
CDA数据分析师 出品
作者:Mika
数据:真达
后期:泽龙
【导语】:这几天吃的最多的就属腾讯状告老干妈的瓜了,事件频频反转,让网友们在瓜地里吃都吃不过来。今天我们就来用数据聊一聊。Python技术分析请看第四部分。
Show me data,用数据说话
今天我们聊一聊 腾讯老干妈这场“逗鹅冤”
点击下方视频,先睹为快:
这几天吃的最多的就属腾讯状告老干妈的瓜了,事件频频反转,让网友们在瓜地里吃都吃不过来。
一边是财大气粗的鹅厂,另一边是国内最火辣的“国民女神”,看似毫无交集的双方又是怎么一回事呢?

事情是这样的,6 月 30 日,有消息称,腾讯把老干妈给告了!理由是老干妈拖欠腾讯广告费,总额约 1600w。吃瓜群众一片哗然,那个女人竟然吃霸王餐!
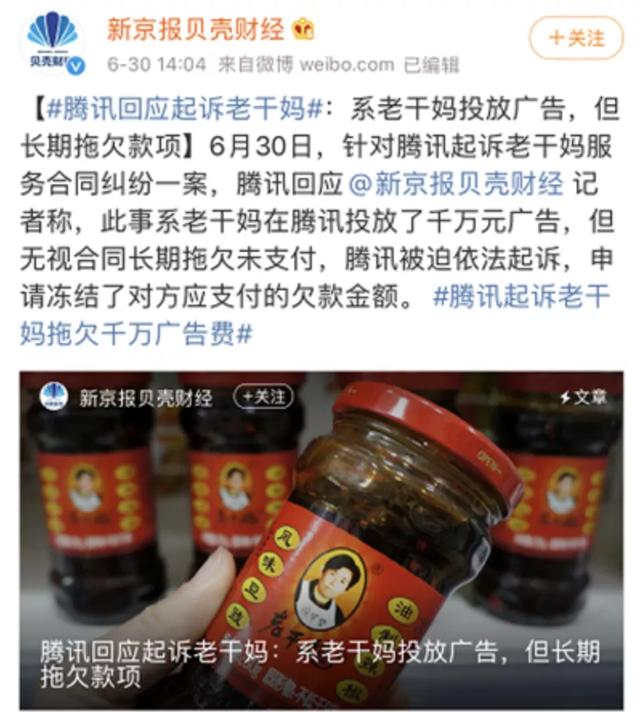
谁知道,不到一天,这件事情就了反转。6月30日晚间,老干妈声称从没和腾讯合作过,腾讯被骗了,还严肃地发了个声明,并帮腾讯报了警。

一时间,鹅说鹅有理,妈说妈有理。
接着7月1日,贵阳警方也发布通报,概括一下就是:3 个骗子为了倒卖腾讯游戏礼包码,冒充老干妈的市场人员与腾讯签了合同。

消息出来,网友们都惊了,腾讯居然有被骗的一天?
与此同时腾讯的公关也没闲着,开始一系列雷厉风行的自黑操作,还表示要一千瓶老干妈全网寻骗子,老干妈也是迅速上架1000瓶大客户组合装辣椒酱,就是这么霸气。
那这次腾讯都有哪些自黑操作?
老干妈的辣椒到底香不香?
今天我们就用数据来盘一盘。
主要从以下几点展开:
“吃了假辣椒酱的憨憨企鹅” 官方自黑最为致命
辣椒酱又香了!这些年乘风破浪的老干妈
吃了这么多年的老干妈,究竟哪种口味最好吃?
教你用Python分析B站“逗鹅冤”视频数据
01“吃了假辣椒酱的憨憨企鹅”
官方自黑最为致命
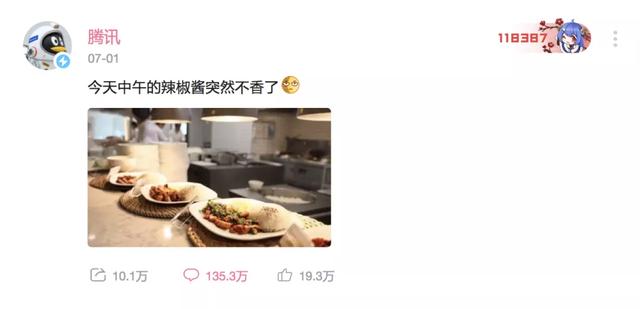
腾讯的公关也没闲着,一系列雷厉风行的自黑操作。先是于7月1日中午,腾讯官方在B站动态发布腾讯官方B站账号发表动态:“今天中午的辣椒酱突然不香了。”
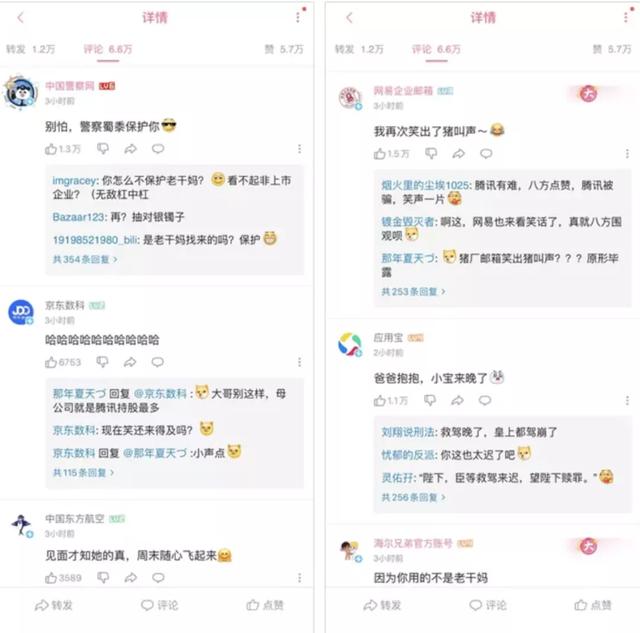
评论区马上成了大厂们的狂欢区, 各大品牌纷纷赶来嘲笑被骗的鹅厂,顺便给自己打个广告、蹭波热度。
隔壁的阿里秉承着看热闹不嫌事大的原则,开始整起了活——希望天下无假章。

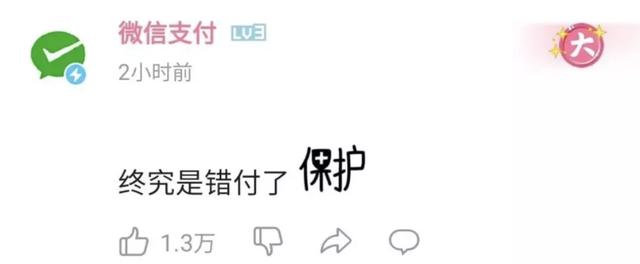
只有微信支付一脸惆怅,发出一声感慨: 还是错付了。
京东数科则是无情的哈哈哈,网易邮箱笑出猪叫。
腾讯自己也干脆破罐子破摔,用一千瓶老干妈作为网友提供线索的奖励。

当晚,腾讯再发视频自黑,承认自己就是那个吃了假辣椒酱的憨憨企鹅。目前截止到发稿,这条视频在b站最高全站排名第三,播放量高达602.万,共5.6万条弹幕。

瞬时间,腾讯和老干妈这个事件一出,B站上也涌现出了很多相关视频。
让我们对数据进行进一步分析整理:
(Python分析B站视频讲解请看第四部分)
相关视频发布时间分布
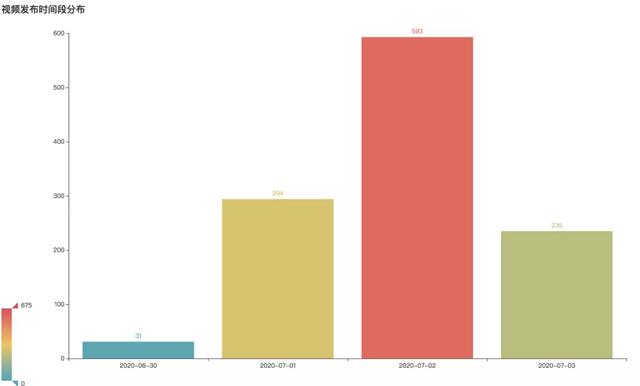
可以看到,当事件刚爆出的6月30日有31个视频,不算多。到7月1日,有294个相关视频,随着进一步发酵升温,7月2日已新发布593个视频,而这一数据也还在增加。
那么这些衍生的视频都属于什么类型分区呢?
视频分区分布
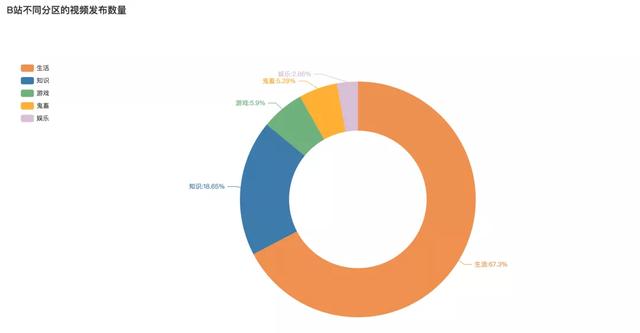
可以看到,生活区的最多,占比67.3%。其次知识类的占比18.65%。
这些视频中哪些播放量最高?
播放量TOP10视频
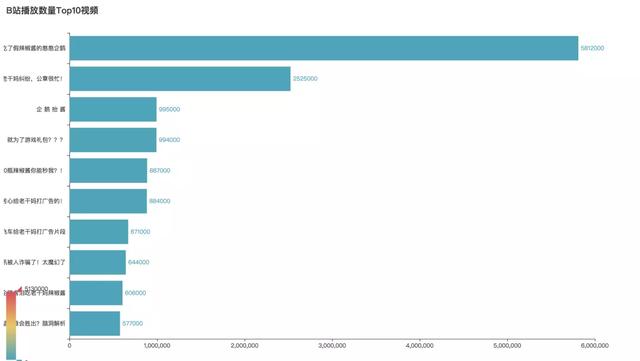
关于这个事件,腾讯官方发布的《我就是那个吃了假辣椒酱的憨憨企鹅》播放量最高,截止到发稿止,播放量已突破600万次,果然官方自黑最为致命。然后是罗翔老师的《老干妈纠纷,公章很忙》,位居第二,从法律角度带你硬核科普吃瓜。
视频标题词云

这些视频都在说些啥?通过分析相关视频标题词云可以看到,关键字中除了"腾讯"、"老干妈"、"企鹅"、"逗鹅冤"、"辣椒酱"等都是围绕的焦点。
02辣椒酱到底香不香?
这些年乘风破浪的老干妈
如果提到家家户户必备的调料神器,那老干妈绝对当之无愧。多年来一直不变的红色包装,拧开瓶盖,麻辣红油的香气就四溢开来,火红的辣椒中伴着或是豆豉、肉丝的酱料简直是绝妙的下饭神器。
全国辣椒酱市场份额将近400亿元,老干妈独占了10%,可见老干妈在国人心中有着举足轻重的地位。根据数据显示,老干妈一天的销售量为160万瓶,2019年老干妈的销售额突破50亿元,15年之内老干妈的生产总值增加了80多倍。
近年来,老干妈也是各种玩跨界营销:
2018年9月,纽约时装周上,老干妈卫衣亮相T台引关注。

联手《男人装》,以“火辣教母”为噱头推出定制礼盒。

以及定制手提袋:

还联合聚划算拍了视频广告,外形神似“老干妈”陶华碧的年轻女孩,配上“拧开干妈,看穿一切”的洗脑歌词,再加上鬼畜舞蹈,瞬间吸睛无数。

虽然近年来,由于各种网红辣酱轮番登场,老干妈的销量不太如意。自从6月30日“逗鹅冤”事件爆发出来后,让老干妈又重新活了起来,销量出现了大幅度突破,有种”大圣归来“的感觉。老干妈一跃成为了近期飙升最快的店铺。网友感叹:老干妈又香了。
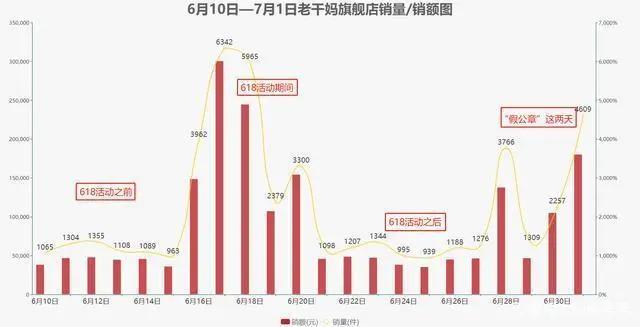
03吃了这么多年的老干妈
究竟哪种口味最好吃?
那么吃了这么多年的老干妈,究竟哪种口味最好吃呢?我们分析了老干妈天猫旗舰店的数据。分析淘宝数据的方法,我们之前有讲到,欢迎回顾之前的文章:
Python告诉你:粽子甜咸之争谁胜出?吃货最爱买谁家的粽子?
首先看到价格:
老干妈商品价格分布
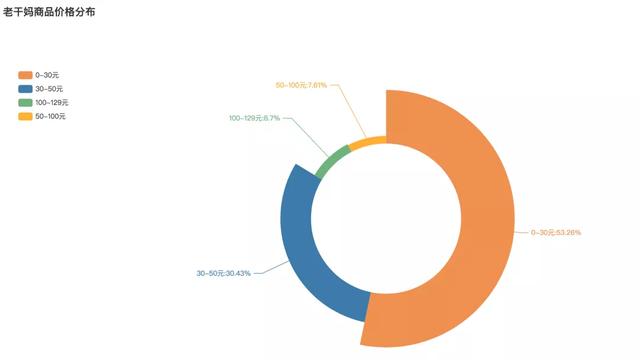
在售价方面,老干妈辣酱既有单瓶销售的,也有几瓶的组合装。可以看到其中30元以内的产品是最多的,占比近一半,为53.26%。其次30-50元的位30.43%。
商品标题词云
接下来看到商品的标题,

可以看到除了经典的"老干妈风味"、"辣椒酱"、"香辣"、"豆豉"、"拌面"等都是常常出现的词。
最后看到最关键的,那种口味最受欢迎呢?
不同口味销量分布
说道老干妈的口味,那可就多了。除了最熟悉的风味豆豉,还有风味油辣椒、风味辣子鸡、辣豆瓣、干煸肉丝等十多种口味。当中哪些口味最受青睐呢?
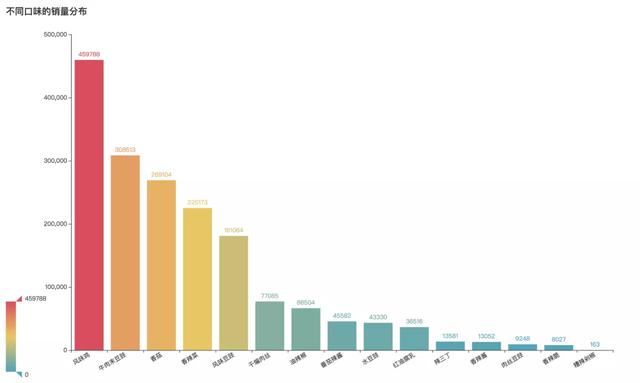
根据老干妈天猫旗舰店的销售数据,让我们看到销量口味排名图:
其中销的最好的就是风味鸡这款啦,销量遥遥领先。之后第二名的是牛肉末豆豉这款。香菇和香辣菜分别位居三、四名。之后经典的风味豆豉和干煸肉丝分别为第五、第六。
那么哪款老干妈又是你的最爱呢?欢迎留言告诉我们哦~
04教你用Python分析
B站视频数据
最后我们看下如何分析B站的视频数据。
回复关键字“老干妈”
获取详细数据代码
我们使用Python获取了B站上关于腾讯-老干妈相关的视频数据,进行了数据分析。
首先导入所需库,其中pandas用于数据读入和数据清洗,pyecharts用于数据可视化,stylecloud用于绘制词云图。
# 导入包
import pandas as pd
import jieba
import re
from pyecharts.charts import Bar, Line, Pie, Map, Page
from pyecharts import options as opts
from pyecharts.globals import SymbolType, WarningType
WarningType.ShowWarning = False
import stylecloud
from IPython.display import Image # 用于在jupyter lab中显示本地图片
1. 数据读入
首先读入数据。
# 读入数据
df = pd.read_excel('../data/B站分区视频7.03.xlsx')
df.head()

去重之后查看一下数据集的大小,一共有1222条数据。
# 去重
df = df.drop_duplicates()
# 删除列
df.drop('video_url', axis=1. inplace=True)
df.info()
Int64Index: 1222 entries, 0 to 1406
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 region 1222 non-null object
1 title 1222 non-null object
2 upload_time 1222 non-null object
3 view_num 1222 non-null object
4 up_author 1222 non-null object
dtypes: object(5)
memory usage: 57.3+ KB
2. 数据预处理
数据预处理部分主要进行以下部分工作:
view_num:提取数值和单位,转换为数值型;
筛选6.30~7.03数据
# 提取数值
df['num'] = df['view_num'].str.extract('(\d+.*\d+)').astype('float')
# 提取单位
df['unit'] = df['view_num'].str.extract('([\u4e00-\u9fa5]+)')
df['unit'] = df['unit'].replace('万', 10000).replace(np.nan, 1)
# 计算乘积
df['true_num'] = df['num'] * df['unit']
# 删除列
df.drop('view_num', axis=1. inplace=True)
# 筛选时间
pattern = re.compile('2020-06-30|2020-07-01|2020-07-02|2020-07-03')
df = df[df.upload_time.str.contains(pattern)]
3. 数据可视化
我们针对数据进行描述性统计分析,探索一下问题:
发布时间和热度
不同分区的发布数量
不同分区的播放量表现
最高播放的Top10视频
标题词云图。
3.1 发布时间和热度
time_num = df.upload_time.value_counts().sort_index()
time_num
2020-06-30 31
2020-07-01 294
2020-07-02 593
2020-07-03 235
Name: upload_time, dtype: int64
# 条形图
bar1 = Bar(init_opts=opts.InitOpts(width='1350px', height='750px'))
bar1.add_xaxis(time_num.index.tolist())
bar1.add_yaxis('', time_num.values.tolist())
bar1.set_global_opts(title_opts=opts.TitleOpts(title='视频发布时间段分布'),
visualmap_opts=opts.VisualMapOpts(max_=675),
)
bar1.render()
3.2 不同分区的发布数量
region_num = df.region.value_counts()
region_num
生活 776
知识 215
游戏 68
鬼畜 61
娱乐 33
Name: region, dtype: int64
data_pair = [list(z) for z in zip(region_num.index.tolist(), region_num.values.tolist())]
# 绘制饼图
pie1 = Pie(init_opts=opts.InitOpts(width='1350px', height='750px'))
pie1.add('', data_pair, radius=['35%', '60%'])
pie1.set_global_opts(title_opts=opts.TitleOpts(title='B站不同分区的视频发布数量'),
legend_opts=opts.LegendOpts(orient='vertical', pos_top='15%', pos_left='2%'))
pie1.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}:{d}%"))
pie1.set_colors(['#EF9050', '#3B7BA9', '#6FB27C', '#FFAF34', '#D8BFD8'])
pie1.render()
3.3 不同分区的播放量表现
region_view = df.groupby('region')['true_num'].sum()
region_view = region_view.sort_values(ascending=False)
region_view
region
生活 12760197.0
知识 7167597.0
鬼畜 1382580.0
游戏 792650.0
娱乐 53831.0
Name: true_num, dtype: float64
# 条形图
bar2 = Bar(init_opts=opts.InitOpts(width='1350px', height='750px'))
bar2.add_xaxis(region_view.index.tolist())
bar2.add_yaxis('', region_view.values.tolist())
bar2.set_global_opts(title_opts=opts.TitleOpts(title='B站不同分区的视频播放总量'),
visualmap_opts=opts.VisualMapOpts(max_=10837810.0),
)
bar2.render()
3.4 最高播放的Top10
# 最多播放top10
view_top10 = df.sort_values('true_num', ascending=False).head(10)[['title', 'true_num']]
view_top10 = view_top10.sort_values('true_num')
view_top10

# 柱形图
bar3 = Bar(init_opts=opts.InitOpts(width='1350px', height='750px'))
bar3.add_xaxis(view_top10.title.values.tolist())
bar3.add_yaxis('', view_top10.true_num.values.tolist())
bar3.set_global_opts(title_opts=opts.TitleOpts(title='B站播放数量Top10视频'),
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(position='inside')),
visualmap_opts=opts.VisualMapOpts(max_=5130000.0),
)
bar3.set_series_opts(label_opts=opts.LabelOpts(position='right'))
bar3.reversal_axis()
bar3.render()
3.5 标题词云图
# 绘制词云图
stylecloud.gen_stylecloud(text=' '.join(text), # text为分词后的字符串
collocations=False,
font_path=r'C:\Windows\Fonts\msyh.ttc',
icon_name='fas fa-bell',
size=653.
output_name='./词云图/B站分区视频标题词云图.png')
Image(filename='./词云图/B站分区视频标题词云图.png')
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330