作者 | CDA数据分析师
我们把菜品挑选出来以后,就可以开始切菜了。比如要做凉拌黄瓜丝,把黄瓜找出来以后,那就可以把黄瓜切成丝了。
一、数值替换
数值替换就是将数值A替换成B,可以用在异常值替换处理、缺失值填充处理中。主要有一对一替换、多对一替换、多对多替换三种替换方法。
1、一对一替换
一对一替换是将某一块区域中的一个值全部替换成另一个值。已知现在有一个年龄值是240,很明显这是一个异常值,我们要把它替换成一个正常范围内的年龄值(用正常年龄的均值33),怎么实现呢?
(1)Excel实现
在Excel中对某个值进行替换,首先要把待替换的区域选中,如果只是替换某一列中的值,只需要选中这一列即可;如果要在这一片区域中进行替换,那么拖动鼠标选中这一片区域。然后依次单击编辑菜单栏中的查找和选择>;替换选项(如下图所示)即可调出替换界面。使用快捷键Ctrl+H也可以调出替换界面。
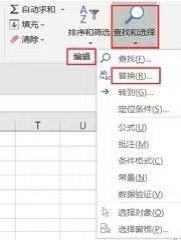
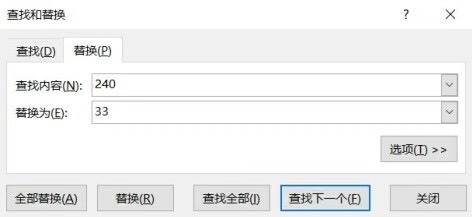
下图为替换界面,分别输入查找内容和替换内容,然后根据需要单击全部替换或者替换全部即可。
(2)Python实现
在python中对某个值进行替换利用的是replace()方法,replace(A,B)表示将A替换成B。
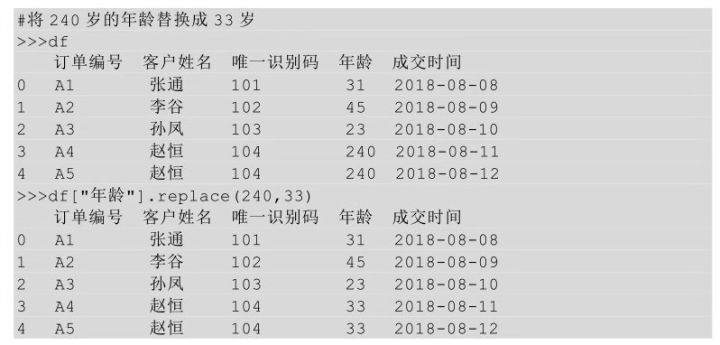
上面的代码是对年龄这一列进行替换,所以把年龄这一列选中,然后调用replace()方法。有时候要对整个表进行替换,比如对全表中的缺失值进行替换,这个时候replace()方法就相当于fillna()方法了。
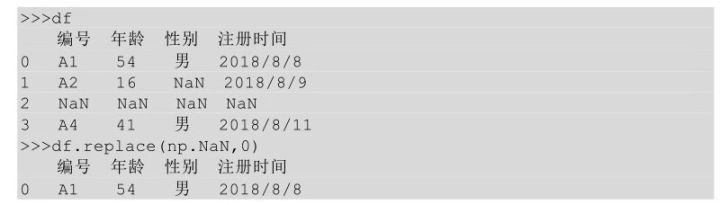

Np.NaN是python中对缺失值的一种表示方法。
2、多对一替换
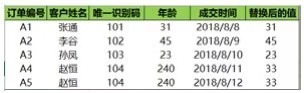
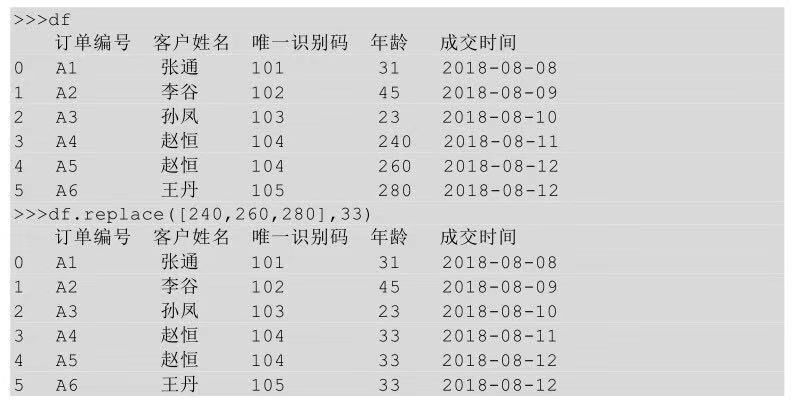
多对一替换就是把一块区域中的多个值替换成某一个值,已知现在有三个异常年龄(240、260、280)需要把这三个年龄都替换成正常范围年龄的平均值33,该怎么实现呢?
(1)Excel实现
在Excel中需要借助if函数来实现多对一替换。一直年龄这一列是D列,要想对这个异常值进行替换,可以通过如下函数实现。

上面的公式借助了Excel中的OR()函数,表示如果D列等于240、260、或者280时,该单元格的值为33,否则为D列的值。替换后的结果如下图所示。
(2)Python实现
在 Python 中实现多对一的替换比较简单,同样也是利用replace()方法,replace([A,B],C)表示将A、B替换成C。
3、多对多替换
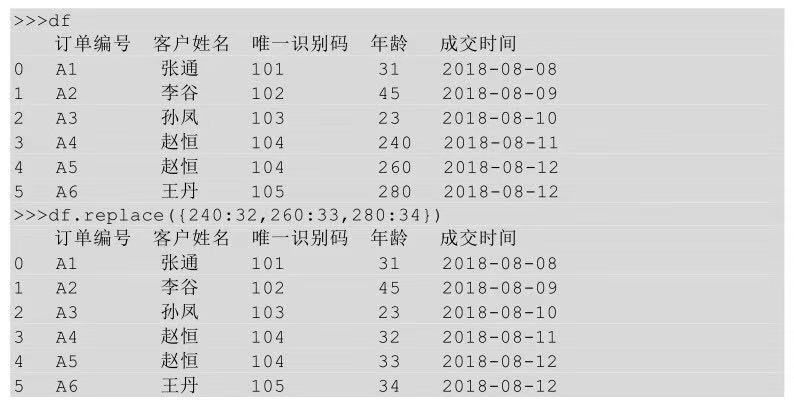
多对多替换其实就是某个区域中多个一对一的替换。比如将年龄异常值240替换成平均值减一,260替换成平均值,280替换成平均值加一,该怎么实现呢?
(1)Excel实现
若想在Excel中实现,需要借助函数,且需要多个if嵌套语句来实现,同时已知年龄列为D列,具体函数如下:
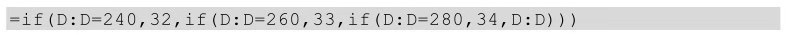
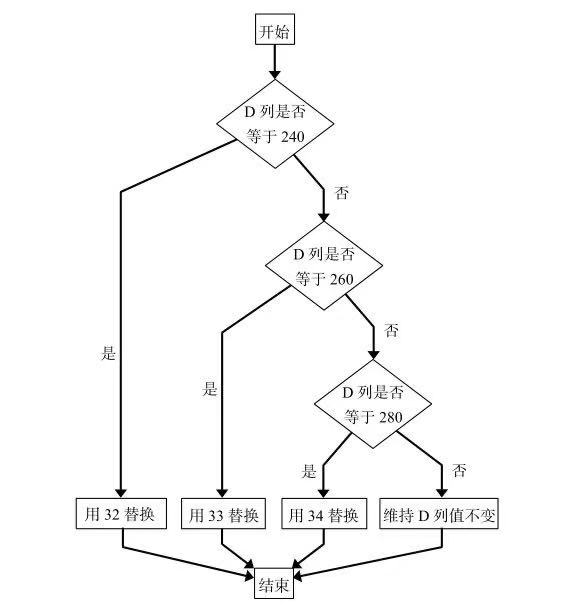
下图为该函数执行的流程。
替换后的结果如下图所示:

(2)Python实现
在Python中若想实现多对多的替换,同样是借助replace()方法,将替换值与待替换值用字典的形式表示,replace(“A”:“a”,“B”:“b”)表示用a替换A,用b 替换B。
二、数值排序
数值排序是按照具体数值的大小进行排序的,有升序和降序两种,升序就是数值由小到大排列,降序是数值由大到小排列。
1、按照一列数值进行排序
按照一列数值进行排序就是整个数据表都以某一列为准,进行升序或者降序排列。
(1)Excel实现
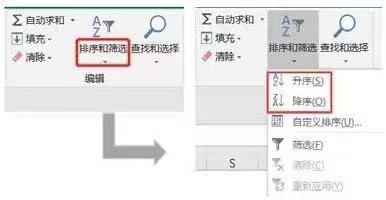
在Excel中想要按照某列进行数值排序,只要选中这一列的字段名,然后单击编辑菜单栏下的排序和筛选按钮;在下拉菜单中选择升序或者降序选项即可,操作流程如下图所示。
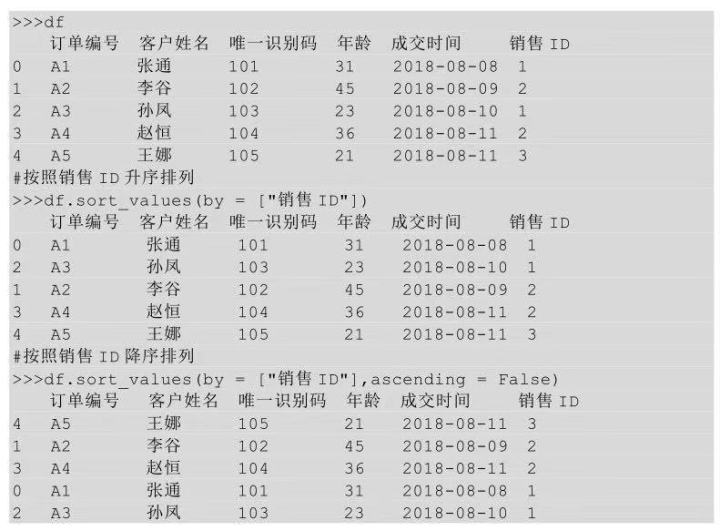
按照销售ID进行升序排列前后的结果如下图所示:

(2)Python实现
在Python中我们若想按照某列进行排序,需要用到sort_values()方法,在sort_values后的括号中指明要排序的列名,以及升序还是降序排序。

上面代码表示df表按照col1列进行排序,ascending = False表示按照col1列进行降序排列。Ascending参数默认值为True,表示升序排列。所以,如果是要根据col1进行升序排序,则可以只指明列名,不需要额外声明排序方式。

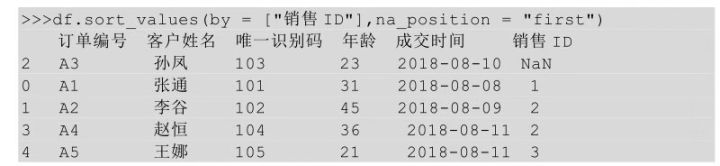
2、按照有缺失值的列进行排序
(1)Python实现
在Python中,当待排序的列中有缺失值时,可以通过设置na_position参数对缺失值的显示位置进行设置,默认参数值为last,可以不写,表示将缺失值显示在最后。
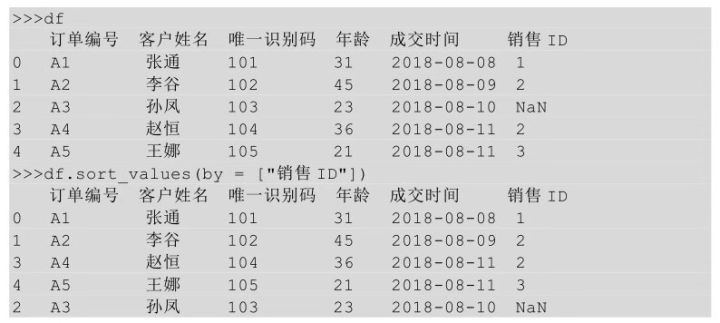
通过设置na_position参数将缺失值显示在最前面。
3、按照多列数值进行排序
按照多列数值排序是指同时依据多列数据进行升序、降序排序,当第一列出现重复值时按照第二列进行排序,当第二天出现重复值时按照第三列进行排序,以此类推。
(1)Excel实现
在Excel中实现按照多列排序,选中待排序的所有数据,单击编辑菜单栏下的排序和筛选按钮,在下拉菜单中选择自定义排序选项就会出现如下图所示界面。添加条件就是添加按照排序的列,在次序里面可以单独定义每一列的升序或者降序。
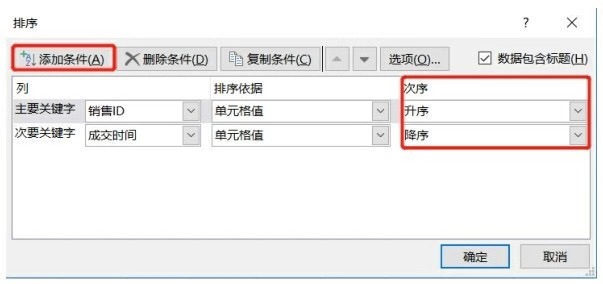
举个例子,对下图左侧的Before表先按照销售ID升序排列,当遇到重复的销售ID时,再按成交时间降序排列,得出下图右侧的After表。

(2)Python实现
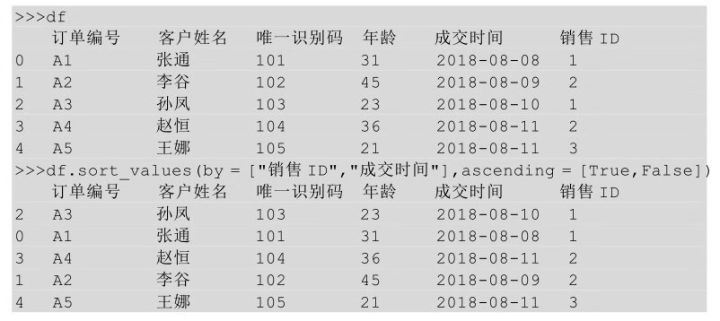
在Python中实现按照多列进行排序,用到的方法同样是sort_values(),只要sort_values()后的括号中以列表的形式指明要排序的多列列名及每列的排序方式即可。
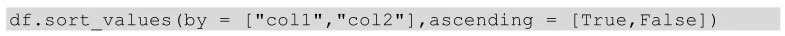
上面代码表示df表现按照col1列进行升序排列,当col1 列遇到重复值时,再按照col2列进行降序排列。对于表df我们依旧先按照销售ID升序排列,当遇到重复的销售ID时,再按照成交时间降序排列,代码如下图所示:
三、数值排名
数值排名和数值排序是相对应的,排名会新增一列,这一列用来存放数据的排名情况,排名是从1开始的
(1)Excel实现
在Excel中用于排名的函数有RANK.AVG()和RANK.EQ()两个。
当待排名的数值没有重复值时,这两个函数的效果是完全一样的,两个函数的不同在于处理重复值方式不同。
●RANK.AVG(number,ref,order)
number表示待排名的数值,ref表示一整列数值的范围,order用来指明降序还是升序排名。当待排名的数值由重复值时,返回重复值的平均排名。
对销售ID进行平均排名以后的结果如下图所示。图中销售ID为1的值有两个,假设一个排名是1,另一个排名是2,那么二者的均值就是1.5,所以平均排名就是1.5;销售ID为2的值同样有两个,同样假设一个排名为3 ,另一个排名为4,那么二者的均值是3.5;销售ID为3的值没有重复值,所以排名就是5。
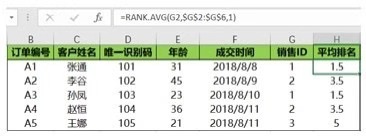
●RANK.EQ(number,ref,order)
RANK.EQ的参数与RANK.AVG的意思是一样的。当待排名的数值有重复值时,RANK.EQ返回重复值的最佳排名。
对销售ID进行最佳排名以后的结果如下图所示。图中销售ID为1的值有两个,第一个重复值的排名为1,所以两个值的最佳排名均为1 ;销售ID为2的值也有两个,第一个重复值的排名为3,所以两个值的最佳排名均为3,;销售ID为3的值没有重复值,最佳排名为5。

(2)Python实现
在Python中对数值进行排名,小用到rank()方法。Rank()方法主要有两个参数,一个是ascending,用来指明升序排列还是降序排列,默认升序排列,和Excel中的order的意思一致;另一个是method,用来指明待排列值有重复值时的处理情况。下表是参数method可取的不同参数值及说明。
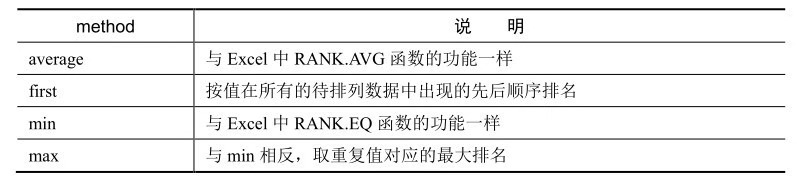
method取值为average时的排名情况,与Excel中RANK.AVG函数一致。

method取值为first时的排名情况,销售ID为1的值有两个,第一个出现的排名为1,第二个出现的排名为2;销售ID为2的以此类推。

method取值为min时的排名情况,与Excel中RANK.EQ函数一致。

method取值为max时的排名情况,与method取值min时相反,销售ID为1的值有两个,第二个重复值的排名为2,所以两个值的排名均为2;销售ID为2的值有两个,两个重复值的排名为4,所以两个值的排名均为4。

四、数值删除
数值删除是对数据表中一些无用的数据进行删除操作。
1、删除列
(1)Excel实现
在Excel中,要删除某一列或某几列,只需要选中这些列,然后单击鼠标右键,在弹出的菜单中选择删除选项即可(或者单击鼠标右键以后按D键),如下图所示。
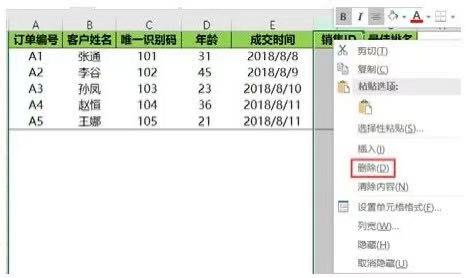
(2)Python实现
在Python中,要删除某列,用到的是drop()方法,即在drop方法后的括号中指明要删除的列名或者列的位置,即第几列。
在drop方法后的括号中直接传入待删除列的列名,需要加一个参数axis,并让其参数值等于1,表示删除列。

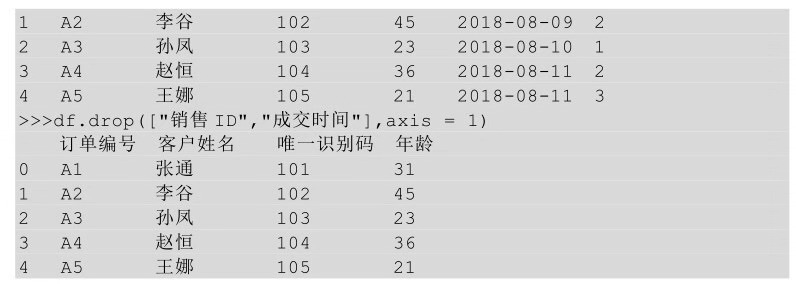
还可以在drop方法后的括号中直接传入待删除列的位置,但也需要用axis参数。
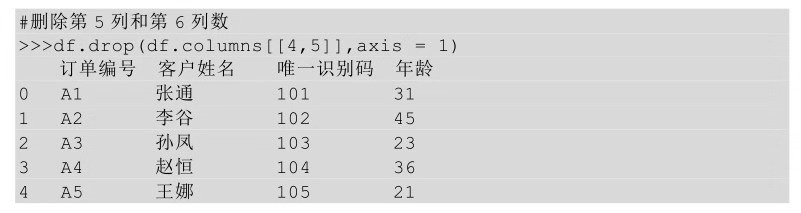
也可以将列名以列表的形式传给columns参数,这个时候就不需要axis参数了。
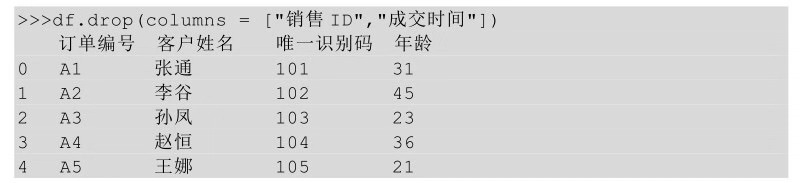
2、删除行
(1)Excel实现
在 Excel 中,要删除某些行使用的方法与删除列是一致的,先选中要删除的行,然后单击鼠标右键,在弹出的下拉菜单中选择删除选项就可以删除行了。
(2)Python实现
在Python中,要删除某些行用到的方法依然是drop(),与删除列类似的是,删除行也要指明行相关的信息。
在drop方法后的括号中直接传入待删除行的行名,并让axis参数值等于0,表示删除行。
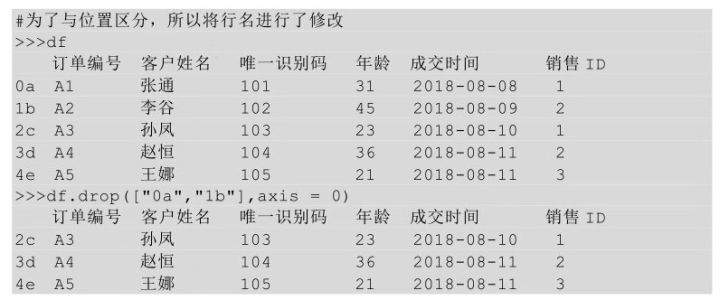
除了传入行索引名称,还可以在drop方法后的括号中直接传入待删除行的行号,也需要用axis参数,并让其参数值等于0。
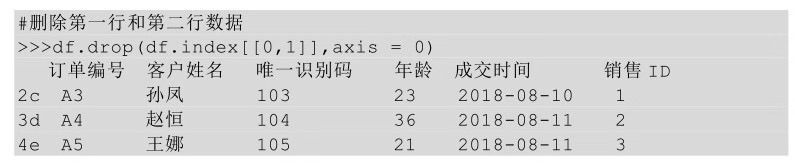
也可以将待删除行的行名传给index参数,这个时候就不需要axis参数了。
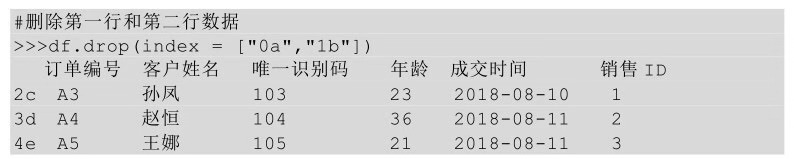
3、删除特定行
删除特定行一般指删除满足某个条件的行,我们前面的异常值删除算是删除特定的行。
(1)Excel实现
在Excel中删除特定行分为两步,第一步先将符合条件的行筛选出来,第二步选中这些筛选出来的行然后单击鼠标右键,在弹出的下拉菜单中选择删除选项。
(2)Python实现
在Python中删除特定行使用的方法有些特殊,我们不直接删除满足条件的值,而是把不满足条件的值筛选出来作为新的数据源,这样就把要删除的行过滤掉了。
在如下例子中,要删除年龄值大于等于40对应的行,我们并不直接删除这一部分,而是把它的相反部分取出来,即把年龄小于40的行筛选出来作为新的数据源。

五、数值计数
数值计数就是计算某个值在一系列数值中出现的次数。
(1)Excel实现
在Excel中实现数值计数,我们使用的是COUNTIF()函数,COUNTIF()函数用来计算某个区域中满足给定条件的单元格数目。

range表示一系列值的范围,criteria表示某一个值或者某一个条件。
销售ID的值的计数结果如下图所示。销售ID为1的值在F2:F6这个范围内出现了两次;销售ID为2的值在该范围内也出现了两次;销售ID为3的值出现了1次。

(2)Python实现
在Python中,要对某些值的出现次数进行计数,我们用到的方法是value_counts()。

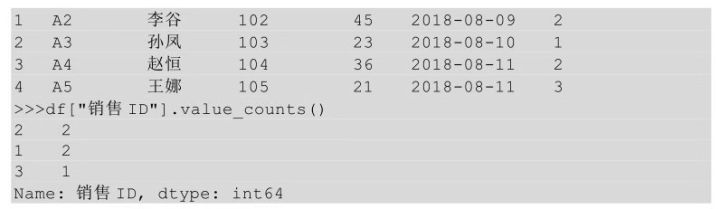
上面代码运行的结果表示销售ID为2的值出现了两次,销售ID为1的值出现了两次,销售ID为3的值出现了1次。这些是值出现的绝对次数,还可以看一下不同值出现的占比,只需要给value_counts()方法传入参数normalize = True即可。

上面代码的运行结果表示销售ID为2的值的占比为0.4,销售ID为1的值的占比为0.4,销售ID为3的值的占比为0.2。上面销售ID的排序是2、1、3,这是按照计数值降序排列的(0.4、0.4、0.2),通过设置sort=False可以实现不按计数值降序排列。

六、唯一值获取
唯一值获取就是把某一系列值删除重复项以后的结果,一般可以将表中某一列认为是一系列值。
(1)Excel实现
在Excel中,我们若想查看某一列数值中的唯一值,可以把这一列数值复制粘贴出来,然后删除重复项,剩下的就是唯一值了。
(2)Python实现
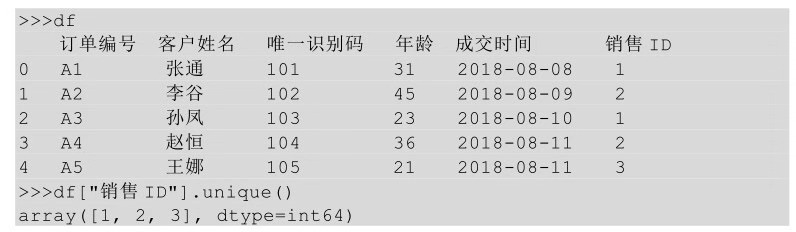
在Python中,我们要获取一列值的唯一值,整体思路与Excel的是一致的,先把某一列的值复制粘贴出来,然后用删除重复项的方法实现,关于删除重复项在前面讲过了,本节用另一种获取唯一值的方法unique()实现。
举个例子,对表df中的销售ID取唯一值,先把销售ID取出来,然后利用unique()方法获取唯一值,代码如下所示。
七、数值查找
数值查找就是查看数据表中的数据是否包含某个值或者某些值。
(1)Excel实现
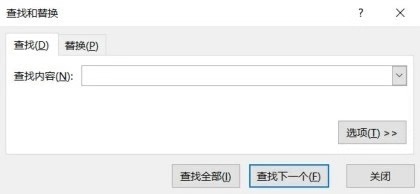
在Excel中我们要想查看数据表中是否包含某个值可以直接利用查找功能。首先要把待查找区域选中,可以选择一列或者多列,如果不选,则默认在全表中查询,然后单击编辑菜单栏的查找和选择按钮,在下拉菜单中选择查找选项,如下图所示。
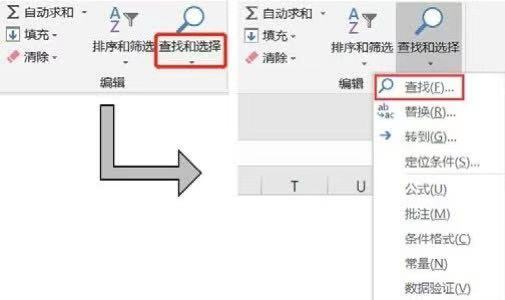
下图为选择查找选项后弹出的查找和替换对话框(也可以使用快捷键Ctrl+F打开查找和替换对话框),在查找内容框输入要查找的内容即可,可以选择查找全部,这样就会把所有查找到的内容显示出来;也可以选择查找下一个,这样会把查找结果一个一个显示出来。
(2)Python实现
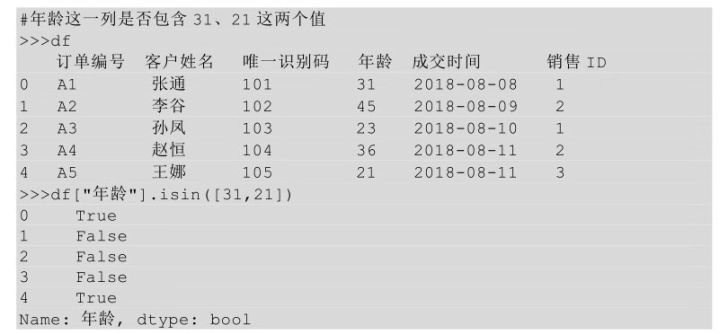
在Python中查看数据表中是否包含某个值用到的是isin()方法,而且可以同时查找多个值,只需要在isin方法后的括号中指明即可。
可以将某列数据取出来,然后在这一列上调用 isin()方法,看这一列中是否包含某个/些值,如果包含则返回True,否则返回False。
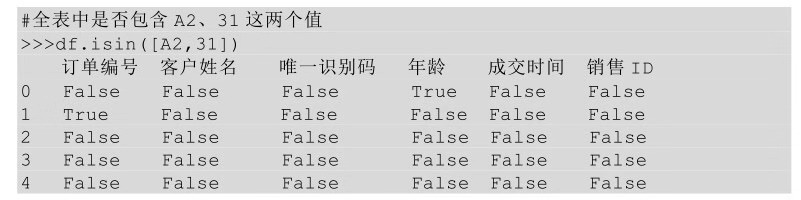
也可以针对全表查找是否包含某个值。
八、区间切分
区间切分就是将一系列数值分成若干份,比如现在有10个人,你要根据这10个人的年龄将他们分为三组,这个切分过程就称为区间切分。
(1)Excel实现
在Excel中实现区间切分我们借助的是if函数,具体公式如下:
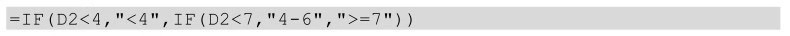
if函数的实现流程如下图所示。
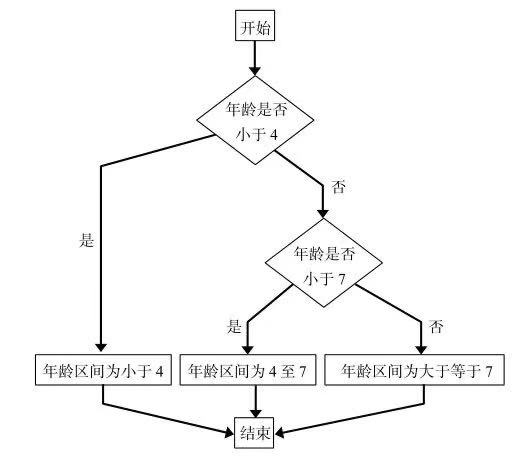
下图为利用if嵌套函数实现的结果。

(2)Python实现
在Python中对区间切分利用的是cut()方法,cut()方法有一个参数bins用来指明切分区间。
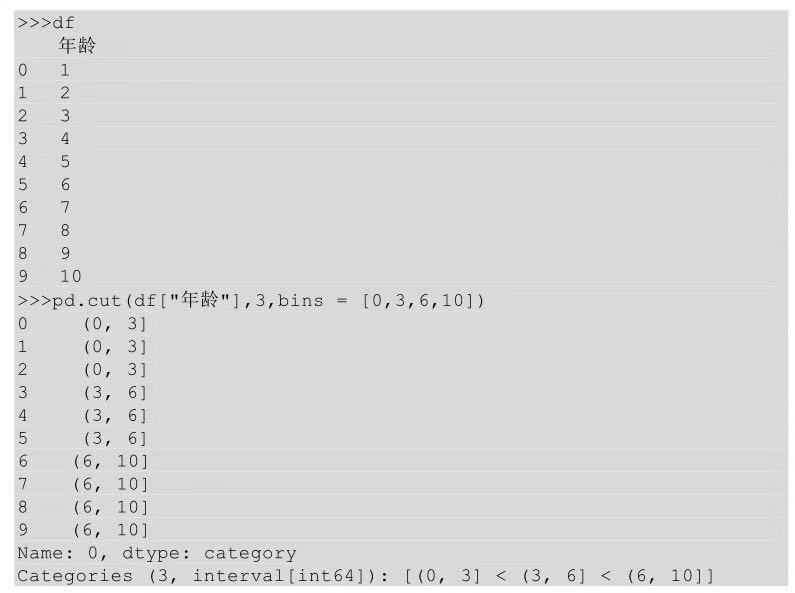
cut()方法的切分结果是几个左开右闭的区间,(0,3]就表示大于0小于等于3,(3,6]表示大于3小于等于6,(6,10]表示大于6小于等于10。
与cut()方法类似的还有qcut()方法,qcut()方法不需要事先指明切分区间,只需要指明切分个数,即你要把待切分数据切成几份,然后它就会根据待切分数据的情况,将数据切分成事先指定的份数,依据的原则就是每个组里面的数据个数尽可能相等。


在数据分布比较均匀的情况下,cut()方法和 qcut()方法得到的区间基本一致,当数据分布不均匀,即方差比较大时,两者得到的区间的偏差就会比较大。
九、插入新的行或列
在特定的位置插入行或者列也是比较常用的操作。具体的插入操作有两个关键要素,一个是在哪插入,另一个是插入什么。
(1)Excel实现
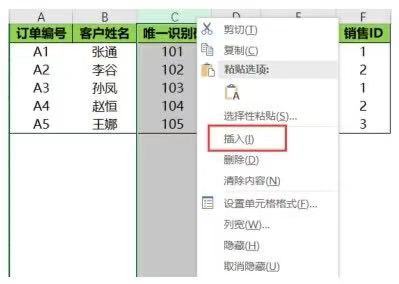
在Excel中要插入行或列首先要确定在哪一行或哪一列前面插入,然后选中这一列或这一行单击鼠标右键,在弹出的下拉菜单中选择插入选项即可。
要在唯一识别码列前面插入一列,选中唯一识别码这一列然后单击鼠标右键,在弹出的下拉菜单中选择插入选项即可,如下图所示。
完成上面的操作后,就会有一个新的空行或空列,在空行或空列里面输入要插入的数据即可。
(2)Python实现
在Python中没有专门用来插入行的方法,可以把待插入的行当作一个新的表,然后将两个表在纵轴方向上进行拼接。关于表拼接在后面的章节会讲。
在Python中插入一个新的列用到的方法是insert(),在insert方法后的括号中指明要插入的位置、插入后新列的列名,以及要插入的数据。

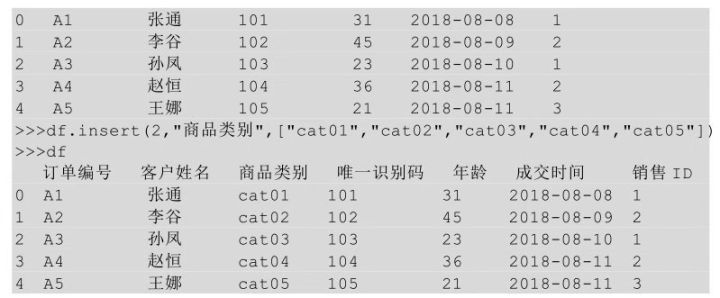
还可以直接以索引的方式进行列的插入,直接让新的一列等于某列值即可。

上面的代码表示新插入一列名为商品类别的值,这一列的值就是后面列表中的值。
十、行列互换
所谓的行列互换(又称转置)就是将行数据转换到列方向上,将列数据转换到行方向上。
(1)Excel实现
在Excel中行列互换(转置)需要先把待转置的内容复制,然后粘贴在新的区域中,粘贴选项选择转置即可,转置选项如下图所示。
转置前后的效果对比如下图所示。

(2)Python实现
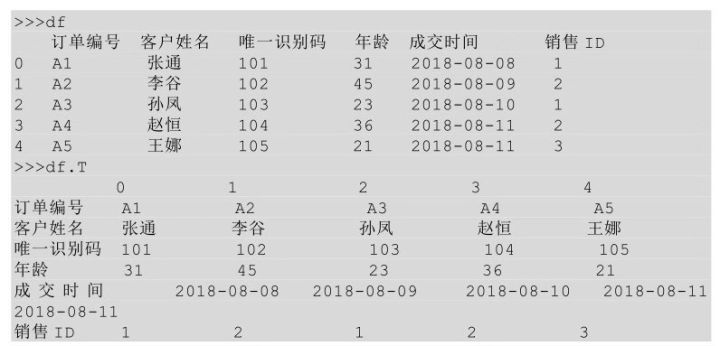
在 Python 中,我们直接在源数据表的基础上调用.T 方法即可得到源数据表转置后的结果。对转置后的结果再次转置就会回到原来的结果。
对表df进行转置,代码如下所示。
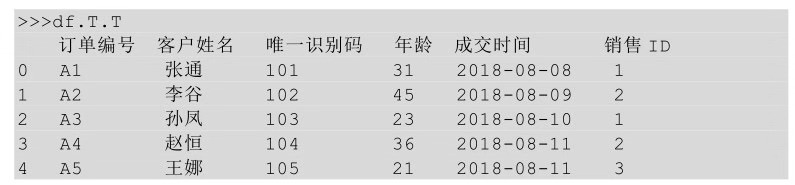
对转后的表再次进行转置,代码如下所示。
十一、索引重塑
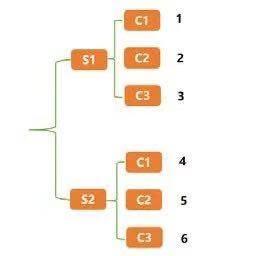
所谓的索引重塑就是将原来的索引进行重新构造。典型的DataFrame结构的表如下表所示。

上面这种表是典型的DataFrame结构,它用一个行索引和一个列索引来确定一个唯一值,比如S1-C1唯一值为1,S2-C3唯一值为6。这种通过两个位置确定一个唯一值的方法不仅可以用上述这种表格型结构表示,而且可以用一种树形结构来表示,如下图所示。
树形结构其实就是在维持表格型行索引不变的前提下,把列索引也变成行索引,其实就是给表格型数据建立层次化索引。
我们把数据从表格型数据转换到树形数据的过程叫重塑,这种操作在Excel中没有,在Python用到的方法是stack(),示例代码如下所示。

与stack()方法相对应的方法是unstack()方法,stack()方法是将表格型数据转化为树形数据,而unstack()方法是将树形数据转为表格型数据,示例代码如下所示。

十二、长宽表转换
长宽表转换就是将比较长(很多行)的表转换为比较宽(很多列)的表,或者将比较宽的表转化为比较长的表。
下表是一个宽表(有很多列)。

我们要把这个宽表转化为如下表所示的长表。
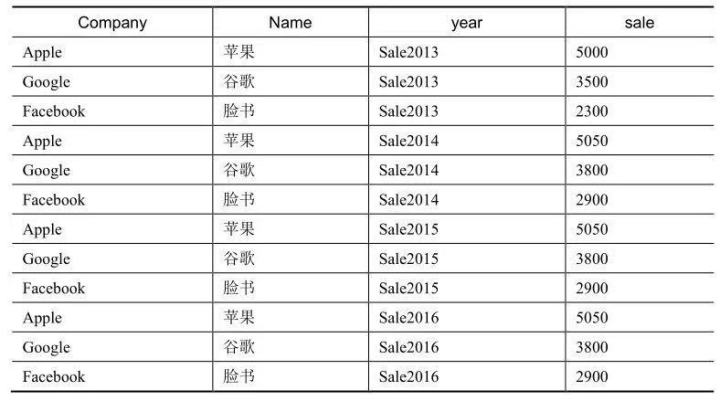
上面这种由很多列转换为很多行的过程,就是宽表转换为长表的过程,这种转换过程是有前提的,那就是需要有公共列。
1、宽表转换为长表
宽表转化为长表,在Excel中一般都用复制粘贴实现,我们主要看看在Python中如何实现。Python中要实现这种转换有两种方法,一种是stack()方法,另一种是melt()方法。
(1)stack()方法实现
stack()在将表格型数据转为树形数据时,是在保持行索引不变的前提下,将列索引也变成行索引。
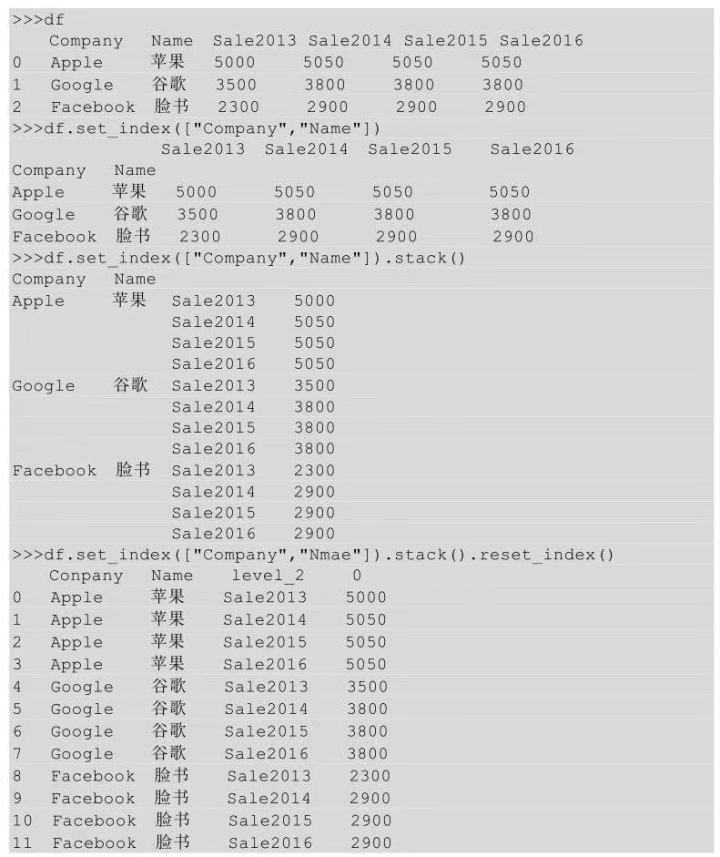
这里将宽表转化为长表首先要在保持 Company 和 Name 不变的前提下,将Sale2013、Sale2014、Sale2015、Sale2016也变成行索引。所以,需要先将 Company和Nmae先设置成索引,然后调用stack()方法,将列索引也转换成行索引,最后利用reset_index()方法进行索引重置,示例代码如下所示。
(2)melt()方法实现
用melt()方法实现上述功能,代码如下所示。
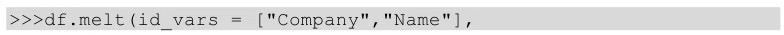
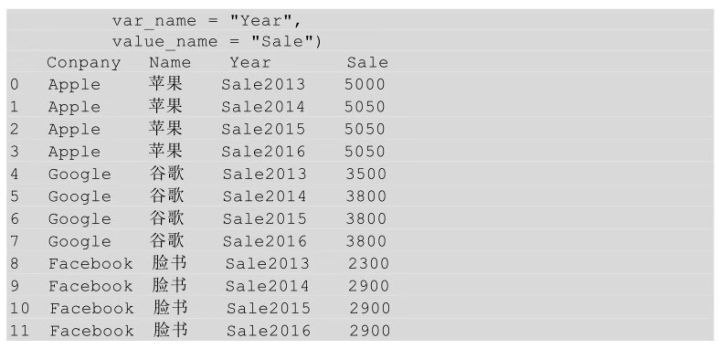
melt中的id_vars参数用于指明宽表转换到长表时保持不变的列,var_name参数表示原来的列索引转化为“行索引”以后对应的列名,value_name表示新索引对应的值的列名。
注意,这里的“行索引”是有双引号的,它并非实际行索引,只是类似实际的行索引。
2、长表转换为宽表
将长表转化为宽表就是宽表转化为长表的逆过程。常用的方法就是数据透视表,关于数据透视表的使用我们将在10.2节进行详细讲解,这里大概了解一下就行,具体实现如下:
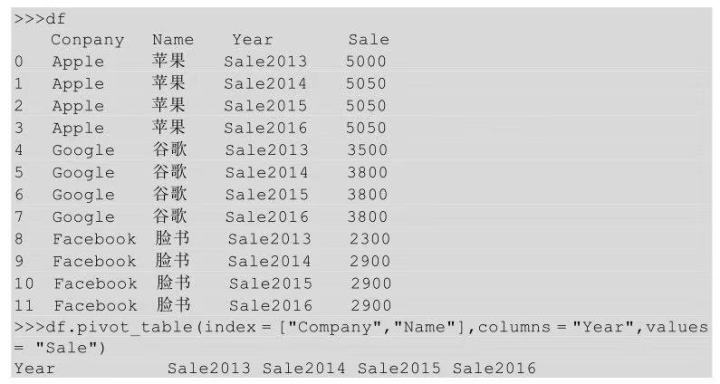

上面的实现过程是把Company和Name设置成行索引,Year设置成列索引,Sale为值。
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;












 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330