python制作爬虫并将抓取结果保存到excel中
学习Python也有一段时间了,各种理论知识大体上也算略知一二了,今天就进入实战演练:通过Python来编写一个拉勾网薪资调查的小爬虫。
第一步:分析网站的请求过程
我们在查看拉勾网上的招聘信息的时候,搜索Python,或者是PHP等等的岗位信息,其实是向服务器发出相应请求,由服务器动态的响应请求,将我们所需要的内容通过浏览器解析,呈现在我们的面前。

可以看到我们发出的请求当中,FormData中的kd参数,就代表着向服务器请求关键词为Python的招聘信息。
分析比较复杂的页面请求与响应信息,推荐使用Fiddler,对于分析网站来说绝对是一大杀器。不过比较简单的响应请求用浏览器自带的开发者工具就可以,比如像火狐的FireBug等等,只要轻轻一按F12,所有的请求的信息都会事无巨细的展现在你面前。
经由分析网站的请求与响应过程可知,拉勾网的招聘信息都是由XHR动态传递的。

我们发现,以POST方式发出的请求有两个,分别是companyAjax.json和positionAjax.json,它们分别控制当前显示的页面和页面中包含的招聘信息。
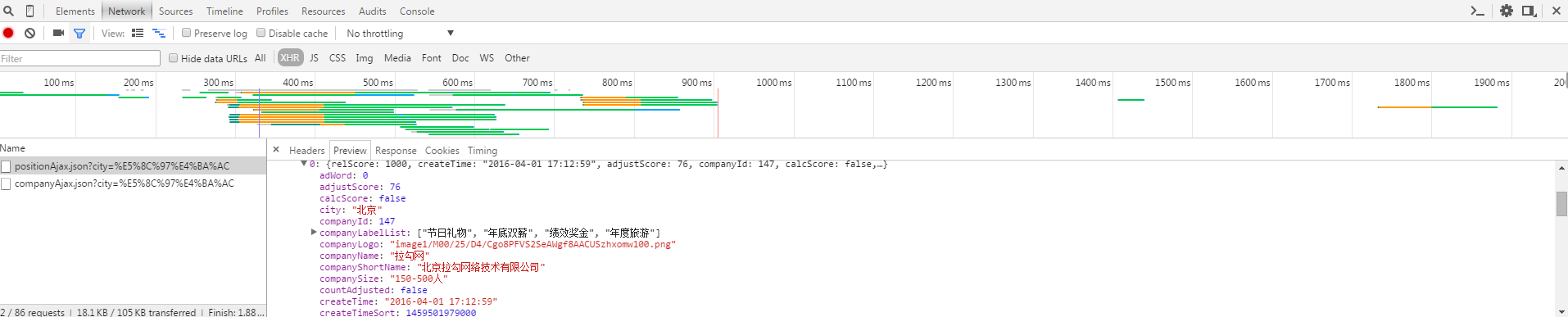
可以看到,我们所需要的信息包含在positionAjax.json的Content->result当中,其中还包含了一些其他参数信息,包括总页面数(totalPageCount),总招聘登记数(totalCount)等相关信息。
第二步:发送请求,获取页面
知道我们所要抓取的信息在哪里是最为首要的,知道信息位置之后,接下来我们就要考虑如何通过Python来模拟浏览器,获取这些我们所需要的信息。
def read_page(url, page_num, keyword): # 模仿浏览器post需求信息,并读取返回后的页面信息
page_headers = {
'Host': 'www.lagou.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3',
'Connection': 'keep-alive'
}
if page_num == 1:
boo = 'true'
else:
boo = 'false'
page_data = parse.urlencode([ # 通过页面分析,发现浏览器提交的FormData包括以下参数
('first', boo),
('pn', page_num),
('kd', keyword)
])
req = request.Request(url, headers=page_headers)
page = request.urlopen(req, data=page_data.encode('utf-8')).read()
page = page.decode('utf-8')
return page
其中比较关键的步骤在于如何仿照浏览器的Post方式,来包装我们自己的请求。
request包含的参数包括所要抓取的网页url,以及用于伪装的headers。urlopen中的data参数包括FormData的三个参数(first、pn、kd)
包装完毕之后,就可以像浏览器一样访问拉勾网,并获得页面数据了。
第三步:各取所需,获取数据
获得页面信息之后,我们就可以开始爬虫数据中最主要的步骤:抓取数据。
抓取数据的方式有很多,像正则表达式re,lxml的etree,json,以及bs4的BeautifulSoup都是python3抓取数据的适用方法。大家可以根据实际情况,使用其中一个,又或多个结合使用。
def read_tag(page, tag):
page_json = json.loads(page)
page_json = page_json['content']['result']
# 通过分析获取的json信息可知,招聘信息包含在返回的result当中,其中包含了许多其他参数
page_result = [num for num in range(15)] # 构造一个容量为15的占位list,用以构造接下来的二维数组
for i in range(15):
page_result[i] = [] # 构造二维数组
for page_tag in tag:
page_result[i].append(page_json[i].get(page_tag)) # 遍历参数,将它们放置在同一个list当中
page_result[i][8] = ','.join(page_result[i][8])
return page_result # 返回当前页的招聘信息
第四步:将所抓取的信息存储到excel中
获得原始数据之后,为了进一步的整理与分析,我们有结构有组织的将抓取到的数据存储到excel中,方便进行数据的可视化处理。
这里我用了两个不同的框架,分别是老牌的xlwt.Workbook、以及xlsxwriter。
def save_excel(fin_result, tag_name, file_name):
book = Workbook(encoding='utf-8')
tmp = book.add_sheet('sheet')
times = len(fin_result)+1
for i in range(times): # i代表的是行,i+1代表的是行首信息
if i == 0:
for tag_name_i in tag_name:
tmp.write(i, tag_name.index(tag_name_i), tag_name_i)
else:
for tag_list in range(len(tag_name)):
tmp.write(i, tag_list, str(fin_result[i-1][tag_list]))
book.save(r'C:\Users\Administrator\Desktop\%s.xls' % file_name)
首先是xlwt,不知道为什么,xlwt存储到100多条数据之后,会存储不全,而且excel文件也会出现“部分内容有问题,需要进行修复”我检查了很多次,一开始以为是数据抓取的不完全,导致的存储问题。后来断点检查,发现数据是完整的。后来换了本地的数据进行处理,也没有出现问题。我当时的心情是这样的:

到现在我也没弄明白,有知道的大神希望能告诉我ლ(╹ε╹ლ)
def save_excel(fin_result, tag_name, file_name): # 将抓取到的招聘信息存储到excel当中
book = xlsxwriter.Workbook(r'C:\Users\Administrator\Desktop\%s.xls' % file_name) # 默认存储在桌面上
tmp = book.add_worksheet()
row_num = len(fin_result)
for i in range(1, row_num):
if i == 1:
tag_pos = 'A%s' % i
tmp.write_row(tag_pos, tag_name)
else:
con_pos = 'A%s' % i
content = fin_result[i-1] # -1是因为被表格的表头所占
tmp.write_row(con_pos, content)
book.close()
这是使用xlsxwriter存储的数据,没有问题,可以正常使用。
到从为止,一个抓取拉勾网招聘信息的小爬虫就诞生了。
附上源码
#! -*-coding:utf-8 -*-
from urllib import request, parse
from bs4 import BeautifulSoup as BS
import json
import datetime
import xlsxwriter
starttime = datetime.datetime.now()
url = r'http://www.lagou.com/jobs/positionAjax.json?city=%E5%8C%97%E4%BA%AC'
# 拉钩网的招聘信息都是动态获取的,所以需要通过post来递交json信息,默认城市为北京
tag = ['companyName', 'companyShortName', 'positionName', 'education', 'salary', 'financeStage', 'companySize',
'industryField', 'companyLabelList'] # 这是需要抓取的标签信息,包括公司名称,学历要求,薪资等等
tag_name = ['公司名称', '公司简称', '职位名称', '所需学历', '工资', '公司资质', '公司规模', '所属类别', '公司介绍']
def read_page(url, page_num, keyword): # 模仿浏览器post需求信息,并读取返回后的页面信息
page_headers = {
'Host': 'www.lagou.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3',
'Connection': 'keep-alive'
}
if page_num == 1:
boo = 'true'
else:
boo = 'false'
page_data = parse.urlencode([ # 通过页面分析,发现浏览器提交的FormData包括以下参数
('first', boo),
('pn', page_num),
('kd', keyword)
])
req = request.Request(url, headers=page_headers)
page = request.urlopen(req, data=page_data.encode('utf-8')).read()
page = page.decode('utf-8')
return page
def read_tag(page, tag):
page_json = json.loads(page)
page_json = page_json['content']['result'] # 通过分析获取的json信息可知,招聘信息包含在返回的result当中,其中包含了许多其他参数
page_result = [num for num in range(15)] # 构造一个容量为15的list占位,用以构造接下来的二维数组
for i in range(15):
page_result[i] = [] # 构造二维数组
for page_tag in tag:
page_result[i].append(page_json[i].get(page_tag)) # 遍历参数,将它们放置在同一个list当中
page_result[i][8] = ','.join(page_result[i][8])
return page_result # 返回当前页的招聘信息
def read_max_page(page): # 获取当前招聘关键词的最大页数,大于30的将会被覆盖,所以最多只能抓取30页的招聘信息
page_json = json.loads(page)
max_page_num = page_json['content']['totalPageCount']
if max_page_num > 30:
max_page_num = 30
return max_page_num
def save_excel(fin_result, tag_name, file_name): # 将抓取到的招聘信息存储到excel当中
book = xlsxwriter.Workbook(r'C:\Users\Administrator\Desktop\%s.xls' % file_name) # 默认存储在桌面上
tmp = book.add_worksheet()
row_num = len(fin_result)
for i in range(1, row_num):
if i == 1:
tag_pos = 'A%s' % i
tmp.write_row(tag_pos, tag_name)
else:
con_pos = 'A%s' % i
content = fin_result[i-1] # -1是因为被表格的表头所占
tmp.write_row(con_pos, content)
book.close()
if __name__ == '__main__':
print('**********************************即将进行抓取**********************************')
keyword = input('请输入您要搜索的语言类型:')
fin_result = [] # 将每页的招聘信息汇总成一个最终的招聘信息
max_page_num = read_max_page(read_page(url, 1, keyword))
for page_num in range(1, max_page_num):
print('******************************正在下载第%s页内容*********************************' % page_num)
page = read_page(url, page_num, keyword)
page_result = read_tag(page, tag)
fin_result.extend(page_result)
file_name = input('抓取完成,输入文件名保存:')
save_excel(fin_result, tag_name, file_name)
endtime = datetime.datetime.now()
time = (endtime - starttime).seconds
print('总共用时:%s s' % time)
还有许多功能可以添加,比如说通过修改city参数查看不同城市的招聘信息啦等等,大家可以自行开发,这里只做抛砖引玉之用
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330