量化投资如何应用到机器学习系列(一)
有一些单纯搞计算机、数学或者物理的人会问,究竟怎么样应用
ML
在量化投资。他们能做些什么自己擅长的工作。虽然在很多平台或者自媒体有谈及有关的问题,但是不够全面和完整。从今日起,量化投资与机器学习公众号将推出一个系列【机器学习该如何应用到】。编辑部花了很长时间,采访和咨询了很多研究人员。希望各位读者有所收获,如有不足,欢迎批评指正。
一、什么是机器学习
机械的定义避开不谈,回答也不追求全面准确。明确一点,机器学习的主要目的在于发现规律或重现规律。(此处不谈非监督学习、强化学习,也不谈降维、集成算法)。什么是发现规律?譬如将决策树应用于多因子模型,试图从样本数据中找出具有较高收益的因子组合。什么是重现规律?譬如,拿来一篮子股票的样本(“训练样本”),假定当中y的值(连续值为回归、离散值为分类)与x1,x2,...,xn之间一些规律,那么我们用一个模型去学习这个规律,目的是使得这个模型应用于训练样本时误差最小,那么,当下一次出现一只新的股票,希望通过此模型预测这只股票未来的表现。而这个预测的原理是从训练样本中(过去的样本)学习得到的。
二、为什么机器学习重要
在传统的技术分析、量化投资中的具有业务背景的机理模型当中,举两个例子:
■ 例子1:前段时间比较火的《跟踪聪明钱-从分钟线到选股因子》,作者认为聪明钱应该“订单报价更激烈”,因此构造一个指标衡量聪明程度,利用这个指标的确定投资策略。
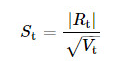
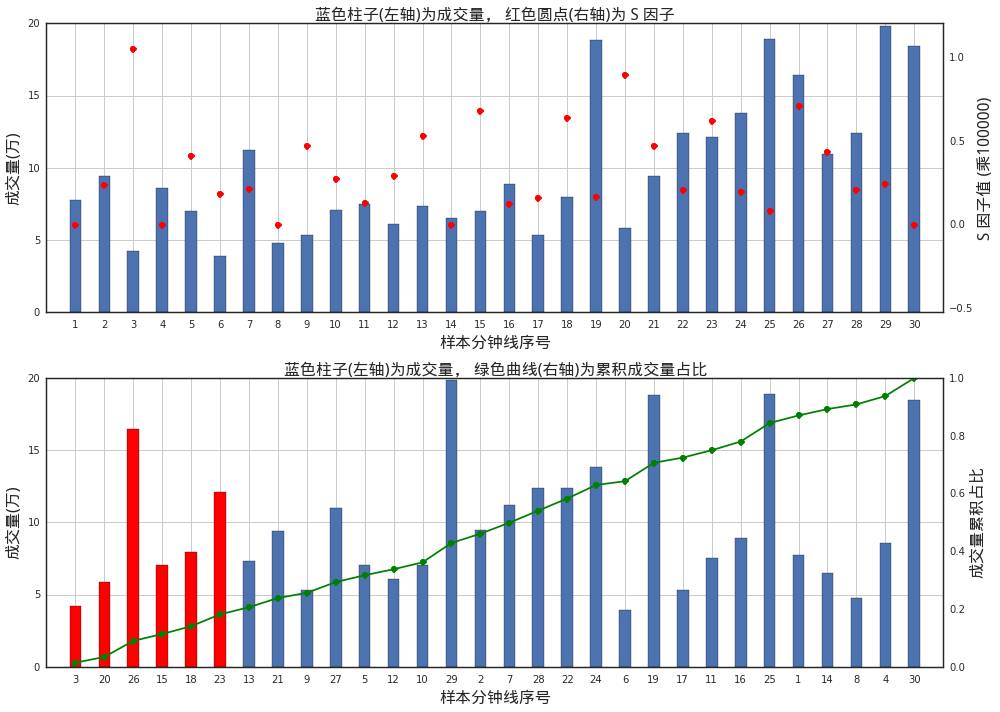
如上所示,首先对于30条样本分钟线计算S因子(上图);其次以S因子由大到小的顺序重新对这些分钟线排序,并按此顺序计算成交量累积占比(下图),截取S因子最大的前20%成交量所包含的分钟线(下图中的红色柱子)作为聪明钱。
如上划分找到聪明钱之后,我们就可以通过这些聪明钱的交易数据来构造聪明钱的情绪因子Q:

Q越大,表明聪明钱的交易越倾向于出现在价格较高处,这是逢高出货的表现,反映了聪明钱的悲观态度;Q越小,则表明聪明钱的交易多出现在价格较低处,这是逢低吸筹的表现,是乐观的情绪。
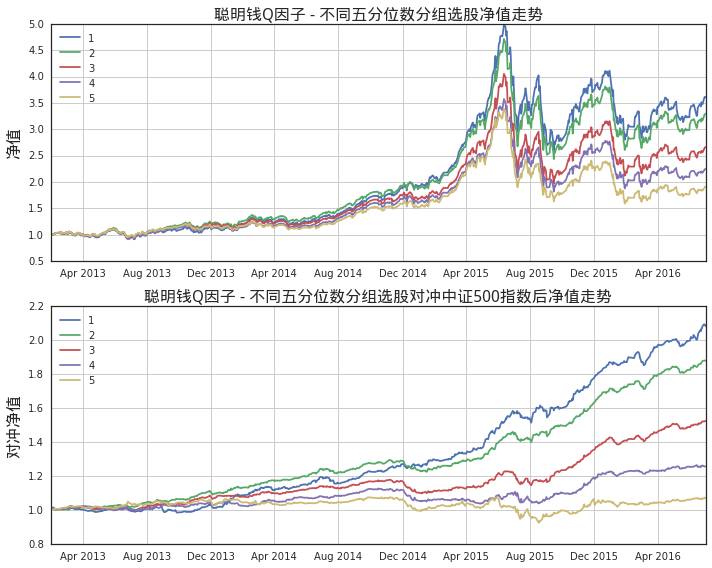
■例子2:
两个例子的本质:对过去数据的分析,建立模型发现规律(例子(i)),或者重现规律(例子(ii)中,通过过去样本中某因子与收益的关系,确定评分的梯度,并应用于以后的样本,就是一种学习、重现规律的过程),从而对后面的投资产生建议。
但是,不难发现,上述两个例子,发现规律和重现规律的过程是完全人为确定的。如例子1中是作者基于对“聪明钱”的理解,人为构造指标的,而例子2中的“重现规律”过程是从过去样本中,因子与收益的关系(如Rank
corrlelation)作定性分析,人为确定评分规则和梯度的。
那么问题来了,上述两个例子的发现规律或重现规律过程能否用机器学习代替?
上述两个例子本质也是分析过去的数据,从而发现规律或重现规律,这一过程与机器学习模型的本质是无异的。但是很遗憾,就目前的成果来看,若想在非监督情况下,利用机器学习模型来发现规律,这一点还是比较困难的(你就想象模型怎么找出例1研报中的“聪明程度”指标表达式),但是重现规律这一点,机器学习还是可以轻松做到的。
三、谈谈应用
既然已经说到,“量化投资领域中,所有需要重现规律的环节都可用机器学习模型代替”,就不用再问机器学习能应用在哪儿了。举些例子,多因子模型本质是根据过去市场对某些因子或因子组合的青睐和偏好,判断当前哪些股票值得投资。因此,就可使用机器学习模型(SVM、贝叶斯方法都是不错的)学习过去的“偏好”,应用于现在。
■ 例子1:【国信证券——SVM 算法选股以及 Adaboost 增强】。以每个因子作为一层特征, 在 68 个因子的维度下,支持向量机算法能够有效的对股票组合的标签进行分类与预测。
SVM 算法的样本数据的标准化采用排序法。 因此,计算每个股票按某因子的排序然后除以总股票数,这样因子的值归到(0,1]。
然后,对下一期收益率从大到小排序,取前 30%作为强势股,后
30%作为弱势股,强势股划分类标为+1,弱势股划分类标为-1;中间百分之 40%的股票排出训练集,因为中间百分之
40%的股票收益并不强势也不弱势,相当于噪声数据。为了充分利用数据,找出相对稳定有效的因子,确保算法的稳定性,用过去 12
个月的因子数据作为输入样本。从 SVM 理论推导可以知道, 在得到最优超平面的解之后,
样本被划分为{-1,+1}两类,而样本距离超平面的距离,则可以代表样本被正确分类的程度。 用公式表达为:
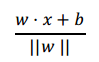
其中 x 为新的样本点, w, b 为 SVM 求解超平面的输出结果。根据距离结果, 同样将股票组合分为 10 档,选择收尾两档分别作为强势组合和弱势组合,并观察回测结果。
■ 例子2:你认为股指期货Tick数据的盘口与成交与价格未来的走势有关,就可以用机器学习模型(神经网络、深度学习网络)学习过去数据中盘口价量与之后的价格走势的规律,再应用于当前;诸如此类。(此处没有谈及也较常用的聚类算法,如GMM等。)
三、谈谈机器学习的利弊
建立一个成功的机器学习模型,包含但不限于以下过程:
数据样本的选取(因子变量的选取)、数据样本的预处理(变量的预处理、样本的平衡处理、极端样本的处理等)、人为的处理(一些变换等)、模型的选取、模型算法的选取、模型参数的选取,对欠拟合、过拟合的避免等等……撇开这些不讲,即使上述提及的过程合部处理恰当,训练结果良好,哪怕是测试样本效果也不错,应用于实际投资效果也不能保证一定好。为什么呢?
第一,这是因为我们的样本大多数时候是带有时间维度的(即训练样本、测试样本、实际投资所处的时间段都是不同的),它们并非截面数据,模型学习的市场“规律”或“偏好”,是会随时间变化的。第二,我们的模型往往只是学习某一些因子反映的规律,而除去这些因子以外的因素,影响市场变化的因素有很多很多(汇率、政策等),这些都是模型没有考虑的,一旦这些模型以外的因素成为主导市场“偏好”的时候,时间短还好说,最多也只是短期的一个回撤,如果时间较长,模型在此期间的效果就会大打折扣。
对于第二个问题,在股票多头策略中使用对冲、在多空投机策略中设置止损和失效判断(如连续n次投机连续失败时,可考虑一段时间内不再开仓投机等)也许是个好方法,对于第一个问题,使用时间跨度更长的样本进行训练并不一定能解决问题。(例如市值因子,哪怕从3年的回测跨度变成5年、7年,在过去都是较为显著的因子,但未来呢?)笔者认为这个问题需要具体分析。从数据的实际背景分析,模型所学习的规律是否可持续;如果担心这种规律变化过快,可以缩短训练样本的长度,并且采用时间滚动的样本作为训练样本。
PS
机器学习应用于量化投资的过程中仍有很多环节、细节尚未谈及,重述笔者今天最想分享的观点,就是量化投资中重现规律这一环节,可以考虑使用机器学习模型,或许会比主观建立的模型更加简单快捷、精细有效。
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330