R语言使用随机森林方法对数据分类
说明
随机森林是另一类可用的集成学习方法,该算法在训练过程中将产生多棵决策树,每棵决策树会根据输入数据集产生相应的预测输出,算法采用投票机制选择类别众数做为预测结果。
操作
导入随机森林包:
library(randomForest)
使用随机森林分类器处理训练数据:
churn.rf = randomForest(churn ~ .,data = trainset,importance = T)
churn.rf
Call:
randomForest(formula = churn ~ ., data = trainset, importance = T)
Type of random forest: classification
Number of trees: 500
No. of variables tried at each split: 4
OOB estimate of error rate: 5.27%
Confusion matrix:
yes no class.error
yes 245 97 0.28362573
no 25 1948 0.01267106
利用训练好的模型对测试集进行分类预测:
churn.prediction = predict(churn.rf,testset)
类似其它分类处理,产生分类表:
table(churn.prediction,testset$churn)
churn.prediction yes no
yes 111 7
no 30 870
调用plot函数绘制森林对象均方差:
plot(churn.rf)
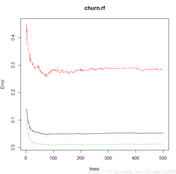
随机森林的均方差
根据建立好的模型评估各属性的重要度:
importance(churn.rf)
yes no MeanDecreaseAccuracy MeanDecreaseGini
international_plan 68.9592890 54.118994 72.190204 50.35584
voice_mail_plan 18.8899994 15.832400 19.607844 10.44601
number_vmail_messages 21.3080062 16.262770 22.068514 19.05619
total_day_minutes 28.3237379 30.323756 39.961077 79.91474
total_day_calls 0.6325725 -1.131930 -0.802642 20.80946
total_day_charge 28.4798708 28.146414 35.858906 77.84837
total_eve_minutes 18.5242988 20.572464 24.484322 42.99373
total_eve_calls -3.3431379 -2.301767 -3.495801 17.45619
total_eve_charge 20.4379809 20.619705 24.489771 44.02855
total_night_minutes 0.9451961 16.105720 16.694651 22.93663
total_night_calls -0.3497164 2.202619 1.869193 19.94091
total_night_charge 0.1110824 15.977083 16.593633 22.22769
total_intl_minutes 17.3951655 20.063485 24.967698 26.05059
total_intl_calls 37.3613313 23.415764 35.497785 33.03289
total_intl_charge 16.7925666 19.636891 24.498369 26.60077
number_customer_service_calls 79.7530696 59.731615 85.221845 67.29635
调用varlmPlot函数绘制变量重要性曲线
varImpPlot(churn.rf)

变量重要性示例
调用margin及plot函数并绘制边缘累计分布图:
margins.rf = margin(churn.rf,trainset)
plot(margins.rf)
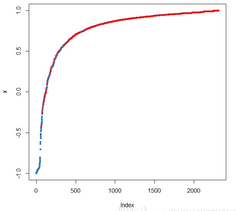
随机森林算法边缘累积分布图
还可以用直方图来绘制随机森林的边缘分布:
hist(margins.rf,main = "Margines of Random Forest for churn dataset")
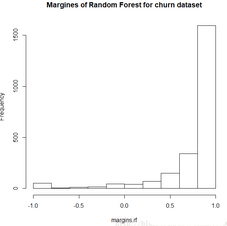
边缘分布直方图
调用boxplot绘制随机森林各类别边缘的箱线图
boxplot(margins.rf ~ trainset$churn,main = "Margines of Random Forest for churn dataset by class")
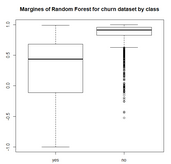
随机森林类别边缘箱图
原理:
随机森林算法目标是通过将多个弱学习机(如单棵决策树)组合得到一个强学习机,算法的处理过程与bagging方法非常相似,假设当拥有N个特征数为M的样例,首先采用bootstrap对数据集进行采样,每次随机采样N个样本作为单个决策树的训练数据集。在每个节点,算法首先随机选取m(m << M)个变量,从它们中间找到能够提供最佳分割效果的预测属性。
然后,算法在不剪枝的前提下生成单颗决策树,最后从每个决策树都得到一个分类预测结果。
如果是回归分析,算法将取所有预测的平均值或者加权平均值作为最后刚出,如果是分类问题,则选择类别预测众数做为最终预测输出。
随机森林包括两个参数,ntree(决策树个数)和mtry(可用来寻找最佳特征的特征个数),而bagging算法只使用了一个ntree参数,因此,如果将mtry设置成与训练数据集特征值一样大时,随机森林算法就等同于bagging算法。
本例利用randomForest包提供的随机森林算法建立了分类模型,将importance值设置为“T”,以确保对预测器的重要性进行评估。
与bagging和boosting方法类似,一旦随机森林的模型构建完成,我们就能利用其对测试数据集进行预测,并得到相应的分类表。
randomForest包还提供了importance和varlmpPlot函数则可以通过绘制平均精确度下降或者平均基尼下降曲线实现属性重要性的可视化。
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330