数据造假的三种常见形态_数据分析师考试
日常生活工作中,处处都会与数据打交道,但你知道数据是会“说谎”的,即你看到的数据结果并不是事实。本文介绍一些常见的说谎场景以及如何避免。
一、图表欺骗
图表通常用来增强需要文字和数据的说服力,通过可视化的图表更容易让受众接受信息。但图表有时候会表现的不是数据的本质:
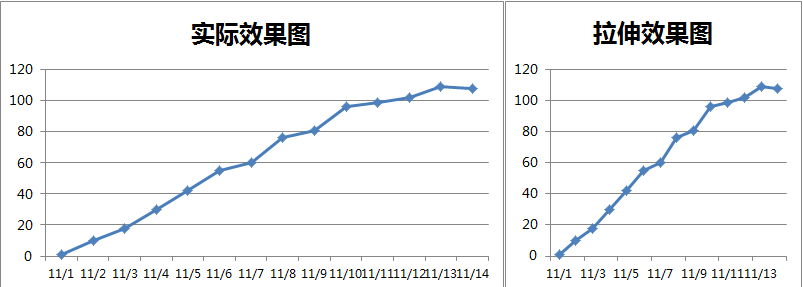
1.图表拉伸
如果没有特殊用途,通常图表的长(横轴)与高(纵轴)的比例为1:1到1:2之间,如果在这个范围之外,数据现实的结果会过于异常。比如:
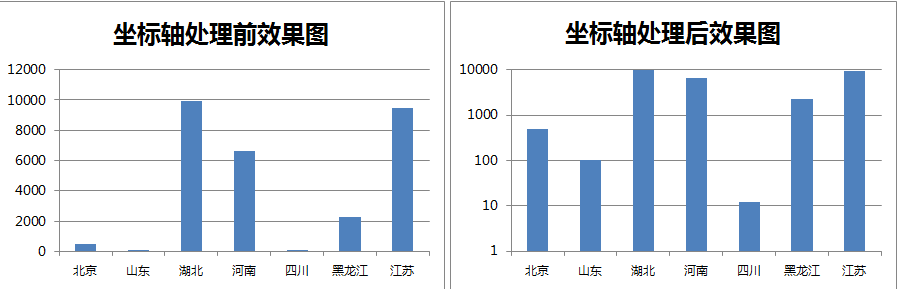
2.坐标轴特殊处理
在很多场合下,如果两列数据的取值范围差异性过大,通常在显示时会取对数,这时原来柱状图间的巨大差异会被故意缩小。通常,严谨的分析师在讲解之前会进行告知。比如:
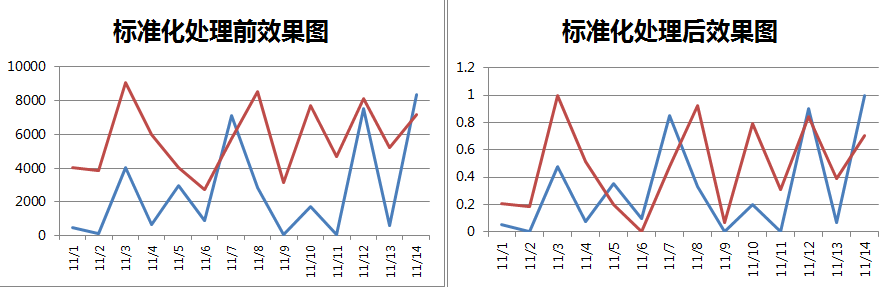
3.数据标准化
数据标准化也是一个让数据落在相同区间内常用的方法,常用Z标准化或0-1标准化,如果不提前告知,可能会误以为两列数据取值异常接近,不符合实际业务场景,比如:
隐秘层次:★★☆☆☆
破解方法:询问分析师的图表各个含义,了解基本图表查看常识。
二、数据处理欺骗
数据处理中的欺骗方法通常包括抽样方法欺骗、样本量不同、异常值处理欺骗等。
1.抽样方法欺骗
整体样本的维度,粒度和取数逻辑相同的情况下,不用的样本抽样规则会使数据看来更符合或不符合“预期”。比如在做用户挽回中,假如做的两次活动的抽样样本分别是最近6个月未购物和最近6个月未购物但有登陆行为的用户,不用做什么测试,基本上可以确定后者的挽回效果更佳。要识破这个“骗局”只需要询问数据取样方法即可,需要细到具体的SQL逻辑。
2.样本量不同
严格来说样本量不同并不一定是故意欺骗,实践中确实存在这种情况。(遇到这种情况可以用欠抽样和过抽样进行样本平衡)样本量不同分为两种情况:
样本量数量不同。比如要做效果差异对比,第一步是做效果比对,假如两个数据样本量分别是几千和几万的级别,可比性就很小。尤其是对于样本分布不均的情况下,数据结果可信度低。
样本主体不同。这是非常严重的数据引导错误,通常存在于为了达到某种结果而故意选择对结果有利的样本。比如做品类推广,一部分用户推广渠道为广告,另一部分是CPS可以遇见相同费用下后者的效果必然更好。
相同样本不同的客观环境。比如做站内用户体验分析,除了用随机A/B测试以外,其他所有测试方法都没有完全相同的客观环境,因此即使选的是相同样本,不同时间由于用户,网站本身等影响,可信度较低。
3.异常值处理欺骗
通常面对样本时需要做整体数据观察,以确认样本数量、均值、极值、方差、标准差以及数据范围等。其中的极值很可能是异常值,此时如何处理异常值会直接影响数据结果。比如某天的销售数据中,可能存在异常下单或行单,导致品类销售额和转化率异常高。如果忽视该情况,结论就是利好的,但实际并非如此。通常我们会把异常值拿出来,单独做文字说明,甚至会说明没有异常值下的真实情况。
隐秘层次:★★★☆☆
破解方法:在跟数据分析师沟通中,多询问他们在数据选取规则,处理方法上的方法,如果他们吞吞吐吐或答不上来,那很有可能是故意为之。同时,业务人员也要增强基本数据意识,不能被这种不可见的底层错误欺骗。
三、 意识上的欺骗
这种欺骗是等级最高也是最严重的欺骗和错误,通常存在于数据分析师在做数据之前就已经下结论,分析过程中只选取有利于证明其论断的方法和材料,因此会在从数据选择,处理,数据表现等各个方面进行事实上的扭曲,是严重的误导行为!数据分析师需要有中立的立场,客观的态度,任何有立场的分析师的结论都会失之偏颇。
隐秘层次:★★★★★
破解方法:在跟该分析师沟通中,查看其是否有明显立场或态度,如果有,那么该警惕;然后通过上面的方法逐一验证。
综上,当你遇到以下数据情形,就需要警惕数据的真实性了:
数据报告从来不注明数据出处,数据时间,数据取样规则,数据取得方法等。现在市场上很多报告都属于这一类。
数据报告在做市场调研中说明全样本共1000,其中北京可能只有100,基于这100个样本出来的结论显然不可信。事实上很多市场研究报告就是这样出来的。
数据报告中存在明显的观点,对于事物的分析只讲其优势或劣势,不全面也不客观。现在很多互联网分析师就是属于这类,大家注意辨别。
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330