神经网络隐藏层神经元个数的确定方法与实践
摘要
在神经网络模型设计中,隐藏层神经元个数的确定是影响模型性能、训练效率与泛化能力的关键环节。本文从神经网络的基础结构出发,系统梳理隐藏层神经元个数确定的核心方法,包括经验公式法、实验调整法、自适应优化法等,结合不同任务场景分析影响神经元个数选择的关键因素,并通过实际案例验证方法的有效性,同时指出常见认知误区,为工程师与研究者提供可落地的神经元个数设计指南。
一、引言:隐藏层与神经元个数的核心意义
1.1 神经网络的基本结构
典型的神经网络由输入层、隐藏层与输出层构成。输入层负责接收原始数据(如图像像素、文本特征),输出层输出模型预测结果(如分类标签、回归值),而隐藏层则通过非线性变换提取数据的深层特征 —— 这一 “特征提取” 能力的强弱,直接取决于隐藏层的层数与每层神经元的个数。
1.2 神经元个数的关键影响
隐藏层神经元个数的选择存在 “Goldilocks 困境”:
个数过少:模型表达能力不足,无法捕捉数据中的复杂规律,易出现 “欠拟合”,表现为训练集与测试集误差均较高;
个数过多:模型复杂度超出数据需求,易记忆训练集中的噪声,导致 “过拟合”,表现为训练集误差低但测试集误差骤升;
个数不合理:还会增加训练时间(如参数更新次数增多、梯度消失风险上升),浪费计算资源(如内存占用过高)。
因此,科学确定隐藏层神经元个数,是平衡模型性能、效率与泛化能力的核心前提。
二、隐藏层神经元个数确定的核心方法
2.1 经验公式法:快速估算初始值
经验公式基于输入层、输出层神经元个数与数据特性,为隐藏层神经元个数提供初始参考范围,适用于模型设计的初步阶段。以下为工业界常用公式及适用场景:
| 经验公式 |
公式表达式(为隐藏层神经元个数,为输入层个数,为输出层个数,为样本数量) |
适用场景 |
优缺点 |
| 基础比例法 |
(为 1-10 的调整系数) |
简单任务(如线性分类、小规模回归) |
计算简单,适合快速初始化;忽略数据复杂度,精度有限 |
| 数据规模法 |
或 |
样本量较小()的场景 |
考虑数据量对泛化能力的影响;样本量过大时估算值偏保守 |
| 复杂度适配法 |
或 |
中等复杂度任务(如文本分类、简单图像识别) |
平衡输入输出层影响,适配多数传统机器学习任务;对深度学习复杂任务适用性弱 |
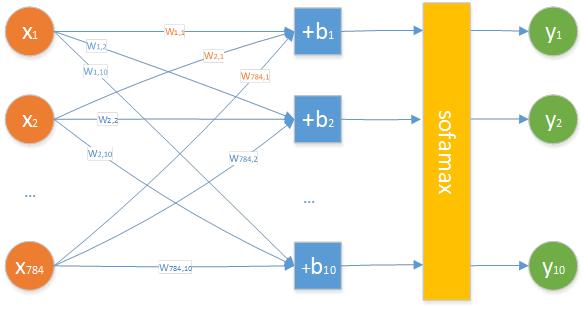
注意:经验公式的结果仅为 “初始值”,需结合后续实验调整,不可直接作为最终值。例如,在手写数字识别任务中(输入层 784 个神经元,输出层 10 个),按基础比例法计算得 ,可将 80-100 作为神经元个数的初始搜索范围。
2.2 实验调整法:迭代优化最优值
实验调整法通过 “控制变量 + 性能验证” 的方式,在经验公式的基础上找到最优神经元个数,是工业界最常用的落地方法,核心步骤如下:
2.2.1 确定搜索范围与步长
以经验公式估算值为中心,设定合理的搜索范围(如估算值 ±50%)与步长(如步长为 10 或 20,避免搜索效率过低)。例如,若初始估算值为 80,可设定搜索范围为 40-120,步长为 20。
2.2.2 交叉验证与性能评估
对每个候选神经元个数,采用 k 折交叉验证(通常 k=5 或 10)训练模型,评估指标需覆盖 “拟合程度”(如训练集准确率、MSE)与 “泛化能力”(如测试集准确率、交叉验证均值),同时记录训练时间与内存占用。
2.2.3 确定最优值
绘制 “神经元个数 - 性能指标” 曲线,选择 “测试集性能最高、训练效率可接受” 的点作为最优值。例如,在某文本分类任务中,当神经元个数从 40 增至 80 时,测试集 F1 分数从 0.82 升至 0.89;继续增至 120 时,F1 分数仅提升 0.01,但训练时间增加 40%,此时 80 即为最优值。
2.3 自适应优化法:智能化搜索
随着自动机器学习(AutoML)的发展,自适应优化法通过算法自动搜索最优神经元个数,减少人工干预,适用于复杂模型(如深度神经网络、Transformer 子网络):
2.3.1 网格搜索与随机搜索
网格搜索:遍历预设的所有神经元个数组合(如隐藏层 1:[60,80,100],隐藏层 2:[30,40,50]),适合小范围精细搜索;
随机搜索:在搜索范围内随机采样候选值,适合大范围快速探索,实验表明其在高维空间中效率优于网格搜索。
基于贝叶斯定理构建 “神经元个数 - 性能” 的概率模型,每次迭代根据历史实验结果,优先选择 “可能带来性能提升” 的候选值,大幅减少搜索次数。例如,在 CNN 图像分类任务中,贝叶斯优化可将神经元个数搜索次数从 50 次降至 15 次,同时找到更优值。
2.3.3 进化算法
模拟生物进化过程(选择、交叉、变异),将神经元个数作为 “基因” 构建种群,通过多代迭代筛选出性能最优的 “个体”。该方法适用于多隐藏层模型,可同时优化各层神经元个数(如隐藏层 1 与隐藏层 2 的个数组合)。
三、影响神经元个数选择的关键因素
3.1 数据特性
数据维度:高维数据(如高清图像、长文本)需更多神经元捕捉特征,例如 224×224 图像的输入层(50176 个神经元)对应的隐藏层个数,通常比 28×28 图像(784 个神经元)多 2-3 倍;
数据质量:噪声多、标注稀疏的数据,需减少神经元个数以避免过拟合,可配合 Dropout 等正则化方法;
数据分布:非结构化数据(如语音、视频)比结构化数据(如表格数据)需更多神经元,因前者特征提取难度更高。
3.2 任务类型
分类任务:类别数越多,输出层个数越多,隐藏层个数需相应增加(如 100 类分类任务比 10 类任务的隐藏层个数多 30%-50%);
回归任务:输出值精度要求越高,隐藏层个数需适当增加,但需控制复杂度以避免过拟合;
生成任务(如 GAN、VAE):需更多神经元构建复杂的生成模型,例如 GAN 的生成器隐藏层神经元个数通常比判别器多 50% 以上。
3.3 网络架构
隐藏层层数:多层隐藏层(深度网络)可减少单层神经元个数,例如 “2 层隐藏层(各 80 个神经元)” 的性能可能优于 “1 层隐藏层(160 个神经元)”,且更易训练;
特殊层设计:含卷积层、池化层的 CNN,全连接隐藏层的神经元个数可大幅减少(因卷积层已完成特征降维);含注意力机制的 Transformer,隐藏层神经元个数需与注意力头数匹配(如头数为 8 时,神经元个数通常为 512 或 1024,需被 8 整除)。
若采用强正则化方法(如 Dropout 率 0.5、L2 正则化系数较大),可适当增加神经元个数 —— 正则化可抑制过拟合,而更多神经元能提升模型表达能力。例如,在使用 Dropout 的文本分类任务中,隐藏层神经元个数可从 80 增至 120,且无明显过拟合。
四、实际案例:手写数字识别任务的神经元个数确定
4.1 任务背景
数据集:MNIST(60000 张训练图、10000 张测试图,每张 28×28 像素,输入层 784 个神经元,输出层 10 个神经元);
模型:2 层全连接神经网络(隐藏层 1 + 隐藏层 2);
目标:确定两层隐藏层的最优神经元个数,使测试集准确率≥98%,训练时间≤30 分钟。
4.2 步骤 1:经验公式估算初始范围
隐藏层 1 初始值:按基础比例法 ,设定范围 60-120;
隐藏层 2 初始值:按数据规模法 (因多层网络可减少单层个数,调整为 40-80)。
4.3 步骤 2:贝叶斯优化搜索
采用贝叶斯优化工具(如 Hyperopt),以 “测试集准确率” 为目标函数,搜索范围:H1∈[60,120],H2∈[40,80],迭代 15 次。
4.4 步骤 3:结果分析与最优值确定
| 隐藏层 1 个数 |
隐藏层 2 个数 |
测试集准确率 |
训练时间 |
结论 |
| 80 |
60 |
98.2% |
22 分钟 |
准确率达标,时间最优 |
| 100 |
70 |
98.3% |
28 分钟 |
准确率略高,时间接近上限 |
| 120 |
80 |
98.3% |
35 分钟 |
准确率无提升,时间超上限 |
最终选择 “隐藏层 1:80 个,隐藏层 2:60 个”,满足性能与效率需求。
五、常见认知误区与规避策略
5.1 误区 1:神经元个数越多,模型性能越好
规避策略:以 “测试集性能” 而非 “训练集性能” 为核心指标,当神经元个数增加但测试集性能无提升时,立即停止增加;配合正则化方法,平衡表达能力与泛化能力。
5.2 误区 2:所有隐藏层神经元个数必须相同
规避策略:根据 “特征提取逻辑” 设计不同层数的神经元个数 —— 通常隐藏层从输入到输出呈 “递减” 趋势(如 784→80→60→10),因深层网络需逐步压缩特征维度,减少冗余信息。
5.3 误区 3:忽略硬件资源限制
规避策略:在确定搜索范围时,先计算参数总量(每个神经元的参数 = 输入维度 + 1,如 80 个神经元的参数 = 784+1=785),确保参数总量不超过硬件内存(如 GPU 内存 8GB 时,参数总量≤1e8)。
六、未来发展趋势
随着大模型与自适应架构的兴起,隐藏层神经元个数的确定正从 “人工设计” 向 “自动优化” 演进:
动态架构模型(如 Dynamic Neural Networks)可根据输入数据实时调整神经元个数,避免固定结构的局限性;
预训练模型(如 BERT、ResNet)通过海量数据学习到最优的神经元个数配置,微调阶段仅需小幅调整,减少设计成本;
多目标优化算法(如兼顾准确率、速度、能耗)将成为神经元个数确定的核心方向,适配边缘设备等资源受限场景。
七、结论
隐藏层神经元个数的确定并非 “一刀切” 的固定规则,而是 “理论指导 + 实验验证 + 场景适配” 的迭代过程:首先通过经验公式确定初始范围,再通过实验调整或自适应优化找到最优值,最终结合数据特性、任务需求与硬件资源验证有效性。未来,随着自动机器学习技术的成熟,神经元个数的设计将更高效、更智能,但工程师仍需理解其核心逻辑,才能在复杂场景中做出合理决策。
参考文献
[1] Bishop C M. Pattern Recognition and Machine Learning [M]. Springer, 2006.(经典教材,系统阐述神经网络结构设计原理)
[2] Bergstra J, Bengio Y. Random Search for Hyper-Parameter Optimization [J]. Journal of Machine Learning Research, 2012.(随机搜索在超参数优化中的应用)
[3] Snoek J, Larochelle H, Adams R P. Practical Bayesian Optimization of Machine Learning Algorithms [C]. NeurIPS, 2012.(贝叶斯优化的经典论文)
推荐学习书籍 《CDA一级教材》适合CDA一级考生备考,也适合业务及数据分析岗位的从业者提升自我。完整电子版已上线CDA网校,累计已有10万+在读~ !












 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330