大数据究竟是什么4_数据分析师
和大数据相关的技术
云技术
大数据常和云计算联系到一起,因为实时的大型数据集分析需要分布式处理框架来向数十、数百或甚至数万的电脑分配工作。可以说,云计算充当了工业革命时期的发动机的角色,而大数据则是电。
云计算思想的起源是麦卡锡在上世纪60年代提出的:把计算能力作为一种像水和电一样的公用事业提供给用户。
如今,在Google、Amazon、Facebook等一批互联网企业引领下,一种行之有效的模式出现了:云计算提供基础架构平台,大数据应用运行在这个平台上。
业内是这么形容两者的关系:没有大数据的信息积淀,则云计算的计算能力再强大,也难以找到用武之地;没有云计算的处理能力,则大数据的信息积淀再丰富,也终究只是镜花水月。
那么大数据到底需要哪些云计算技术呢?
这里暂且列举一些,比如虚拟化技术,分布式处理技术,海量数据的存储和管理技术,NoSQL、实时流数据处理、智能分析技术(类似模式识别以及自然语言理解)等。
云计算和大数据之间的关系可以用下面的一张图来说明,两者之间结合后会产生如下效应:可以提供更多基于海量业务数据的创新型服务;通过云计算技术的不断发展降低大数据业务的创新成本。
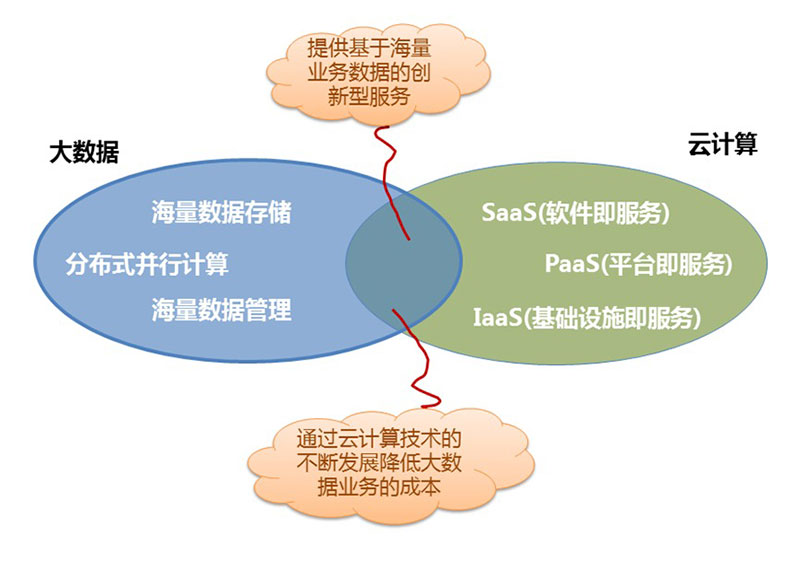
如果将云计算与大数据进行一些比较,最明显的区分在两个方面:
第一,在概念上两者有所不同,云计算改变了IT,而大数据则改变了业务。然而大数据必须有云作为基础架构,才能得以顺畅运营。
第二,大数据和云计算的目标受众不同,云计算是CIO等关心的技术层,是一个进阶的IT解决方案。而大数据是CEO关注的、是业务层的产品,而大数据的决策者是业务层。
Ø 分布式处理技术
分布式处理系统可以将不同地点的或具有不同功能的或拥有不同数据的多台计算机用通信网络连接起来,在控制系统的统一管理控制下,协调地完成信息处理任务—这就是分布式处理系统的定义。
以Hadoop(Yahoo)为例进行说明,Hadoop是一个实现了MapReduce模式的能够对大量数据进行分布式处理的软件框架,是以一种可靠、高效、可伸缩的方式进行处理的。
而MapReduce是Google提出的一种云计算的核心计算模式,是一种分布式运算技术,也是简化的分布式编程模式,MapReduce模式的主要思想是将自动分割要执行的问题(例如程序)拆解成map(映射)和reduce(化简)的方式, 在数据被分割后通过Map 函数的程序将数据映射成不同的区块,分配给计算机机群处理达到分布式运算的效果,在通过Reduce 函数的程序将结果汇整,从而输出开发者需要的结果。
再来看看Hadoop的特性,第一,它是可靠的,因为它假设计算元素和存储会失败,因此它维护多个工作数据副本,确保能够针对失败的节点重新分布处理。其次,Hadoop 是高效的,因为它以并行的方式工作,通过并行处理加快处理速度。Hadoop 还是可伸缩的,能够处理 PB 级数据。此外,Hadoop 依赖于社区服务器,因此它的成本比较低,任何人都可以使用。
你也可以这么理解Hadoop的构成,Hadoop=HDFS(文件系统,数据存储技术相关)+HBase(数据库)+MapReduce(数据处理)+……Others
Hadoop用到的一些技术有:
-
HDFS: Hadoop分布式文件系统(Distributed File System) - HDFS (HadoopDistributed File System)
-
MapReduce:并行计算框架
-
HBase: 类似Google BigTable的分布式NoSQL列数据库。
-
Hive:数据仓库工具,由Facebook贡献。
-
Zookeeper:分布式锁设施,提供类似Google Chubby的功能,由Facebook贡献。
-
Avro:新的数据序列化格式与传输工具,将逐步取代Hadoop原有的IPC机制。
-
Pig:大数据分析平台,为用户提供多种接口。
-
Ambari:Hadoop管理工具,可以快捷的监控、部署、管理集群。
-
Sqoop:用于在Hadoop与传统的数据库间进行数据的传递。
说了这么多,举个实际的例子,虽然这个例子有些陈旧,但是淘宝的海量数据技术架构还是有助于我们理解对于大数据的运作处理机制:
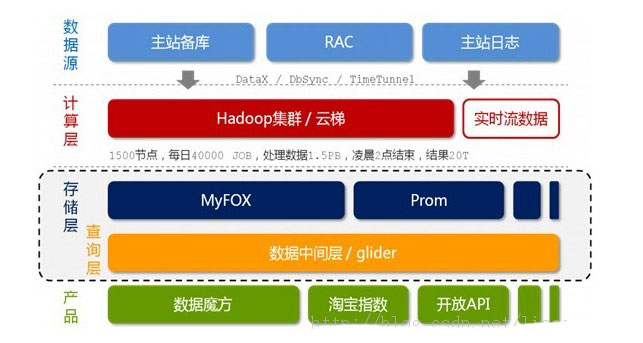
如上图所示,淘宝的海量数据产品技术架构分为五个层次,从上至下来看它们分别是:数据源,计算层,存储层,查询层和产品层。
数据来源层。存放着淘宝各店的交易数据。在数据源层产生的数据,通过DataX,DbSync和Timetunel准实时的传输到下面第2点所述的“云梯”。
计算层。在这个计算层内,淘宝采用的是Hadoop集群,这个集群,我们暂且称之为云梯,是计算层的主要组成部分。在云梯上,系统每天会对数据产品进行不同的MapReduce计算。
存储层。在这一层,淘宝采用了两个东西,一个使MyFox,一个是Prom。MyFox是基于MySQL的分布式关系型数据库的集群,Prom是基于Hadoop Hbase技术的一个NoSQL的存储集群。
查询层。在这一层中,Glider是以HTTP协议对外提供restful方式的接口。数据产品通过一个唯一的URL来获取到它想要的数据。同时,数据查询即是通过MyFox来查询的。
最后一层是产品层,这个就不用解释了。
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330