很多数据分析师写过无数个 SELECT,但当被问到“新建一张表,该如何定义字段 类型来保证数据质量 ”“创建视图和存储物理表有什么区别,分别应该在什么业务场景下使用”时,却常常陷入支支吾吾的困境。其实,CURD(增删改查)只是基本功,而通过合理创建表和视图来打通数据从源头治理到高效取用的全链路,才是CDA数据分析师向“数据架构 思维”迈进的分水岭。
” 引言:为什么“创建表或视图”会成为数据分析师的能力分界线? 小林是刚进公司一年多的数据分析师,埋头写复杂SQL 是日常,颇受团队认可。在一次接任务时,他发现业务系统导出的宽表中有大量重复订单号,数据看上去“有缺失,有混乱”。小林想直接从原表里分析每个月的用户留存趋势,却发现缺少关键的日期索引 、字段 类型不匹配、缺失主键标识等问题,导致分析时频频出错,效率大降。
技术主管建议:“按分析需求,你其实可以自己创建一张固化表,专门存放清洗好、组织好的中间数据。”小林恍然:原来许多底层的分析数据混乱,往往因为表结构 设计不严谨。而视图将复杂的查询逻辑封装为一张“虚拟表”,能极大简化上层取数。能否在实际工作中熟练创建和管理表与视图,正是“数据治理 ”和“商业洞察”能力的集中体现。
一、DDL的本质:构建与管理数据的“骨架规则” 数据定义的背后,是对数据存储 逻辑和结构管理的掌控。
1. 什么是 DDL? DDL(Data Definition Language,数据定义语言)是SQL 语言四大分类之一,主要用于定义和管理数据库中的所有数据对象 ,包括数据库本身、数据表、索引 和视图等。
核心关键字 :CREATE(创建)、DROP(删除)、ALTER(修改)、RENAME(重命名)、TRUNCATE(清空数据)。操作特点 :DDL语句执行后会影响数据库的物理结构(如表、字段 的存储定义),且操作通常会默认触发事务提交,不便于回滚。
DDL 的数据存储 基础——字段 与数据类型
“数据库基本结构——最小的储存单位:字段 ”。字段 是数据表中最基本的存储单元,每个字段 需要定义明确的数据类型 与约束规则,以确保数据的一致性和完整性。
数据类型 类别常见类型
使用场景分析
CDA 考点提示
整数类型 INT、BIGINT、SMALLINT
存储非小数数值(如订单数、年龄、库存量)
适用于统计计数和ID字段 ,范围要匹配存储量级
字符类型 CHAR(n)、VARCHAR(n)
存储文本或编码(姓名、邮箱、城市)
VARCHAR是可变长度,更节省存储空间
日期与时间 DATE、DATETIME、TIMESTAMP
记录时间轴,便于排序与趋势分析
表设计时优先用DATE或TIMESTAMP便于后期分析
浮点与定点 FLOAT、DOUBLE、DECIMAL(p,s)
表示金额、百分比等精度 敏感的数据
DECIMAL可以精确控制小数位数,财务场景必备
二进制/大对象 BLOB、TEXT
存储图片、长文本(JSON、评论)
在大型系统中不建议将BLOB放在主分析表,会影响性能
2. 数据完整性约束——数据质量 “守护者” 为了保证数据的完整性,可以通过四种方式实现:约束、规则、默认值、触发器。其中完整性约束 是最常使用的核心手段,包括以下几种类型:
约束类型
关键字
作用
分析意义
主键约束 PRIMARY KEY
唯一标识表中的每一行,值非空且唯一
订单表、用户表必须以主键确保分析时的唯一识别
外键约束 FOREIGN KEY
维护表与表之间的数据一致性,如“订单表的用户ID必须出现在用户表中”
确保多表关联分析时不会因脏数据导致匹配错误
唯一约束 UNIQUE
保证某列/列组合的值不会重复(可允许存在NULL)
用于身份证号、邮箱等需要防止重复的业务字段
非空约束 NOT NULL
强制某列不能为空
分析时必须确保关键字段 (如订单金额)不能缺失
检查约束 CHECK
定义合法值范围或表达式,如性别字段 只能取“男”“女”
确保维度字段 取值的规范性
默认约束 DEFAULT
未显式赋值时提供默认值
比如状态字段 默认为“待处理”
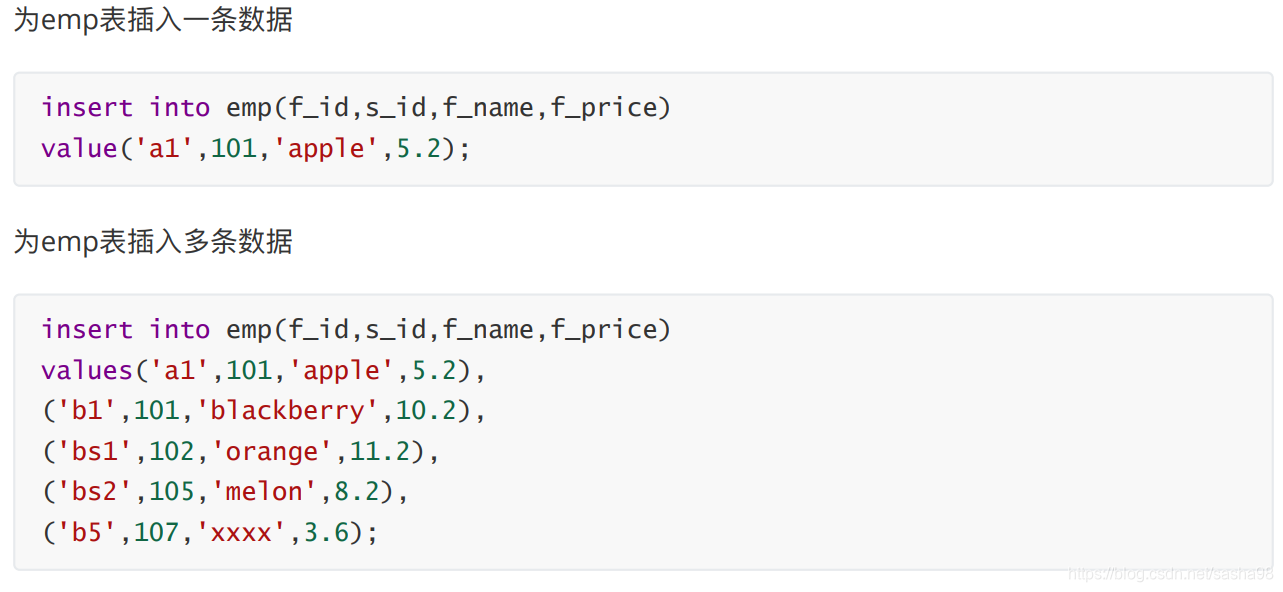
二、CREATE TABLE:从业务需求到数据实体的“落地架” 直接使用CREATE TABLE语句,能将清洗好、规范化组织的分析宽表固化进数据库,避免核心业务系统被大查询拖垮。
1. 创建表的完整语法 创建表的过程是设计其存储规则和业务结构,语法结构如下:
CREATE TABLE [IF NOT EXISTS ] 表名 (1 数据类型 [列级约束] [默认值],2 数据类型 [列级约束] [默认值],
示例:构建用户订单分析基表
假设某电商平台为简化分析,需要创建一张订单固化宽表 order_analysis_base,用于后续销售趋势计算:
CREATE TABLE order_analysis_base (VARCHAR (50 ) PRIMARY KEY , VARCHAR (50 ) NOT NULL , VARCHAR (50 ) DEFAULT '未知' , DECIMAL (10 ,2 ) NOT NULL , VARCHAR (20 ) CHECK (order_status IN ('已支付' ,'未支付' ,'已取消' )), TIMESTAMP NOT NULL ,VARCHAR (50 )这种表一旦创建,分析师可以定期通过ETL (抽取—转换—加载流程)将数据写入,避免频繁查询事务处理系统,影响线上业务。
2. 表结构 的动态管理(ALTER / DROP)
操作类型
语法示例
实战注意点
修改表名 ALTER TABLE 旧表名 RENAME TO 新表名;确保下游依赖同步修改
新增字段 ALTER TABLE 表名 ADD 新字段 名 数据类型 [约束];大批量表谨慎添加,避免锁表
修改字段 ALTER TABLE 表名 MODIFY 字段 名 新数据类型 ;修改前确认原业务是否依赖旧类型
删除字段 /表 ALTER TABLE 表名 DROP 字段 名; / DROP TABLE 表名;⚠️操作不可逆,执行前做好备份
DDL相关的具体语法及函数细节,可参考CDA官方教材和模拟题库,以提升对表物理结构的规范操控力。
三、CREATE VIEW:加速取数的“虚拟快捷窗口” 与占物理磁盘的表不同,视图是一张不存储数据 、仅保存查询逻辑的虚拟表。如果将创建表看做建地基,创建视图就是在地基上铺设“能快速响应上层需求的快捷通道”。视图的核心语法为:
CREATE VIEW view_name AS SELECT column1, column2, ...FROM table_nameWHERE condition;视图是CDA分析师对复杂数据处理 进行逻辑抽象和封装的最常用工具,堪称“查询封装大师”。
1. 视图的生命周期价值
应用场景
解决方案
CDA 考点提示
简化复杂多表联查 将复杂的JOIN多张表逻辑封装成视图,上层直接SELECT * 即可
考试中常让考生分析什么时候该建表、什么时候该建视图
实现数据安全 与权限隔离 隐藏敏感列(如用户手机号),仅将视图开放给业务方查询
视图不仅简化操作,还能高效实现权限隔离,CASE类题重点考察此差异
封装通用查询逻辑 固定常用的查询模板(如“近7天活跃用户”),团队直接使用
避免重复写同义SQL ,确保口径统一
屏蔽底层物理存储变更 当底层表字段 调整时,更新视图结构即可,上层业务代码无需变更
增强系统的可维护性
2. 视图创建与高级选项 WITH CHECK OPTION :插入或更新行时,确保修改后的行仍能被视图查询到(即仍然符合视图定义中的WHERE条件),主要用于确保数据一致性。
创建视图的可靠性保证(With Check Option) :当一个视图是基于底层表的部分数据构建时,CDA分析师通常配合WITH CHECK OPTION条款禁止输入不符合视图过滤视图的数据。
WITH LOCAL CHECK OPTION :仅检查当前视图的直接定义条件。WITH CASCADED CHECK OPTION (默认行为):检查当前视图及所有底层视图的完整定义条件。
WITH ENCRYPTION :在SQL Server等主流数据库中,该选项可以用于隐藏视图文本,在不深入核心视图定义的情况下保证视图定义不被轻易篡改。
视图在CDA考试中的考查形式非常直接 :题目会给出一条SQL 语句(如CREATE VIEW v_t1 AS SELECT id,name FROM t1;),要求考生识别语句的功能——这是一个创建视图的语句,用于创建一个名为 v_t1 的视图,视图中包含 t1 表的 id 和 name 字段 ,该语句不会更新 t1 表中的内容。
四、创建表 vs 创建视图:核心对象的核心差异 表与视图都用于组织和呈现数据,但二者在存储方式、使用场景上存在本质区别,CDA分析师需精准匹配其适用场景,避免混淆使用。
对比维度
CREATE TABLE(物理表)
CREATE VIEW(视图)
CDA选择建议
存储本质 物理存储数据,占用磁盘空间
虚拟表,仅保存查询定义(SELECT语句)
需持久化中间结果→表;仅复用逻辑→视图
数据更新 直接支持增删改操作(INSERT/DELETE/UPDATE)
更新受限,简单视图可能支持更新(需满足特定规则)
需频繁写入/更新→表;仅读取→视图
查询性能 直接读取数据,大数据量时非常快(条件索引 加持)
需动态编译执行SELECT指令,复杂视图可能导致额外性能消耗
高频、大数据量查询→预先建表;低频复杂逻辑→视图
依赖关系 独立存在,不依赖其他对象
依赖底层基表(底层表被删除则视图失效)
底层结构稳定→视图;需要独立复制→表
视图固化流程 是数据库的事实集合,影响物理架构
通过“虚拟窗口”更新数据,统一并简化接口设计
无
从CDA考试与工作中数据架构 的理念上看:表更稳定,视图更灵活;表更占空间,视图更省空间;表更易被下游系统依赖,视图更利于解耦和复用。
五、实战演练:从业务报表需求出发,构建表与视图的完整协同 背景 某电商平台的数据分析部门接到需求:快速实现每日“每个城市近30天已支付订单的GMV(成交总额)”统计,用于运营早报推送。
Step 1:构建核心数据表(固化中间结果) 为避免每日反复跨业务订单表(数据量极大)进行大规模连接,首先生成一张固化表 daily_city_order,作为中间存储区域:
CREATE TABLE daily_city_order (DATE NOT NULL ,VARCHAR (20 ) NOT NULL ,DECIMAL (12 ,2 ) NOT NULL ,KEY (stat_date, city_code)这张表每日通过定时任务(ETL )写入汇总数据。构建后的表不仅能支持日报查询,还能服务于后续多个月的同环比分析,是真实业务系统中“高性能数据服务”的典型设计。
Step 2:创建视图,封装逻辑(安全与快捷) 为了方便运营同学直接取数,避免他们接触复杂的聚合与连接逻辑,创建一张视图 v_city_gmv_30days 封装核心业务口径:
CREATE VIEW v_city_gmv_30days AS SELECT SUM (total_gmv) AS gmv_last_30days,COUNT (DISTINCT stat_date) AS active_daysFROM daily_city_orderWHERE stat_date >= CURDATE () - INTERVAL 30 DAY GROUP BY city_code;后续运营早报系统直接查询 v_city_gmv_30days 就能稳定拿结果,不需要在意底表的数据清理 和ETL 过程。
Step 3:利用视图加速分析,结合实际业务洞察 分析师小李基于这张视图,按城市GMV排序列出Top 10,并进一步分析同比、环比的变化,精准识别业绩异常城市并向区域运营部门发送预警。这个过程巧妙地结合了创建表的数据沉淀 (daily_city_order)和创建视图的逻辑封装 (v_city_gmv_30days),帮助团队从根源把控数据质量 ,又让数据真正发挥出决策价值。这正是CDA数据分析师应该具备的结构化数据管理思路。
这就是一套完整的“业务需求梳理→创建实体表固化中间数据→创建视图封装业务逻辑→上层取数分析 ”的表与视图协同实战流程。
” 结尾:从“用表分析”到“懂造表造视图” 很多数据分析师能写复杂的SELECT和JOIN,但当被问到“为什么要建这张中间表”“视图是否可以随意修改里面的数据”“底层基表结构 被改对视图有什么影响”时,往往答不上来。
2025年CDA新考纲明确在“DDL 数据定义语言”中要求达到**〖应用〗**级别,核心就是对数据结构 的掌控能力和逻辑复用能力。PART 8的导向正是让分析人员掌握最基本的数据库设计规范,确保在团队内部能独立构建符合分析需求的数据资产。
创建一张表就像在为数据仓储打下坚实的地基;创建一个视图则是在地基上铺设高效取数的管道。只有掌握两者的创建与管理,才能让数据真正体系化、可管理化、可复用化。CDA一级考试完整覆盖了DDL数据定义语言的全链应用,通过系统的教材和模拟题训练,帮助你把数据库设计的基础认知升维到数据架构 思维的层次。
下一步行动 :
在你常用的数据库操作工具中,尝试建立一张符合三范式设计(三种数据组织设计规范)简单表,明确主键和非空约束 在基于多张业务表的复杂查询逻辑上,尝试创建一个视图,对比直接写多表JOIN的效率和代码维护成本 检查组织内有没有定义不良的“基表”,判断其是否满足实体完整性,有必要时尝试用CREATE重新重建
CREATE TABLE 和 CREATE VIEW 共同构成了数据分析师手中的“建设权”——构建稳健的数据骨架,封装可复用的分析逻辑,让数据真正成为资产。
” 图文含有广告内容
推荐学习书籍 《CDA一级教材 》适合CDA一级考生备考,也适合业务及数据分析岗位的从业者提升自我。完整电子版已上线CDA网校,累计已有10万+在读~ ! 
 )
)










 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330