决策树算法借助于树的分支结构实现分类。下图是一个决策树的示例,树的内部结点表示对某个属性的判断,该结点的分支是对应的判断结果;叶子结点代表一个类标。

上表是一个预测一个人是否会购买购买电脑的决策树,利用这棵树,我们可以对新记录进行分类,从根节点(年龄)开始,如果某个人的年龄为中年,我们就直接判断这个人会买电脑,如果是青少年,则需要进一步判断是否是学生;如果是老年则需要进一步判断其信用等级,直到叶子结点可以判定记录的类别。
决策树算法有一个好处,那就是它可以产生人能直接理解的规则,这是贝叶斯、神经网络等算法没有的特性;决策树的准确率也比较高,而且不需要了解背景知识就可以进行分类,是一个非常有效的算法。决策树算法有很多变种,包括ID3、C4.5、C5.0、CART等,但其基础都是类似的。下面来看看决策树算法的基本思想:
算法:GenerateDecisionTree(D,attributeList)根据训练数据记录D生成一棵决策树.
输入:数据记录D,包含类标的训练数据集;
属性列表attributeList,候选属性集,用于在内部结点中作判断的属性.
属性选择方法AttributeSelectionMethod(),选择最佳分类属性的方法.
输出:一棵决策树.
过程:
构造一个节点N;
如果数据记录D中的所有记录的类标都相同(记为C类):
则将节点N作为叶子节点标记为C,并返回结点N;
如果属性列表为空:
则将节点N作为叶子结点标记为D中类标最多的类,并返回结点N;
调用AttributeSelectionMethod(D,attributeList)选择最佳的分裂准则splitCriterion;
将节点N标记为最佳分裂准则splitCriterion;
如果分裂属性取值是离散的,并且允许决策树进行多叉分裂:
从属性列表中减去分裂属性,attributeLsit -= splitAttribute;
对分裂属性的每一个取值j:
记D中满足j的记录集合为Dj;
如果Dj为空:
则新建一个叶子结点F,标记为D中类标最多的类,并且把结点F挂在N下;
否则:
递归调用GenerateDecisionTree(Dj,attributeList)得到子树结点Nj,将Nj挂在N下;
返回结点N;
算法的1、2、3步骤都 很显然,第4步的最佳属性选择函数会在后面专门介绍,现在只有知道它能找到一个准则,使得根据判断结点得到的子树的类别尽可能的纯,这里的纯就是只含有一个类标;第5步根据分裂准则设置结点N的测试表达式。在第6步中,对应构建多叉决策树时,离散的属性在结点N及其子树中只用一次,用过之后就从可用属性列表中删掉。比如前面的图中,利用属性选择函数,确定的最佳分裂属性是年龄,年龄有三个取值,每一个取值对应一个分支,后面不会再用到年龄这个属性。算法的时间复杂度是O(k*|D|*log(|D|)),k为属性个数,|D|为记录集D的记录数。
很显然,第4步的最佳属性选择函数会在后面专门介绍,现在只有知道它能找到一个准则,使得根据判断结点得到的子树的类别尽可能的纯,这里的纯就是只含有一个类标;第5步根据分裂准则设置结点N的测试表达式。在第6步中,对应构建多叉决策树时,离散的属性在结点N及其子树中只用一次,用过之后就从可用属性列表中删掉。比如前面的图中,利用属性选择函数,确定的最佳分裂属性是年龄,年龄有三个取值,每一个取值对应一个分支,后面不会再用到年龄这个属性。算法的时间复杂度是O(k*|D|*log(|D|)),k为属性个数,|D|为记录集D的记录数。
三、属性选择方法
属性选择方法总是选择最好的属性最为分裂属性,即让每个分支的记录的类别尽可能纯。它将所有属性列表的属性进行按某个标准排序,从而选出最好的属性。属性选择方法很多,这里我介绍三个常用的方法:信息增益(Information gain)、增益比率(gain ratio)、基尼指数(Gini index)。
信息增益(Information gain)
信息增益基于香浓的信息论,它找出的属性R具有这样的特点:以属性R分裂前后的信息增益比其他属性最大。这里信息的定义如下:
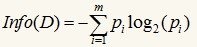
其中的m表示数据集D中类别C的个数,Pi表示D中任意一个记录属于Ci的概率,计算时Pi=(D中属于Ci类的集合的记录个数/|D|)。Info(D)表示将数据集D不同的类分开需要的信息量。
如果了解信息论,就会知道上面的信息Info实际上就是信息论中的熵Entropy,熵表示的是不确定度的度量,如果某个数据集的类别的不确定程度越高,则其熵就越大。比如我们将一个立方体A抛向空中,记落地时着地的面为f1,f1的取值为{1,2,3,4,5,6},f1的熵entropy(f1)=-(1/6*log(1/6)+…+1/6*log(1/6))=-1*log(1/6)=2.58;现在我们把立方体A换为正四面体B,记落地时着地的面为f2,f2的取值为{1,2,3,4},f2的熵entropy(1)=-(1/4*log(1/4)+1/4*log(1/4)+1/4*log(1/4)+1/4*log(1/4)) =-log(1/4)=2;如果我们再换成一个球C,记落地时着地的面为f3,显然不管怎么扔着地都是同一个面,即f3的取值为{1},故其熵entropy(f3)=-1*log(1)=0。可以看到面数越多,熵值也越大,而当只有一个面的球时,熵值为0,此时表示不确定程度为0,也就是着地时向下的面是确定的。
有了上面关于熵的简单理解,我们接着讲信息增益。假设我们选择属性R作为分裂属性,数据集D中,R有k个不同的取值{V1,V2,…,Vk},于是可将D根据R的值分成k组{D1,D2,…,Dk},按R进行分裂后,将数据集D不同的类分开还需要的信息量为:

信息增益的定义为分裂前后,两个信息量只差:

信息增益Gain(R)表示属性R给分类带来的信息量,我们寻找Gain最大的属性,就能使分类尽可能的纯,即最可能的把不同的类分开。不过我们发现对所以的属性Info(D)都是一样的,所以求最大的Gain可以转化为求最新的InfoR(D)。这里引入Info(D)只是为了说明背后的原理,方便理解,实现时我们不需要计算Info(D)。举一个例子,数据集D如下:
|
记录ID
|
年龄
|
输入层次
|
学生
|
信用等级
|
是否购买电脑
|
|
1
|
青少年
|
高
|
否
|
一般
|
否
|
|
2
|
青少年
|
高
|
否
|
良好
|
否
|
|
3
|
中年
|
高
|
否
|
一般
|
是
|
|
4
|
老年
|
中
|
否
|
一般
|
是
|
|
5
|
老年
|
低
|
是
|
一般
|
是
|
|
6
|
老年
|
低
|
是
|
良好
|
否
|
|
7
|
中年
|
低
|
是
|
良好
|
是
|
|
8
|
青少年
|
中
|
否
|
一般
|
否
|
|
9
|
青少年
|
低
|
是
|
一般
|
是
|
|
10
|
老年
|
中
|
是
|
一般
|
是
|
|
11
|
青少年
|
中
|
是
|
良好
|
是
|
|
12
|
中年
|
中
|
否
|
良好
|
是
|
|
13
|
中年
|
高
|
是
|
一般
|
是
|
|
14
|
老年
|
中
|
否
|
良好
|
否
|
这个数据集是根据一个人的年龄、收入、是否学生以及信用等级来确定他是否会购买电脑,即最后一列“是否购买电脑”是类标。现在我们用信息增益选出最最佳的分类属性,计算按年龄分裂后的信息量:
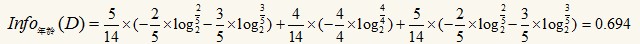
整个式子由三项累加而成,第一项为青少年,14条记录中有5条为青少年,其中2(占2/5)条购买电脑,3(占3/5)条不购买电脑。第二项为中年,第三项为老年。类似的,有:
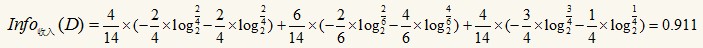
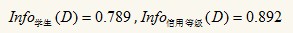
可以得出Info年龄(D)最小,即以年龄分裂后,分得的结果中类标最纯,此时已年龄作为根结点的测试属性,根据青少年、中年、老年分为三个分支:

注意,年龄这个属性用过后,之后的操作就不需要年龄了,即把年龄从attributeList中删掉。往后就按照同样的方法,构建D1,D2,D3对应的决策子树。ID3算法使用的就是基于信息增益的选择属性方法。
增益比率(gain ratio)
信息增益选择方法有一个很大的缺陷,它总是会倾向于选择属性值多的属性,如果我们在上面的数据记录中加一个姓名属性,假设14条记录中的每个人姓名不同,那么信息增益就会选择姓名作为最佳属性,因为按姓名分裂后,每个组只包含一条记录,而每个记录只属于一类(要么购买电脑要么不购买),因此纯度最高,以姓名作为测试分裂的结点下面有14个分支。但是这样的分类没有意义,它每一任何泛化能力。增益比率对此进行了改进,它引入一个分裂信息:
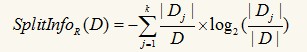
增益比率定义为信息增益与分裂信息的比率:
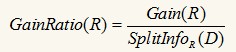
我们找GainRatio最大的属性作为最佳分裂属性。如果一个属性的取值很多,那么SplitInfoR(D)会大,从而使GainRatio(R)变小。不过增益比率也有缺点,SplitInfo(D)可能取0,此时没有计算意义;且当SplitInfo(D)趋向于0时,GainRatio(R)的值变得不可信,改进的措施就是在分母加一个平滑,这里加一个所有分裂信息的平均值:
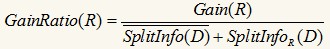
基尼指数(Gini index)
基尼指数是另外一种数据的不纯度的度量方法,其定义如下:

其中的m仍然表示数据集D中类别C的个数,Pi表示D中任意一个记录属于Ci的概率,计算时Pi=(D中属于Ci类的集合的记录个数/|D|)。如果所有的记录都属于同一个类中,则P1=1,Gini(D)=0,此时不纯度最低。在CART(Classification and Regression Tree)算法中利用基尼指数构造二叉决策树,对每个属性都会枚举其属性的非空真子集,以属性R分裂后的基尼系数为:

D1为D的一个非空真子集,D2为D1在D的补集,即D1+D2=D,对于属性R来说,有多个真子集,即GiniR(D)有多个值,但我们选取最小的那么值作为R的基尼指数。最后:
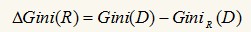
我们转Gini(R)增量最大的属性作为最佳分裂属性。











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330