R语言数据可视化综合指南
编译|崔浩 校对|高航,姚佳灵
让我们快速浏览一下这张图表:

这张可视化数据图(最初用Tableau软件创建
)是如何利用数据可视化来帮助决策者的一个很好的例子。想象一下,如果这些信息通过表格来告诉投资者,你认为你会花多长时间来向他解释?
如今的世界里,随着数据量的不断增长,很难不用可视化的形式来呈现你数据里的全部信息。虽然有专门的工具,如Tableau, QlikView 和 d3.js,但没有任何东西能代替有很好可视化能力的建模/统计工具。尤其是它有助于做若干探索性数据分析和特征化工程。这就是R语言,它提供了令人难以置信的帮助。
R语言提供了令人满意的一套内置函数和库(如 ggplot2, leaflet, lattice)用来建立可视化效果以呈现数据。在本文中,我已经涉及了用R语言编程来创建既常见又先进的可视化效果的步骤。但是,在介绍那些之前,让我们快速浏览一下数据可视化简史。如果您对历史不感兴趣,没问题,您可以跳到下一节。
数据可视化简史
从历史来看,数据可视化的进化已经被著名的从业者在工作中完成了。威廉.普莱菲(William Playfair)是统计图形化方法的创始人。威廉.普莱菲发明了四种类型的图表:线图、经济学数据的柱状图、饼状图和圆图。约瑟夫·普里斯特利(Joseph
Priestly)创建了第一个划时代的时间线图,其中的每一个柱形是用来显示一个人的寿命(1765)。没错,时间线图被发明于250年前,而不是Facebook发明的!
最著名的早期可视化数据是由Charles
Minard所描绘的Napoleon’s March(俄法战争)。可视化数据中包含了随着时间的变化,气温对拿破仑入侵俄国产生广泛影响的信息。在图形中,值得注意的是,在二个维度上的六种类型数据,分别表示:拿破仑军队的数量,距离,温度,纬度和经度,行军方向和跟特定日期有关的位置。
弗洛伦斯·南丁格尔(Florence Nightangle)也是数据可视化的先驱。她用数据图表的方式描述了疾病对军队的死亡率的影响(1858)。琼恩·雪诺(John Snow)(不是《权力的游戏》里的人物)是把地图用在图表和空间分析的先驱。在1854年的伦敦,用这地图发现了霍乱疫情的源头与公共水泵有关,信息图帮助精确定位爆发源到某一个泵的位置。
用R语言进行数据可视化
在这篇文章中,我们将创建以下可视化效果:
基本可视化效果
1. 直方图
2. 条形图/线型图
3. 箱式图
4. 散点图
高级可视化效果
1. 热点图
2. 影像镶嵌图
3. 地图可视化
4. 3维图
5. 相关图
R语言 小窍门:
HistData软件包提供了一个小数据集,它很有趣并且在统计和数据可视化的历史上很重要。

基本可视化效果
便签:
1.基本图形可以很容易地用R语言进行创建。绘图(plot)命令是要关注的命令。
2. 它的参数有x轴数据、y轴数据、x轴标签、y轴标签、颜色和标题。要创建线图,只需简单地使用参数,类型选择为l。
3. 如果你想要箱式图,你可以选用箱式图(boxplot),要条形图就用条形图函数。
1.直方图
基本上,直方图是将数据分解为一个个的小格子(或间隔),并显示它们的频率分布。您可以更改间隔,看看这样做对数据可视化可理解性的影响。
给您举个例子。
注意:我们使用的par(mfrow=c(2,5))命令,为的是清晰地把多个图放在同一页上(参看下面的代码)。
library(RColorBrewer)
data(VADeaths)
par(mfrow=c(2,3))
hist(VADeaths,breaks=10, col=brewer.pal(3,"Set3"),main="Set3 3 colors")
hist(VADeaths,breaks=3 ,col=brewer.pal(3,"Set2"),main="Set2 3 colors")
hist(VADeaths,breaks=7, col=brewer.pal(3,"Set1"),main="Set1 3 colors")
hist(VADeaths,,breaks=
2, col=brewer.pal(8,"Set3"),main="Set3 8 colors")
hist(VADeaths,col=brewer.pal(8,"Greys"),main="Greys 8
colors")
hist(VADeaths,col=brewer.pal(8,"Greens"),main="Greens 8
colors")

请注意,如果间隔数少于被指定的颜色数,颜色会变成极值,如上图中的“Set3 8 colors”图。如果间隔数目超过了颜色的数目,则颜色会开始像在第一行中一样地重复出现。
2.条形图/线型图
线型图
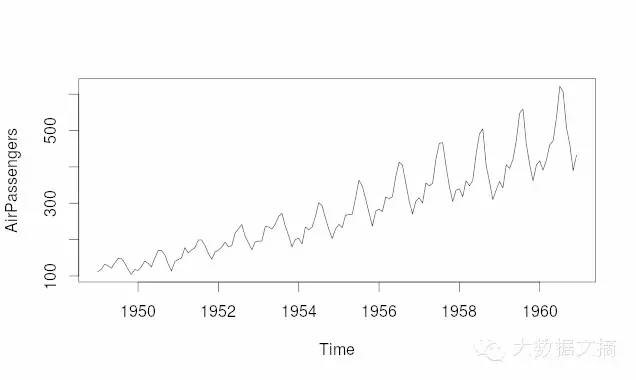
下面的折线图显示了在给定时间内飞机乘客数的增长情况。折线图通常是分析一段时间内延伸趋势的首选。此外,当我们需要比较数量随着某种变量(例如时间)的相对变化时,线型图也是适用的。下面是代码:
plot(AirPassengers,type="l")
#Simple Line Plot
条形图
条形图适用于显示跨几个组别的累计汇总之间的比较。层叠图用于跨类别的条形图。下面是代码:
barplot(iris$Petal.Length)
#Creating simple Bar Graph
barplot(iris$Sepal.Length,col
= brewer.pal(3,"Set1"))
barplot(table(iris$Species,iris$Sepal.Length),col = brewer.pal(3,"Set1"))
#Stacked Plot

3. 箱式图
箱式图显示5个有统计学意义的数字,分别是最小数、第一四分数位、中位数、第三四分位数和最大数。因此,它在数据延伸的可视化上非常有用,还能得出相应的推论。下面是简单的代码:
boxplot(iris$Petal.Length~iris$Species)
#Creating Box Plot between two variable
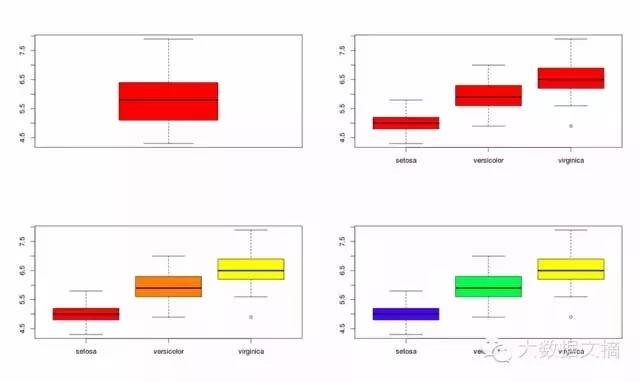
让我们来理解下面的代码:
在下面的例子中,我在屏幕上显示了4个图。通过使用~符号,我可以将(萼片的长度)的伸展是如何跨各种类别(的物种)进行可视化。我在最后的两个图中演示了调色板。调色板是一组颜色,用来使图标更有吸引力,而且能帮助在数据中创建醒目的区别。
data(iris)
par(mfrow=c(2,2))
boxplot(iris$Sepal.Length,col="red")
boxplot(iris$Sepal.Length~iris$Species,col="red")
oxplot(iris$Sepal.Length~iris$Species,col=heat.colors(3))
boxplot(iris$Sepal.Length~iris$Species,col=topo.colors(3))
要了解更多关于R语言中调色板的使用,请参看http://decisionstats.com/2011/04/21/using-color-palettes-in-r/
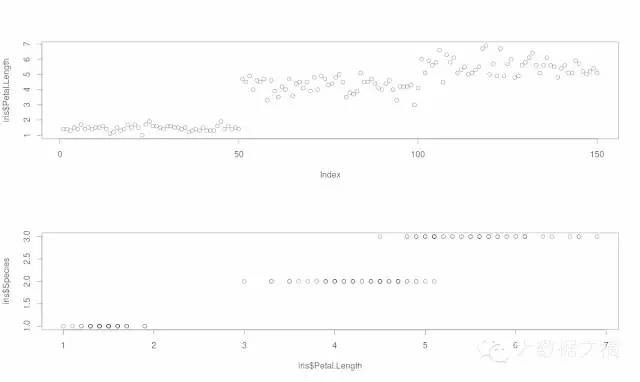
4. 散点图(包括3D等功能)
散点图有助于轻松地把数据可视化和进行简单的数据检查。这里有简单散点图和多元散点图的代码:
plot(x=iris$Petal.Length)
#Simple Scatter Plot
plot(x=iris$Petal.Length,y=iris$Species)
#Multivariate Scatter Plot
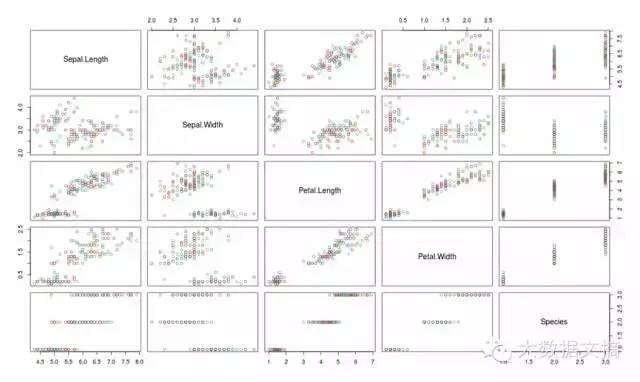
散点图矩阵可以帮助将彼此交叉的多个变量可视化。
plot(iris,col=brewer.pal(3,"Set1"))
您可能会想,我还没有把饼图列表成基本图形。这不是失误,而是我故意这么做的。这是因为,数据可视化专业人员不赞成使用饼图来表示数据。因为人的眼睛不能像目测线性距离那样精确地目测出圆的距离。只需要简单地把任何可用饼图表示的东西都用线图表示。但是,如果你喜欢饼图,可使用:
pie(table(iris$Species))
到这里为止,我们已经学过的所有图表列表如下:
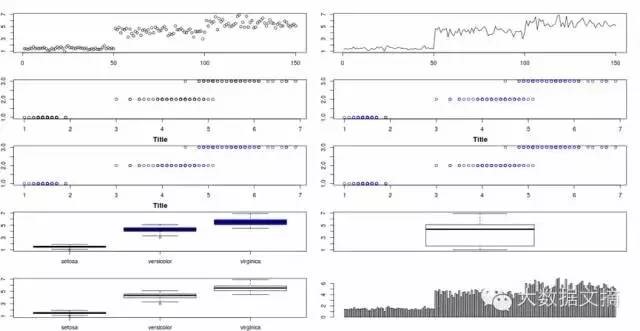
您可能已经注意到,在一些图表中,他们的标题已被截断,因为我把太多图表放在同一个屏幕上。要改变这一点,你只需要改变par函数的‘mfrow’参数。
高级可视化效果
什么是Hexbin Binning?
如果在同一个地方有很多点(overplotting),我们可以使用Hexbin包。六边形面元划分是一种二元直方图,对大数量级结构的数据集的可视化非常有用。下面是代码:
>library(hexbin)
>a=hexbin(diamonds$price,diamonds$carat,xbins=40)
>library(RColorBrewer)
>plot(a)
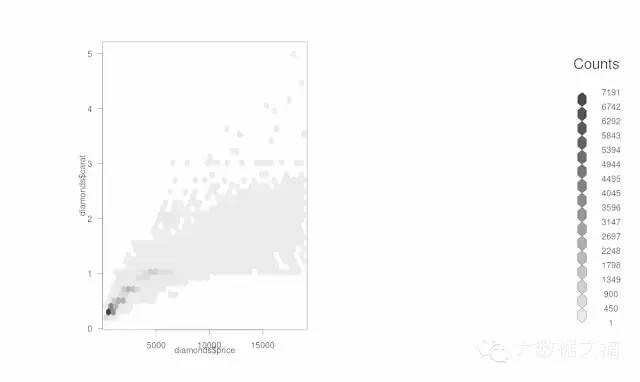
我们也可以创建一个调色板,然后用Hexbin绘图功能以获得更好的视觉效果。下面是代码:
>library(RColorBrewer)
>rf <-
colorRampPalette(rev(brewer.pal(40,'Set3')))
>hexbinplot(diamonds$price~diamonds$carat, data=diamonds, colramp=rf)
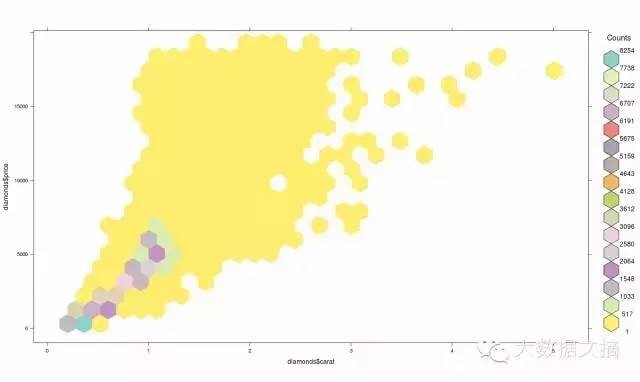
马赛克拼图
马赛克拼图可以通过数据所占据的面积大小来有效地显示分类数据的相对比例。
>
data(HairEyeColor)
>
mosaicplot(HairEyeColor)

热图
热图使你能够以两个维度为轴,颜色的强度为第三个维度来进行探索性的数据分析。然而,你需要将数据集转化成矩阵形式。下面是代码:
>
heatmap(as.matrix(mtcars))
您也可以使用image()命令做这种类型的可视化:
>
image(as.matrix(b[2:7]))
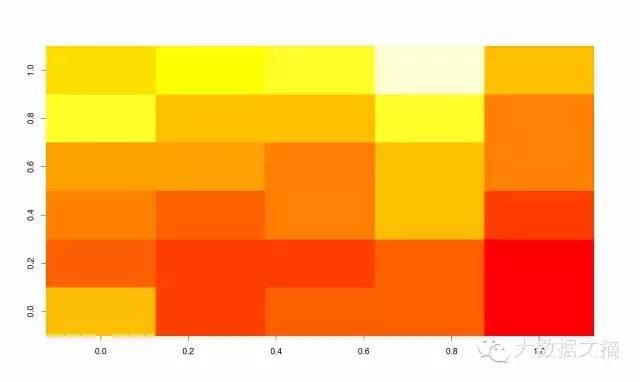
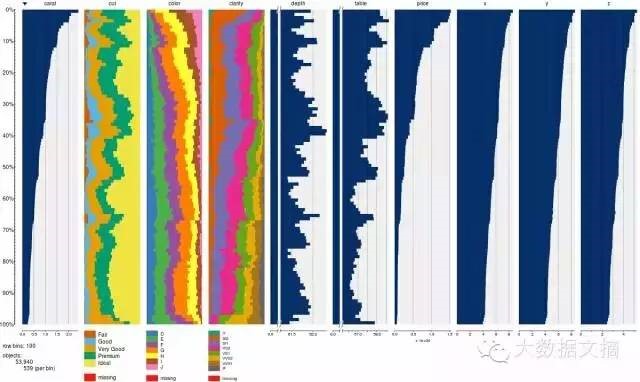
如何汇总大量数据?
您可以使用tabplot包中的tableplot功能,快速汇总大量数据
地图可视化
R语言中最新的东西是通过Javascript库来进行数据可视化。Leaflet是JavaScript开源库中最受欢迎的一个库,用于互动地图。有关它的内容,请参考https://rstudio.github.io/leaflet/。
您可以用下面的代码直接从github安装Leaflet。
devtools::install_github("rstudio/leaflet")
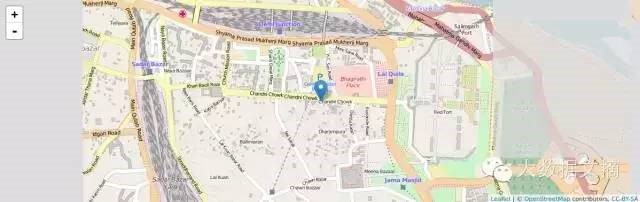
制作上述地图的代码是非常简单的:
library(magrittr)
library(leaflet)
m <- leaflet()
%>%
addTiles() %>%
# Add default OpenStreetMap map tiles
addMarkers(lng=77.2310, lat=28.6560, popup="The delicious food of chandni
chowk")
m # Print the
map
3维图
用R语言的的功能让人闪瞎眼的最简单的方法之一是通过创建一张3维图,而不需要用R语言写一行代码,并且在3分钟内就能完成。这样要求是不是太过分呢?
我们使用R Commander包作为图形用户界面(GUI)。操作步骤如下:
1. 只需安装Rcmdr包
2. 使用来自图中的3D绘图选项
下面的代码不是用户输入的,是自动生成的。
便签:当我们交换图的坐标轴时,您应该看到有着相应代码的图,我们是如何使用xlab和ylab来传递轴标签,图标题用Main函数,颜色是col参数。
>data(iris, package="datasets")
>scatter3d(Petal.Width~Petal.Length+Sepal.Length|Species, data=iris, fit="linear"
>residuals=TRUE, parallel=FALSE, bg="black", axis.scales=TRUE, grid=TRUE, ellipsoid=FALSE)

您还可以使用Lattice包来做3维图。Lattice也可以用于xyplot。下面是代码:
>attach(iris)# 3d
scatterplot by factor level
>cloud(Sepal.Length~Sepal.Width*Petal.Length|Species, main="3D Scatterplot by Species")
>xyplot(Sepal.Width
~ Sepal.Length, iris, groups =
iris$Species, pch= 20)
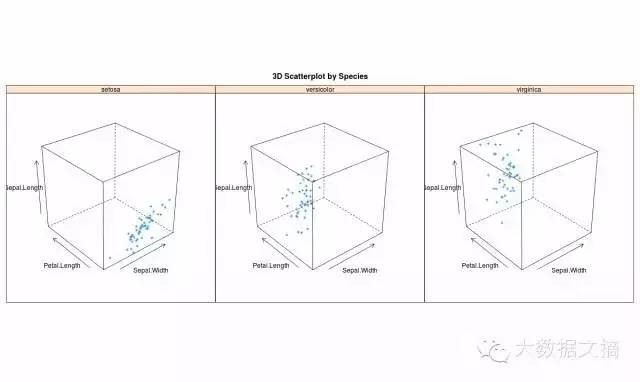
相关图(GUIs)
相关图帮助我们把相关矩阵内的数据可视化。下面是代码:
> cor(iris[1:4])
Sepal.Length
Sepal.Width Petal.Length Petal.Width
Sepal.Length
1.0000000 -0.1175698 0.8717538 0.8179411
Sepal.Width
-0.1175698 1.0000000 -0.4284401 -0.3661259
Petal.Length 0.8717538
-0.4284401 1.0000000 0.9628654
Petal.Width
0.8179411 -0.3661259 0.9628654 1.0000000
> corrgram(iris)
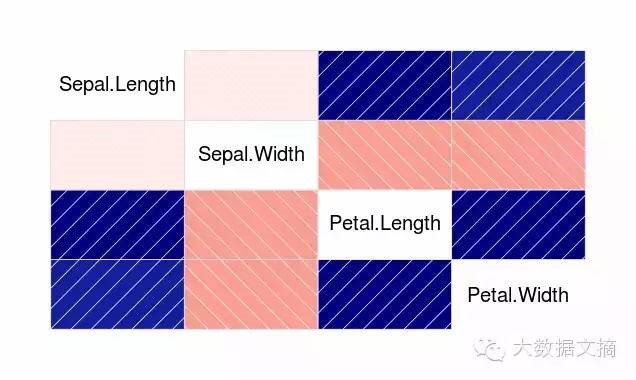
R语言有三个主要的GUI包。RCcommander和KMggplot及Rattle用于数据
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330