英雄联盟如何指挥团战?AI帮你做决策
英雄联盟是一个需要默契团队配合的多人对战游戏。在瞬息万变的战斗中,如何做出正确的决策非常重要。最近,数据分析师
Philip Osborne
提出了一种利用人工智能技术提升英雄联盟中团队决策水平的方法,并将其开源。该方法不仅参考了大量真实游戏的统计结果,也将当前玩家的偏好计算在内。

该项目由三部分组成,旨在将 MOBA 游戏《英雄联盟》的对战建模为马尔科夫决策过程,然后应用强化学习找到最佳决策,该决策还考虑到玩家的偏好,并超越了简单的「计分板」统计。
作者在 Kaggle 中上传了模型的每个部分,以便大家更好地理解数据的处理过程与模型结构:
-
第一部分:https://www.kaggle.com/osbornep/lol-ai-model-part-1-initial-eda-and-first-mdp
-
第二部分:https://www.kaggle.com/osbornep/lol-ai-model-part-2-redesign-mdp-with-gold-diff
-
第三部分:https://www.kaggle.com/osbornep/lol-ai-model-part-3-final-output
目前这个项目还在进行当中,我们希望展示复杂的机器学习方法可以在游戏中做什么。该游戏的分数不只是简单的「计分板」统计结果,如下图所示:

动机和目标
英雄联盟是一款团队竞技电子游戏,每局游戏有两个团队(每队五人),为补兵与杀人展开竞争。获得优势会使玩家变得比对手更强大(获得更好的装备,升级更快),一方优势不断增加的话,获胜的几率也会变大。因此,后续的打法和游戏走向依赖于之前的打法和战况,最后一方将摧毁另一方的基地,从而赢得比赛。
像这种根据前情建模的情况并不新鲜;多年来,研究人员一直在考虑如何将这种方法应用于篮球等运动中(https://arxiv.org/pdf/1507.01816.pdf),在这些运动中,传球、运球、犯规等一系列动作会导致一方得分或失分。此类研究旨在提供比简单的得分统计(篮球中运动员得分或游戏里玩家获取人头)更加详细的情况,并考虑建模为时间上连续的一系列事件时,团队应该如何操作。
以这种方式建模对英雄联盟这类游戏来说更为重要,因为在该类游戏中,玩家补兵和杀人后可以获得装备并升级。例如,一个玩家拿到首杀就可以获取额外金币购买更强的装备。而有了这些装备之后,该玩家变得更加强大进而获取更多人头,如此循环,直到带领其队伍获取最后的胜利。这种领先优势被称为「滚雪球」,因为该玩家会不断积累优势,不过很多时候,该玩家在游戏中所在的队伍并不一定是优势方,野怪和团队合作更为重要。
该项目的目标很简单:我们是否可以根据游戏前情计算下一步最好的打法,然后根据真实比赛数据增加最终的胜率。
然而,一场游戏中影响玩家决策的因素有很多,没那么容易预测。不论收集多少数据,玩家获得的信息量始终多于任何一台计算机(至少目前如此!)。例如,在一场游戏中,玩家可能超水平发挥或发挥失常,或者偏好某种打法(通常根据他们选择的英雄来界定)。有些玩家自然而然地会变得更加好斗,喜欢杀戮,有些玩家则比较被动一直补兵发育。因此,我们进一步开发模型,允许玩家根据其偏好调整建议的打法。
让模型「人工智能化」
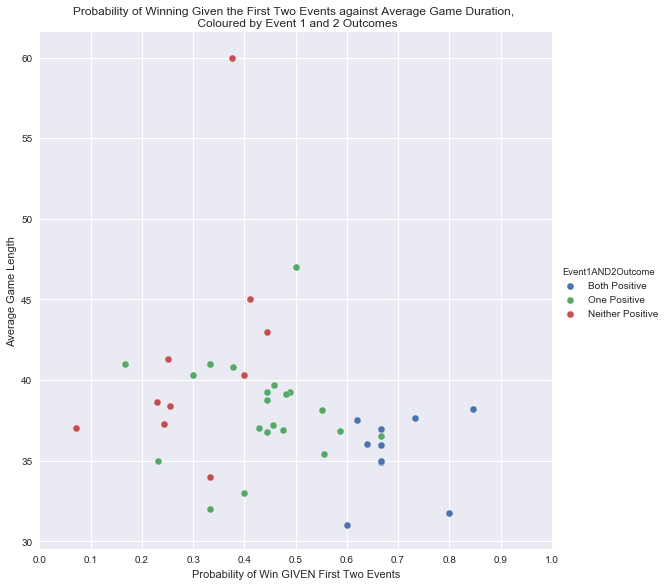
在第一部分中,我们进行了一些介绍性的统计分析。例如,假设队伍在比赛中补到第一个和第二个兵,我们能够计算出获胜的概率,如下图所示。
有两个组成部分,使我们的项目超越简单的统计的人工智能:
-
首先,在未预先设想游戏概念时,模型会学习哪些行动是最好的。
-
第二,它试图了解玩家对影响模型输出的决策的偏好。
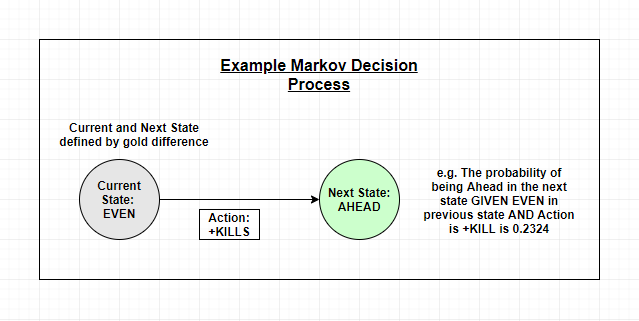
我们定义马尔可夫决策过程及收集玩家喜好的方式会决定模型学习和输出的内容。
根据匹配统计信息对马尔科夫决策过程进行预处理和创建
AI 模型 II:引入打钱效率
我从第一个模型的结果中意识到,我们没有考虑到负面和正面事件对未来都可能产生累积的影响。换句话说,无论在当时时间点之前还是之后,当前的
MDP(马尔科夫决策过程)概率都有可能发生。在游戏中,这是不正确的。一旦落后,杀人、拿塔、补兵都会变得更难,我们需要考虑到这一点。所以,我们引入队伍间的打钱效率来重新定义状态。当前目标是建立一个定义状态的
MDP,这个状态可能是事件发生顺序,或者队伍是否落后或领先。我们将金币差值分为以下几类:
-
相等:0–999 金币差值(平均每个队员 0-200)
-
略落后/领先:1,000–2,499(平均每个队员 200–500)
-
落后/领先:2,500–4,999(平均每个队员 500–1,000)
-
远远落后/遥遥领先:5,000(平均每个队员 1,000+)
我们也需要考虑没有任何事件发生的情况,并把其归为『无』事件中,以保证每分钟都有事件发生。这个『无』事件表示一个队伍决定拖延游戏,以将那些在早期游戏中更善于获得金币的队伍区分出来,而不需要杀死(或通过小兵杀死)他们。然而,这样做也会大大增加数据量。因为我们为匹配可用匹配项已经添加了
7 个类别,但如果我们能访问更常规的匹配项,那数据量就已足够了。如前所述,我们可以通过以下步骤来概述:
预处理
1. 输入杀人数、塔数、野怪和金币差值的数据。
2. 将『地址』转为 ID 特性。
3. 移除所有旧版本的游戏。
4. 从金币差值开始,按照事件的时间、匹配 ID 和与以前一致的团队进行合计。
5. 追加(助攻的)人头数、怪数和塔数到此末尾,为每个事件创建行并按发生的时间对事件进行排序(平均人头数)。
6. 添加「事件序号」特性,显示每次匹配中的事件顺序。
7. 为行上的每个事件创建一个统一的「事件」特性,包括人头、塔、怪或者『无』事件。
8. 每次匹配时将其转化为行,现在是用列来表示每个事件。
9. 只考虑红队的视角,以便合并列,视蓝队增益为负红队增益。同时增加红队的游戏长度和结果。
10. 将所有空白值 (即在前面步骤中结束的游戏) 替换为匹配的游戏结果,以便所有行中的最后一个事件是匹配结果。
11. 转换为 MDP,其中 P(X_t | X_t-1)用于每个事件数和由金币差值定义的状态之间的所有事件类型。
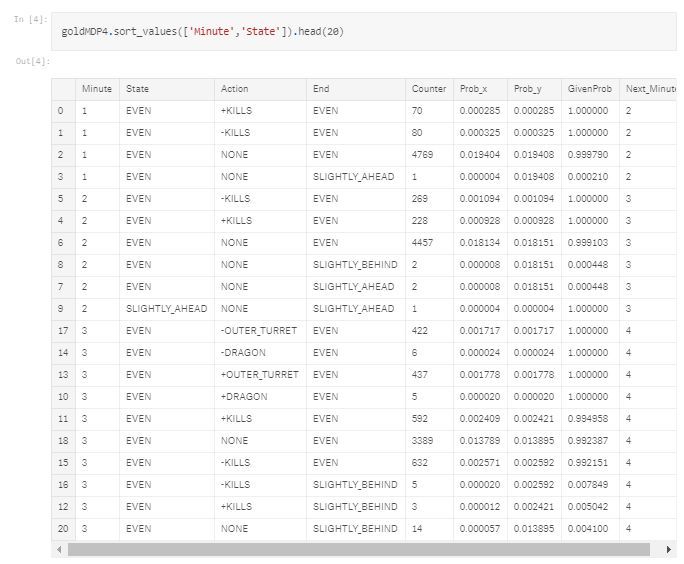
马尔科夫决策过程输出
使用简易英语的模型 V6 伪代码
我们最终版本的模型简单总结如下:
1. 引入参数
2. 初始化启动状态、启动事件、启动操作
3. 根据 MDP 中定义的首次提供或基于其发生可能性的随机选择操作
4. 当行动赢或输时,结束
5. 跟踪事件中所采取的行动和最终结果(赢/输)
6. 根据最终结果所用的更新规则来更新操作
7. 重复 x 次上述步骤
引入奖励偏好
首先,我们调整模型代码,把奖励归入回报计算中。然后,当我们运行模型时,引入了对某些行为的偏置,现而不是简单地使奖励等于零。
在第一个例子中,我们显示了如果对一个动作进行积极的评价,会发生什么;在第二个例子中,显示对一个动作进行消极的评价,会发生什么。

如果我们积极评价动作『+KILLS』的输出
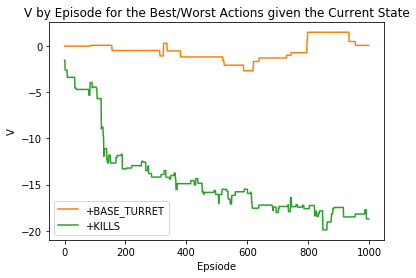
如果我们消极评价动作『+KILLS』的输出
更真实的玩家偏好
现在我们可以尝试近似模拟玩家的真实偏好。在这个案例中,我们随机化一些奖励以允许遵守以下两条规则:
因此,我们对人头和补兵的奖励都是最小值-0.05,而其它行动的奖励都在-0.05 和 0.05 之间随机生成。
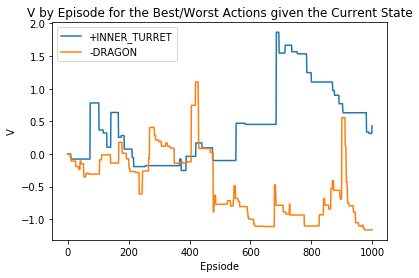
随机化玩家奖励后的输出。
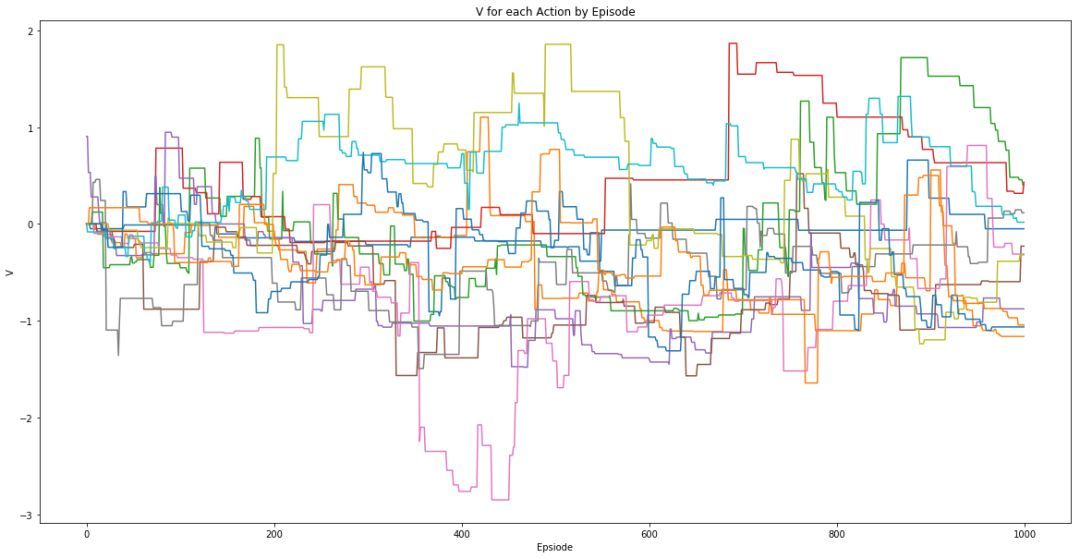
随机化玩家所有动作的奖励后所获得的输出。
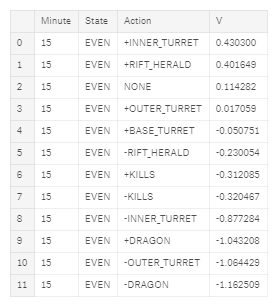
最终输出,显示给定当前金币差值状态和分钟的每个动作的值
总结及玩家对奖励的反馈
我过分简化了某些特征(如「kills」实际上并不代表人头的数量),数据也不太可能表示正常的匹配。然而,我希望本文能够清晰地展现一个有趣的概念,鼓励更多人讨论这一领域今后的走向。
首先,我将列出在实现之前需要作出的重要改进:
1. 使用更多能够代表整个玩家群体(而不只是竞争性比赛)的数据计算 MDP。
2. 提高模型效率,将其计算时间控制在更合理的范围。蒙特卡洛以耗时著称,因此我们将探索更高效的算法。
3. 采用更高级的参数优化以进一步改进结果。
4. 捕捉、映射原型玩家对更真实的奖励信号的反馈。
我们引入了针对影响模型输出而给予的奖励,但该如何获得奖励?我们可以考虑几种方法,但是根据我之前的研究,我认为最好的方法就是考虑一种既涉及到行动的个体质量又考虑到转变质量的奖励。
这变得越来越复杂,我不会在此文中展开,但简而言之,我们想为玩家匹配决策,其中下一个最佳决策取决于最新情况。比如,如果一队玩家将对方全部歼灭,他们可能会去拿大龙。我们的模型已经将一个序列中事件发生的概率考虑在内,因此,我们也应该用同样的方式思考玩家的决策。这一想法来自一篇论文《DJ-MC:
A Reinforcement-Learning Agent for Music Playlist
Recommendation》,该论文阐释了如何更加详细地将反馈映射出来。
反馈的收集方式决定了我们的模型能有多成功。依我之见,我们这么做的最终目标是为玩家的下一步决策提供最佳实时建议。如此一来,玩家就能从根据比赛数据算出的几条最佳决策(根据获胜情况排序)中做出选择。可以在多个游戏中跟踪该玩家的选择,以进一步了解和理解该玩家的偏好。这也意味着,我们不仅可以追踪决策的结果,还能预测该玩家的意图(例如,该玩家试图拆塔结果却被杀了),甚至还能为更高级的分析提供信息。
当然,这样的想法可能造成团队成员意见不符,也可能让游戏变得没那么令人兴奋。但我认为这样的想法可能对低水平或者常规水平的玩家有益,因为这种水平的游戏玩家难以清楚的沟通游戏决策。这也可能帮助识别「毒瘤」玩家,因为团队指望通过投票系统来统一意见,然后就能看出「毒瘤」玩家是不是一直不遵循团队计划,忽略队友。
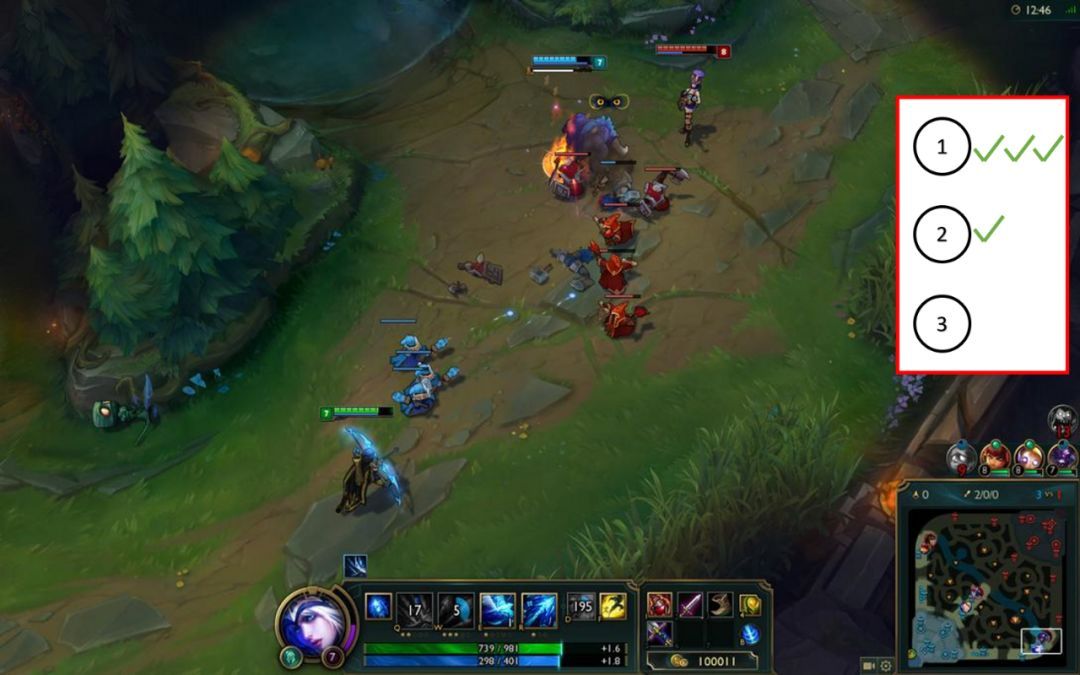
实时游戏环境中的模型推荐投票系统示例
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330