《Python数据分析极简入门》 第2节 8-1 Pandas 数据重塑 - 数据变形 数据重塑(Reshaping) 数据重塑,顾名思义就是给数据做各种变形,主要有以下几种:
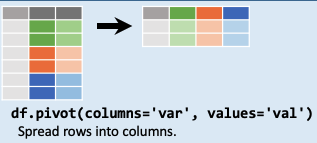
df.pivot( ) 数据变形
根据索引 (index)、列(column)(values)值), 对原有DataFrame (数据框)进行变形重塑,俗称长表转宽表
import pandas as pdimport numpy as npdf = pd.DataFrame ('姓名' : ['张三' , '张三' , '张三' , '李四' , '李四' , '李四' ],'科目' : ['语文' , '数学' , '英语' , '语文' , '数学' , '英语' ],'成绩' : [91 , 80 , 100 , 80 , 100 , 96 ]})
姓名
科目
成绩
0
张三
语文
91
1
张三
数学
80
2
张三
英语
100
3
李四
语文
80
4
李四
数学
100
5
李四
英语
96
长转宽:使用 df.pivot 以姓名为index,以各科目为columns,来统计各科成绩:
df = pd.DataFrame ('姓名' : ['张三' , '张三' , '张三' , '李四' , '李四' , '李四' ],'科目' : ['语文' , '数学' , '英语' , '语文' , '数学' , '英语' ],'成绩' : [91 , 80 , 100 , 80 , 100 , 96 ]})
姓名
科目
成绩
0
张三
语文
91
1
张三
数学
80
2
张三
英语
100
3
李四
语文
80
4
李四
数学
100
5
李四
英语
96
df.pivot(index='姓名' , columns='科目' , values='成绩' )
科目
数学
英语
语文
姓名
张三
80
100
91
李四
100
96
80
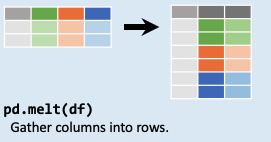
pd.melt() 数据融合 df = pd.DataFrame ('姓名' : ['张三' , '张三' , '张三' , '李四' , '李四' , '李四' ],'科目' : ['语文' , '数学' , '英语' , '语文' , '数学' , '英语' ],'成绩' : [91 , 80 , 100 , 80 , 100 , 96 ]})'姓名' , columns='科目' , values='成绩' ).reset_index()
科目
姓名
数学
英语
语文
0
张三
80
100
91
1
李四
100
96
80
宽表变长表:使用 pd.melt 以姓名为标识变量的列id_vars,以各科目为value_vars,来统计各科成绩:
df1.melt(id_vars=['姓名' ], value_vars=['数学' , '英语' , '语文' ])
姓名
科目
value
0
张三
数学
80
1
李四
数学
100
2
张三
英语
100
3
李四
英语
96
4
张三
语文
91
5
李四
语文
80
pd.pivot_table() 数据透视 random.seed(1024 )DataFrame ('专业' : np.repeat(['数学与应用数学' , '计算机' , '统计学' ], 4 ),'班级' : ['1班' ,'1班' ,'2班' ,'2班' ]*3 ,'科目' : ['高数' , '线代' ] * 6 ,'平均分' : [random.randint(60 ,100 ) for i in range(12 )],'及格人数' : [random.randint(30 ,50 ) for i in range(12 )]})
专业
班级
科目
平均分
及格人数
0
数学与应用数学
1班
高数
61
34
1
数学与应用数学
1班
线代
90
42
2
数学与应用数学
2班
高数
84
33
3
数学与应用数学
2班
线代
80
43
4
计算机
1班
高数
93
34
5
计算机
1班
线代
66
43
6
计算机
2班
高数
88
45
7
计算机
2班
线代
92
44
8
统计学
1班
高数
83
46
9
统计学
1班
线代
83
41
10
统计学
2班
高数
84
49
11
统计学
2班
线代
66
49
各个专业对应科目的及格人数和平均分
pd.pivot_table(df, index=['专业' ,'科目' ],'及格人数' ,'平均分' ],'及格人数' :np.sum,"平均分" :np.mean})
及格人数
平均分
专业
科目
数学与应用数学
线代
85
85.0
高数
67
72.5
统计学
线代
90
74.5
高数
95
83.5
计算机
线代
87
79.0
高数
79
90.5
补充说明:
df.pivot_table()和df.pivot()都是Pandas中用于将长表转换为宽表的方法,但它们在使用方式和功能上有一些区别。
使用方式:
df.pivot()方法接受三个参数:index、columns和values,分别指定新表的索引 、列和值。df.pivot_table()方法接受多个参数,其中最重要的是index、columns和values,用于指定新表的索引 、列和值。此外,还可以使用aggfunc参数指定对重复值 进行聚合操作的函数,默认为均值。
处理重复值 :
df.pivot()方法在长表中存在重复值 时会引发错误。因此,如果长表中存在重复值 ,就需要先进行去重操作,或者使用其他方法来处理重复值 。df.pivot_table()方法可以在长表中存在重复值 的情况下进行透视操作,并可以使用aggfunc参数指定对重复值 进行聚合操作的函数,默认为均值。
聚合操作:
df.pivot()方法不支持对重复值 进行聚合操作,它只是简单地将长表中的数据转换 为宽表。df.pivot_table()方法支持对重复值 进行聚合操作。可以使用aggfunc参数来指定聚合函数,例如求均值、求和、计数等。
总的来说,df.pivot()方法适用于长表中不存在重复值 的情况,而df.pivot_table()方法适用于长表中存在重复值 的情况,并且可以对重复值 进行聚合操作。根据具体的数据结构 和分析需求,选择合适的方法来进行转换操作。











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330