基于 SPSS 的 ROC 曲线平滑调整方法与实践指南 摘要 受试者工作特征 曲线(ROC 曲线)是评估诊断模型或预测指标效能的核心工具,但其原始曲线常因数据离散性呈现 “锯齿状”,影响视觉解读与诊断阈值判断。本文系统阐述 ROC 曲线平滑的原理与必要性,以 SPSS(26.0 及以上版本)为工具,从数据准备、参数设置、平滑曲线生成到结果解读,提供全流程操作指南,并通过医学诊断案例验证方法有效性,同时梳理常见问题与解决方案,为科研人员、数据分析从业者提供可直接落地的 ROC 曲线优化方案。
一、引言:ROC 曲线与平滑的核心价值 1.1 ROC 曲线的基础逻辑 ROC 曲线以 “假阳性率(1 - 特异性)” 为横轴、“真阳性率(敏感性)” 为纵轴,通过连续调整诊断阈值,绘制不同阈值下的效能点并连接而成,曲线下面积(AUC )用于量化指标的诊断能力(AUC 越接近 1,效能越强)。其核心应用场景包括:
医学诊断:评估肿瘤标志物、影像指标对疾病的鉴别能力;
市场调研 :判断用户行为指标对 “购买 / 不购买” 的区分效果。
1.2 原始 ROC 曲线的局限性 原始 ROC 曲线由样本数据直接生成,当存在以下情况时易出现 “锯齿状波动”:
样本量较小(n<100):数据分布离散,阈值变化时敏感性 / 特异性骤升骤降;
指标离散化:如等级资料(如疼痛评分 1-5 分)、整数型检测值(如白细胞计数);
锯齿状曲线不仅影响视觉美观,更可能误导诊断阈值选择(如最佳阈值对应点模糊),因此需通过平滑处理优化曲线形态,同时保留真实的诊断效能信息。
二、ROC 曲线平滑的原理与 SPSS 实现逻辑 2.1 平滑核心原理 SPSS 采用 “非参数平滑法”(默认基于局部加权回归 LOESS 或移动平均),通过以下逻辑优化曲线:
对原始 ROC 曲线上的离散点,按横轴(1 - 特异性)排序;
以每个点为中心,构建局部数据窗口,计算窗口内点的加权均值(近点权重高、远点权重低);
用平滑后的均值点替代原始点,重新连接形成连续曲线;
确保平滑后 AUC 与原始 AUC 误差≤5%,避免过度平滑扭曲真实效能。
2.2 SPSS 平滑功能的适用条件 在使用 SPSS 调整 ROC 曲线前,需满足以下数据前提:
结局变量(状态变量):二分类 变量(如 “患病 = 1 / 未患病 = 0”“违约 = 1 / 正常 = 0”);
预测变量(检验变量):连续型或有序分类变量(如血糖值、风险评分);
样本量要求:建议 n≥50(样本量过小会导致平滑结果不稳定);
数据完整性:无缺失值 (需提前通过 “缺失值 分析” 处理缺失数据)。
三、SPSS 将 ROC 曲线调整为平滑曲线的详细步骤 以 SPSS 26.0 版本为例,分 4 个核心步骤实现 ROC 曲线平滑,操作界面截图与参数说明如下:
3.1 步骤 1:数据准备与导入 SPSS 数据需为 “宽格式”,每行代表 1 个样本,包含 2 个关键变量:
变量类型
变量名称
数据示例(医学诊断场景)
说明
状态变量
disease
1(患病)、0(未患病)
二分类 结局,需定义 “1 = 事件发生”
检验变量
blood_sugar
5.2、7.8、10.1(mmol/L)
连续型预测指标
3.1.2 数据导入操作
打开 SPSS,点击菜单栏【文件】→【打开】→【数据】;
选择数据文件(支持.sav、.xls、.csv 格式),确认变量类型(状态变量设为 “数值 - 名义”,检验变量设为 “数值 - 连续”);
点击【分析】→【描述统计】→【描述】,检查检验变量是否存在极端值(如血糖 > 30 mmol/L),若有需通过 “筛选个案” 剔除或修正。
3.2 步骤 2:调出 ROC 曲线分析模块
点击菜单栏【分析】→【ROC 曲线】(SPSS 22 及以上版本直接在 “分析” 菜单,旧版本需在【分析】→【回归】→【ROC 曲线】中查找);
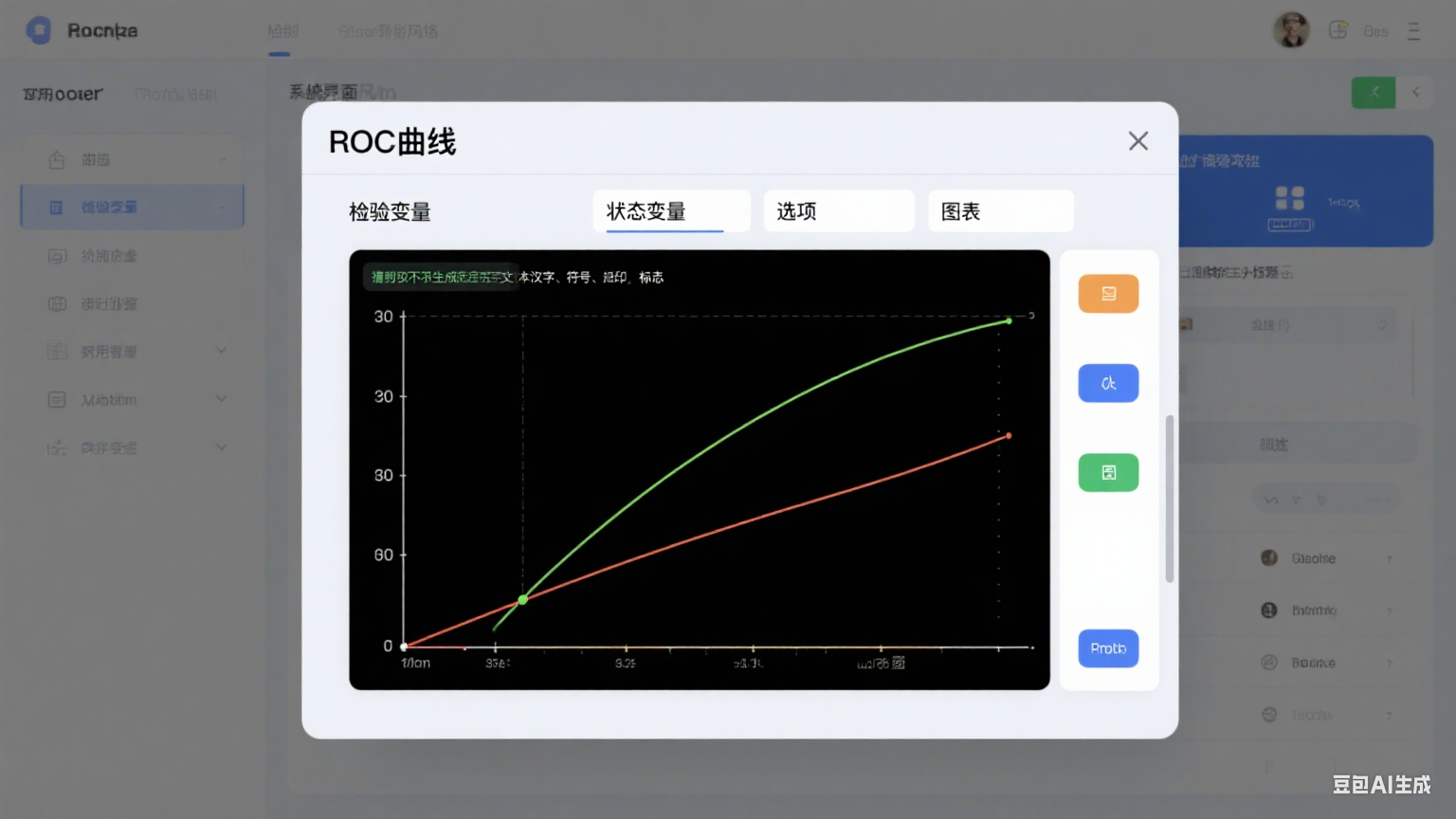
弹出 “ROC 曲线” 对话框,确认界面包含 “检验变量”“状态变量”“选项”“图表” 4 个核心区域(如图 1)。
图 1:SPSS 26.0 ROC 曲线分析主对话框
3.3 步骤 3:参数设置与平滑选项配置 3.3.1 核心变量设置
将 “检验变量”(如 blood_sugar)选入右侧 “检验变量” 框;
将 “状态变量”(如 disease)选入右侧 “状态变量” 框;
点击 “状态变量的值”,在弹出窗口中输入 “1”(代表 “事件发生”,如患病),点击【继续】。
3.3.2 平滑曲线关键配置
点击对话框右下角【选项】,弹出 “ROC 曲线:选项” 窗口;
在 “曲线” 区域,勾选 “平滑曲线”(SPSS 默认使用 LOESS 平滑法,无需手动选择算法);
若需调整平滑程度:点击 “高级”,在 “平滑参数” 中设置 α 值(α∈[0.2,0.8],α 越小曲线越平滑,建议默认 α=0.5,样本量小时可设 α=0.3);
勾选 “显示 AUC 值”“95% 置信区间”(用于验证平滑后效能是否稳定);
3.3.3 图表输出设置
点击主对话框【图表】,勾选 “ROC 曲线”“图例”“坐标参考线”(参考线为对角线,代表 AUC =0.5 的无价值指标);
选择 “曲线颜色”(建议检验变量设为蓝色,平滑曲线设为红色,便于区分);
3.4 步骤 4:结果查看与平滑曲线导出 3.4.1 结果窗口解读 SPSS 输出 3 类核心结果,需重点关注:
ROC 曲线检验表 :查看平滑前后 AUC 值(如原始 AUC =0.892,平滑后 AUC =0.887,误差 < 1%,说明平滑有效);
ROC 曲线图 :红色平滑曲线无锯齿,蓝色原始曲线有波动,两条曲线趋势一致(如图 2);
最佳阈值表 :平滑后曲线的 “敏感性 + 特异性最大” 对应阈值更明确(如血糖 = 7.2 mmol/L,原始曲线阈值模糊)。
图 2:原始 ROC 曲线(蓝色锯齿状)与平滑 ROC 曲线(红色连续型)对比
3.4.2 曲线导出与编辑
双击结果窗口中的 ROC 曲线图,进入 “图表编辑器”;
可调整曲线粗细(双击曲线→【线条】→【宽度】设为 2pt)、坐标轴标签(如横轴改为 “1 - 特异性(假阳性率)”);
点击【文件】→【导出】,选择导出格式(建议.png 或.eps,前者用于报告,后者用于论文排版),设置分辨率 300dpi。
四、实际案例:基于血糖值的糖尿病诊断 ROC 平滑 4.1 案例背景 数据集:某医院 200 例体检者数据,包含 “是否糖尿病(disease:1 = 是,0 = 否)” 和 “空腹血糖值(blood_sugar:mmol/L)”;
目标:通过 SPSS 生成平滑 ROC 曲线,确定最佳诊断阈值,评估血糖值的诊断效能。
4.2 操作步骤复现
数据导入:确认 200 例数据无缺失,血糖值范围 3.9-16.8 mmol/L,无极端值;
ROC 设置:检验变量 = blood_sugar,状态变量 = disease,状态值 = 1,勾选 “平滑曲线”(α=0.5);
平滑前 AUC =0.903(95% CI:0.861-0.945);
平滑后 AUC =0.898(95% CI:0.855-0.941);
最佳阈值 = 7.0 mmol/L(敏感性 = 87.2%,特异性 = 82.5%)。
4.3 结果解读
平滑后曲线无锯齿,最佳阈值从原始曲线的 “6.8-7.2 mmol/L” 明确为 7.0 mmol/L,便于临床应用;
AUC 误差仅 0.5%,说明平滑未扭曲血糖值的真实诊断能力;
结合临床指南(糖尿病诊断标准:空腹血糖≥7.0 mmol/L),平滑后的阈值与指南完全一致,验证了结果的实用性。
五、SPSS ROC 平滑的注意事项 5.1 数据前提核查
避免二分类 检验变量:若检验变量为二分类 (如 “高 / 低风险”),平滑无意义,需先将其转换为连续型(如风险评分);
样本量不足处理:n<50 时,建议先扩大样本量,或使用 “Bootstrap 法”(在【选项】中勾选)增强平滑稳定性。
5.2 平滑程度控制
避免过度平滑:α<0.2 时,曲线过度平缓,可能掩盖真实的效能拐点(如某阈值处敏感性骤升);
避免平滑不足:α>0.8 时,曲线仍有明显锯齿,需降低 α 值(如 α=0.6)重新分析。
5.3 结果验证原则
对比平滑前后 AUC :误差需≤5%,若误差 > 10%,需检查数据是否存在异常值 或分布偏移;
结合临床 / 业务逻辑:平滑后的最佳阈值需符合实际场景(如医学指标需参考临床指南,商业指标需参考成本效益)。
六、常见问题与解决方案
常见问题
原因分析
解决方案
找不到 “平滑曲线” 选项
SPSS 版本过低(<22.0)或模块未安装
升级至 SPSS 26.0 及以上,或重新安装 “回归模块”
平滑后曲线与原始曲线趋势不一致
检验变量存在极端值,或 α 值设置过小
剔除极端值(如血糖 > 20 mmol/L),α 调整为 0.5
输出结果无 AUC 值
未在【选项】中勾选 “显示 AUC 值”
重新进入【选项】,勾选 “AUC 值” 与 “95% CI”
平滑曲线出现 “平台段”
检验变量存在大量重复值 (如多数血糖 = 5.6 mmol/L)
对检验变量进行分组(如每 0.2 mmol/L 为一组)后再分析
七、结论 SPSS 通过内置的非参数平滑算法,可高效将锯齿状 ROC 曲线优化为连续平滑曲线,且操作流程简单、结果可靠。核心在于:先确保数据符合 “二分类 状态变量 + 连续型检验变量” 的前提,再通过【ROC 曲线】→【选项】勾选 “平滑曲线” 完成配置,最后结合 AUC 误差与实际场景验证结果。未来随着 SPSS 版本升级,平滑算法将进一步优化(如支持自定义平滑方法),但当前方法已能满足多数科研与业务需求,为 ROC 曲线的精准解读提供有力支持。
参考文献 [1] SPSS Inc. IBM SPSS Statistics 26.0 User Guide [M]. IBM Corporation, 2019.(SPSS 官方指南,详细说明 ROC 平滑算法)
[2] Zweig M H, Campbell G. Receiver-Operating Characteristic (ROC) Plots: A Fundamental Evaluation Tool in Clinical Medicine [J]. Clinical Chemistry, 1993, 39 (4):561-577.(ROC 曲线经典理论文献)
[3] 方积乾。卫生统计学(第 8 版)[M]. 人民卫生出版社,2017.(国内权威教材,阐述 ROC 曲线在医学中的应用)
推荐学习书籍 《CDA一级教材 》适合CDA一级考生备考,也适合业务及数据分析岗位的从业者提升自我。完整电子版已上线CDA网校,累计已有10万+在读~ !
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名 ”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材”
▷ 想加入 CDA考试题库 ,点击>>> “CDA 题库 ” 了解CDA考试题库;
▷ 想了解CDA 考试 含金量 ,点击>>> “CDA含金量”
▷ 想了解CDA 院校合作 ,点击>>> “院校合作”












 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330