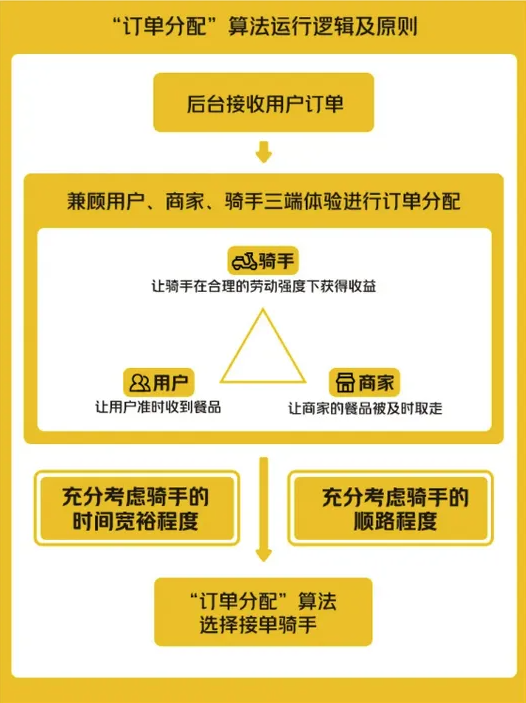
CDA持证人简介 程靖 CDA会员大咖,畅销书《小白学产品》作者,13年顶级互联网公司产品经理相关经验,曾在百度、美团、阿里等大厂担任产品经理。 学习入口:https://edu.cda.cn/goods/show/3881?targetId=6832&pre ...
2025-05-07
相信很多做数据分析的小伙伴,都接到过一些高阶的数据分析需求,实现的过程需要用到一些数据获取,数据清洗转换,建模方法等,这里面不仅要用到python,还要用到数据分析的方法论,对于只用过excel的同学来说,这无 ...
2025-05-06
以下的文章内容来源于刘静老师的专栏,如果您想阅读专栏《10大业务分析模型突破业务瓶颈》,点击下方链接 https://edu.cda.cn/goods/show/3845?targetId=6754&preview=0 一、一开始,我们都以为“用户留存差”是内 ...
2025-04-30【核心关键词】大数据、零售商、消费者、供应链、运营、企业、产品、客户、数据模型、大数据平台、数据开发、系统运维、业务逻 ...
2026-06-26在物流配送、供应链履约、终端供货等业务场景中,送货率是衡量企业履约能力、服务质量、供应链稳定性的核心业务指标,直接关联客 ...
2026-06-26 很多数据分析师精通描述性统计,能熟练计算均值、中位数、标准差,但当被问到“用500个样本如何推断10万用户的真实满意度” ...
2026-06-26在数字化管理与数据化运营体系中,指标是连接原始数据与业务决策的核心载体。零散的原始数据只是无意义的数值堆砌,无法直接反映 ...
2026-06-25在Excel数据汇总、财务统计、业务复盘等日常办公场景中,经常需要完成逐行相乘、整体汇总求和的计算需求,最典型的场景就是:单 ...
2026-06-25 很多数据分析师沉迷于复杂的机器学习算法,却忽略了数据分析最基础也最核心的能力——描述性统计。事实上,80%的商业分析问 ...
2026-06-25【核心关键词】主数据、资产、供应商、现金流、企业、精细化、集团、数字化、中国、数据质量、数据管理、经营管理、地产行业、 ...
2026-06-24在数据分析、假设检验、AB测试、学术研究等统计场景中,显著水平(α)与P值(P-value)是判断统计结果是否具有统计学意义的两个 ...
2026-06-24小李刚入职了一家互联网公司的运营部门。第一次参加业务复盘会,运营主管问了一个看似简单的问题:“这个月新用户留存率下降了5 ...
2026-06-24在数字化转型全面渗透的产业背景下,数据分析已成为互联网、金融、零售、制造等几乎所有行业的核心岗位能力。很多初学者对数据分 ...
2026-06-23在企业并购、股权定价、投融资评估、资产核算等资本市场核心场景中,市场法是应用最广泛、市场认可度最高的企业价值评估方法。传 ...
2026-06-23 许多数据分析师精通Excel函数和SQL查询,但当面对一张上万行的销售明细表,要快速回答“哪个地区销量最高”“哪款产品增长最 ...
2026-06-23【核心关键词】运营、证书、金融、客户、产品、软件、销售额、量化、科技、数据分析、金融行业、证券类软件、业务流程、金融机 ...
2026-06-22在企业方案选型、产品迭代评审、供应商筛选、运营效果复盘等决策场景中,单一指标的优劣判断往往无法支撑科学决策。一套转化效果 ...
2026-06-22 很多数据分析师掌握了Excel函数、会写SQL查询,但当被问到“数据从哪里来”“数据加工有哪些步骤”“如何使用分析工具连接数 ...
2026-06-22【核心关键词】软件、洞察力、大数据、产品、经验、硬件、流量、创新、决策、数据安全、网络安全、数据分析、决策制定、数据挖 ...
2026-06-18在方案选型、效果复盘、产品评估、供应商筛选等各类业务决策场景中,仅凭单一指标下结论往往会陷入 “以偏概全” 的误区。多维度 ...
2026-06-18 很多数据分析师精通Excel单元格操作,但当被问到“表结构数据的基本处理单位是什么”“字段和记录的本质区别”“为什么表结 ...
2026-06-18在数据分析、用户运营与业务增长的工作体系中,漏斗拆解是最基础也最高频的问题定位方法。很多业务场景下,我们只能看到最终的转 ...
2026-06-17在数据库开发、数据清洗与报表统计场景中,数值类型转换为日期是高频刚需操作。业务系统常以 Unix 时间戳、整型日期(如20240617 ...
2026-06-17





