大数据之基于模型的复杂数据多维聚类析(一)
随着现实和虚拟世界的数据产生速度越来越迅猛,人们开始关注如何从这些数据中获取信息,知识,以及对于决策的支持。这样的任务通常被称作大数据分析(BigData Analytics)。大数据分析的难点很多,比如,由于海量数据而带来的分析效率瓶颈,使用户不能及时得到分析结果;由于数据源太多而带来的非结构化问题,使传统的数据分析工具不能直接利用。
本文讨论大数据内部关系的复杂性,以及复杂数据所带来的对于聚类分析的挑战。聚类分析的目标是依据数据本身的分布特征(无监督),把整个数据(空间)划分成不同的类。基本的准则是同类的数据应该具有某种的相似性,而异类的数据应该具有某种差异性。现有工作假设在这些数据中存在单一的聚类划分的方法,而聚类目标就是找到这样的一种划分。然而,我们在大数据中所面对的复杂数据是多侧面的,比如在网页数据中既有关于内容的文本属性,也有指向这个网页的链接属性。多侧面数据本身就存在着多种有意义的划分,强制地将数据按照单一的方法聚类,得不到有效的、明确清晰的、可诠释的结果。针对这个问题,多维聚类方法针对数据的不同侧面,得到数据聚类的多种方法,最后让使用者决定需要的聚类划分。
多维聚类的概念
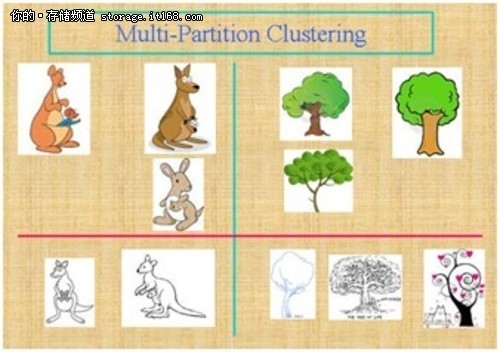
假设我们需要对图中的所有图片进行聚类,可能的聚类方法不止一种:按照图片的内容,我们可以把左边的图片标注成袋鼠,而右边的标注成树;而按照图片风格属性,我们可以把上面的图片称为色彩图,而下面的称为线条图。简而言之,关注数据的不同侧面,有可能得到不同的聚类结果。同时这些聚类结果也都是有意义,可以解释的。
生活中多维聚类的例子很多,比如对于人群的划分,可以按照男女等人口统计学信息划分,也可以按照对于某个事件的看法划分。那么从机器学习的角度如何公式化这样的问题,之后又怎么利用概率统计的方法去解决这样的问题呢?下面我们先给出问题的定义。
如图所示,在聚类分析这样的无监督学习中,输入是一个数据表。表的每一行表示一个数据点,而每一列表示描述这个点的一维属性。大数据的一个重要特征就是维度很高(包含很多列),从而带来的维度灾难(curseof dimensionality)。在聚类分析中,表现为:这些维度可能自然地分成一些组,每组包含一些属性,反应了数据某一侧面(facet)的特征。用户可以根据其中一个侧面的属性,对这个数据进行聚类。比如在右表的数据中,一个学生的数据包含了数学成绩,理综成绩,文综成绩,和语文成绩这些属性。我们可以关注学生的数学和理综成绩,按照理科成绩(分析能力)对学生进行聚类;同时也可以关注学生的文综和语文成绩,按照文科成绩(语言能力)对学生进行聚类。
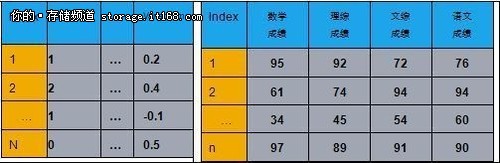
所以多维聚类的问题定义为:
如何发现数据中包含的多个侧面,即属性的自然分组,针对这些不同侧面进行聚类,从而得到多种聚类方法。
多维聚类分析的工具和原理
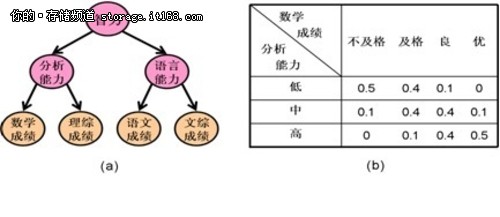
贝叶斯网络是一种表示和处理随机变量之间复杂关系的工具。它是通过在随机变量之间加箭头而得到的有向无圈图。箭头表示直接概率依赖关系,具体依赖情况由条件概率分布所定量刻画。出于对计算复杂度的考虑,人们会对贝叶斯网络进行一些限制,在实际中使用一些特殊的网络结构。隐树模型(latent tree model)是一类特殊的贝叶斯网,也称为多层隐类模型(hierarchical latent class model), 是一种树状贝叶斯网, 其中叶节点代表观察到的变量,也称为显变量,其它节点代表数据中没有观察到的变量,也称为隐变量。
图中给出了隐树模型的一个例子。其中,学生的“数学成绩”、“理综成绩”、“语文成绩”和“文综成绩”是显变量,而“智力”、“分析能力”和“语言能力”则是隐变量。从“分析能力”到“数学成绩”有一个箭头, 表示“数学成绩”直接依赖“分析能力”,具体依赖情况由右图中的条件概率表所定量所刻画。表中的内容是说,分析能力低的学生在数学科有0.5的概率不及格、0.4的概率及格、0.1的概率得良,而得优的概率则是0; 等等。模型中的其它箭头代表其它变量之间直接依赖关系,每个箭头都有相应的条件概率分布。
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330