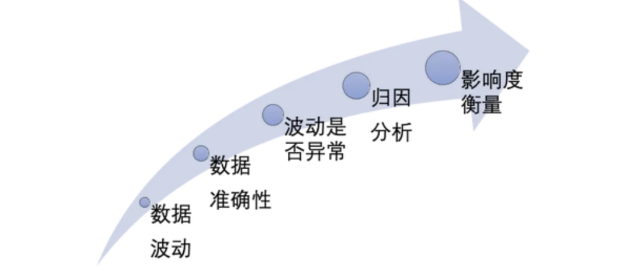
在当今这个数据驱动的时代,几乎每一个业务决策都离不开对数据的深入分析。而其中,指标波动归因分析 更是至关重要的一环。无论是电商的销售额、金融市场的股价变动,还是医疗健康领域的患者数据变化,数据指标的波动都能反映出业务发展的健康状况和潜在风险。然而,面对复杂多变的数据波动,如何准确地识别和分析异常波动,成为了许多企业和数据分析师面临的难题。
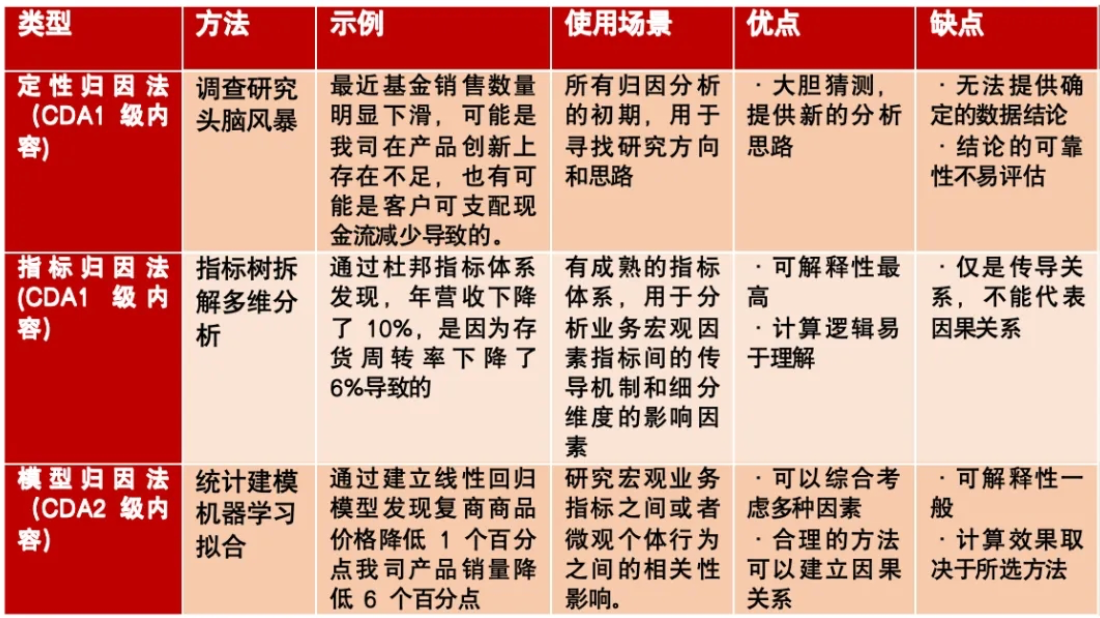
一、归因分析的重要性 归因分析(Attribution Analysis)也称为根本原因分析(RCA,Root Cause Analysis),是一种评估不同因素对结果影响大小的方法。其目的在于识别和评估影响结果的各个因素,以便更好地理解这些因素的作用,并据此做出决策。这种分析方法在市场营销、社会科学、心理学等领域有广泛的应用,尤其在评估营销渠道效果、广告投放优化、用户行为分析等方面发挥着重要作用。根据分析技术的复杂度,分为定性归因法、指标归因法、模型归因法 。
首先,通过数据指标波动我们可以及时发现业务中的异常情况,从而采取相应的措施进行调整。其次,通过对指标归因分析,我们可以更好地预测未来的趋势,为战略决策提供依据。最后,指标归因分析还能帮助我们优化业务流程,提高运营效率。
业务数据分析是CDA数据分析师一级的重点 ,一级新教材《商业数据分析》第五章重深入讲解了归因分析的方法和应用,帮助你更好地理解和应对数据波动,提升业务表现。
二、数据指标归因分析的方法 1、定性归因法:头脑风暴 头脑风暴是指一群人发散性地思考问题,围绕一个特定的兴趣领域产生新观点的时候,这种情境就叫做头脑风暴。头脑风暴的核心是发挥人的创造性思维能力,针对一个给定的问题,在产生尽可能多的好想法方面。在归因分析中,头脑风暴不是一个单一的、定义明确的活动,往往根据个人经验或风格做调整。
头脑风暴有两类不同的形式:结构化的头脑风暴和非结构化的头脑风暴 。除了提出问题的顺序不一致外,这两种方法完全相同。
2、指标归因法:价值树分析和多维分析 指标归因法分析是通过指标间的相互作用关系定位业务问题点的方法。指标归因用在定位根因的分析中,通常需要借助业务价值树来对指标进行拆解,形成指标树。
例如,发现某企业出现了净利润下滑,明确目标指标为:净利润 。为了找到造成这种结果的原因,就可以通过上图所示的指标拆解形成指标树来展开。
根据净利润的价值树梳理,可以了解到影响净利润的主要指标是净利润下层的营业收入、营业成本、期间费用、营业外支出、所得税 这5个指标。通过计算各个指标值并对比各个指标值的同环比变化情况,可以进一步确定期间费用发生显著的增长。
继续按照价值流梳理拆解指标,期间费用由销售费用、管理费用、财务费用构成 ,其中管理费用环比增长显著增加,其他费用基本持平;在对管理费用进行下钻,从区域维度来统计各个地区的管理费用,发现区域A的管理费用环比增涨了 500%,其他区域持平,所以区域A管理费用就是造成净利润下滑的“主因”。找到“因”后就将管理费用激增带入到区域A的业务场景中,从业务视角理解该项费用激增的业务逻辑,并制定针对性方案。
3、模型归因法 模型归因法主要是通过算法建立数据统计 模型来做归因分析,即以解释指标为自变量,目标指标为因变量做回归预测,并计算每个解释变量的影响程度。如在统计建模 和机器学习 的模型中,常见的方法有:线性回归 、逻辑回归 、决策树
三、归因分析案例 为了更好地理解数据指标归因分析方法,我们通过一个实际案例来进行详细分析。假设我们是一家电商平台,需要对每日销售额的波动 进行归因分析。
首先,我们需要收集过去一年的每日销售额数据。数据收集完成后,进行预处理,包括缺失值 处理、异常值 处理和数据标准 化等步骤。
接下来,我们进行描述性统计分析 。计算每日销售额的均值、中位数、标准差 等统计量 ,初步了解数据的整体特征 。
import pandas as pdimport numpy as np'daily_sales.csv' )'sales' ].mean()'sales' ].median()'sales' ].std()f'均值: {mean_sales} ' )f'中位数: {median_sales} ' )f'标准差 : {std_sales} ' )通过时间序列分析 ,我们可以识别出销售额的趋势、季节性和周期性成分。
使用简单移动平均法平滑数据,消除短期波动,揭示长期趋势。
import matplotlib .pyplot as plt'moving_avg' ] = data['sales' ].rolling(window=7 ).mean()使用经典分解法将销售额分解为趋势成分、季节成分和随机成分。
from statsmodels.tsa.seasonal import seasonal_decompose'sales' ], model='additive' , period=7 )使用ARIMA模型 对销售额进行预测。
from statsmodels.tsa.arima.model import ARIMA'sales' ], order=(5 , 1 , 0 ))30 )通过回归分析 研究广告投入对销售额的影响。
'ad_spending.csv' )'date' )import statsmodels.api as sm'ad_spending' ]'sales' ]使用基于统计的方法识别销售额中的异常值 。
3 * std_sales3 * std_sales'sales' ] < lower_bound) | (data['sales' ] > upper_bound)]四、数据指标归因分析面临的问题 尽管数据指标归因分析有许多成熟的方法,但在实际应用中仍面临一些问题。
数据的质量直接影响分析结果的准确性。因此,在进行归因分析之前,必须对数据进行严格的预处理,包括缺失值 处理、异常值 处理和数据标准 化等步骤。
2、复杂的因果关系 在某些情况下,数据指标的波动可能受到多种因素的共同影响,导致因果关系复杂。此时,需要借助高级的因果分析方法,如结构方程模型,来揭示各因素之间的相互作用。
五、拓展技术方向 随着大数据和人工智能技术的发展,数据指标归因分析的方法也在不断进步。未来,以下几个方向值得关注:
1、自动化分析工具 开发更加智能的自动化分析工具,能够自动识别数据中的波动模式,并生成详细的分析报告。这将大大减轻数据分析师的工作负担,提高分析效率。
2、实时分析 随着物联网和边缘计算技术的发展,实时数据采集 和分析成为可能。通过实时分析,可以及时发现和处理数据中的指标异常,避免潜在的风险。
3、跨领域融合 将数据指标归因分析与其他领域的技术相结合,如自然语言处理 、图像识别 等,可以挖掘更多有价值的信息。例如,通过分析社交媒体上的用户评论,可以预测产品销量的变化趋势。
在当今数字化时代,数据成为了企业决策的重要依据。然而,如何从海量数据中提炼出有价值的洞察,成为了一项挑战。数据指标归因分析,作为数据驱动决策的重要工具,正在帮助企业揭开数据背后隐藏的秘密。它不仅能够帮助企业理解用户行为,还能为营销策略的优化提供有力支持,优化营销策略,提升用户体验。随着技术的不断进步,归因分析将变得更加智能和高效。
抓住机遇,狠狠提升自己 随着各行各业进行数字化转型,数据分析能力已经成了职场的刚需能力,这也是这两年CDA数据分析师大火的原因。和领导提建议再说“我感觉”“我觉得”,自己都觉得心虚,如果说“数据分析发现……”,肯定更有说服力。想在职场精进一步还是要学习数据分析的,统计学、概率论 、商业模型、SQL ,Python还是要会一些,能让你工作效率提升不少。备考CDA数据分析师的过程就是个自我提升的过程。
CDA 考试官方报名入口:https://www.cdaglobal.com/pinggu.html














 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330