如何使用Python处理Missing Data
现实世界的数据中常常包含缺失的数据。原因很多,比如观察结果没有记录,或数据损坏。处理缺失的数据很重要,因为许多机器学习算法不支持具有缺失值的数据库。
本教程将讨论如何使用Python处理缺失的数据来进行
机器学习。
您将了解到:
- 如何在数据集中标记无效或损坏的值。
- 如何从数据集中删除缺失数据的行。
- 如何使用数据集的均值估算缺失值。
注意:文章中的例子前提是安装了Python 2或3,Pandas,NumPy和Scikit-Learn的;特别是scikit-learn版本0.18或更高版本。
概述
本教程分为6部分:
皮马印度人糖尿病数据集:我们在哪里查看已知缺失值的数据集。
标记缺失值:我们学习如何在数据集中标记缺失值。
缺少值导致的问题:
机器学习算法如果包含缺少值,将会如何失败。
删除缺少值的行: 如何删除包含缺失值的行。
估算缺失值:我们用合理的值替换缺失值。
允许缺失值的算法:哪些算法允许缺失值。
首先,我们来看看缺少值的示例数据集。
1、皮马印度人糖尿病数据集
皮马印第安人糖尿病数据集根据现有的医疗信息预测5年内皮马印第安人糖尿病发作的概率。
这是两类(2-class)分组问题,每组的观察标本量不同。共有768个观测值,8个输入变量和1个输出变量。变量名称如下:
0.怀孕次数。
1. 口服葡萄糖耐量试验中血浆葡萄糖浓度为2小时。
2. 舒张压(mm Hg)。
3. 三头肌组织褶厚度(mm)。
4. 2小时血清胰岛素(μU/ ml)。
5. 体重指数(kg/ (身高(m))^ 2)。
6. 糖尿病系统功能。
7. 年龄(岁)。
8. 类变量(0或1)。
预测的标准是大约65%的分类精准度。最好结果的分类精度约为77%。
以下列出前5行的样本。

已知此数据集具有缺失值。具体来说,某些列标记为零,即为缺少观察值。
我们可以通过这些列的意义和这些度量值是否可能为零来证实这一点,例如体重指数或血压为零是不可能的。
从这里下载数据集到当前工作目录中,并命名为pima-indians-diabetes.csv的。
2、标记缺失值
在本节中,我们将识别并值标记缺失值。
我们可以使用图表(plots)和汇总统计信息来帮助识别缺失或损坏的数据。
这种方法非常有用。我们可以看到有最小值为零(0)的列。在某些列上,零值无效,表示为无效值或缺失值。
具体来说,以下列具有无效的零最小值:
1:血浆葡萄糖浓度
2:舒张压
3:三头肌组织褶厚度
4:2小时血清胰岛素
5:体重指数
让我们来看看原始数据,这个例子显示出前20行的数据。

运行示例,我们可以清楚地看到列2,3,4和5中的0值。

我们可以得到每列这些列中缺失值的数量。我们可以标记我们感兴趣的DataFrame的子集中的所有零值为真。然后,我们可以计算每列中真值的数量。

我们可以看到1,2和5列只有几个零值,而第3列和第4列显示几乎一半的行都为零值。
这充分表明,不同列可能需要不同的策略来处理,例如确保仍有足够的数据来训练预测模型。
在Python中,特别是Pandas,NumPy和Scikit-Learn,我们将缺失值标记为NaN。在sum,count等操作中,NaN值的值将被忽略。
我们可以通过使用Pandas
DataFrame里的replace()函数,在感兴趣的列的子集上 轻松地将缺失值标记为NaN 。
在我们标记了缺失值之后,我们可以使用isnull()函数将数据集中的所有NaN值标记为真,并获取每列缺失值的计数。

运行每列中缺少值的数量,我们可以看到列1:5的列数与之前运行的零值相同。这表示我们已经正确标记了已识别的缺失值。
我们可以看到列1到5具有与上面标识的零值相同数量的缺失值。这是一个迹象,表示我们已经正确标记了已识别的缺失值。

这是一个很有用的总结。我总是喜欢看实际数据,以确认自己没有弄错。
以下是相同的例子,只是我们打印前20行的数据。

运行后我们可以清楚地看到列2,3,4和5中的NaN值。列1中只有5个丢失值,所以我们在前20行中没有看到并不奇怪。
从原始
数据可以看出,标记丢失值达到我们期望的效果。
在我们进一步处理缺失值之前,首先来看看数据集中缺失值可能会导致的问题。
3、缺少值导致问题
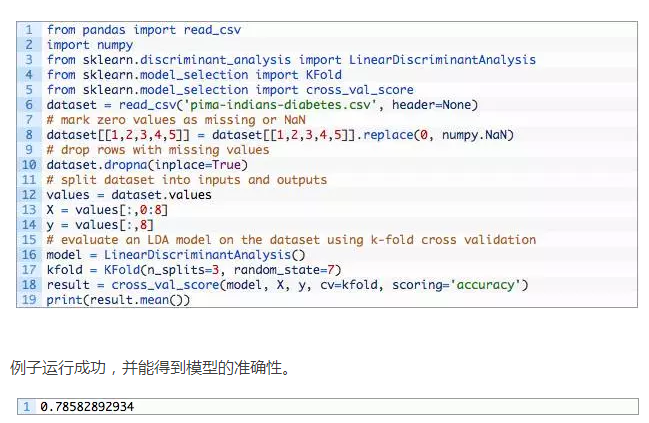
在本节中,我们将尝试评估带有缺失值的数据对线性判别分析(LDA)算法的影响。
当数据集中缺少值时,这种算法将无效。
下面的例子标记了数据集中的缺失值,就像我们在上一节中所做的那样,然后尝试使用3倍交叉验证来评估LDA,求平均精度。

正如我们所料。我们无法在有缺失值的数据集上评估LDA和其他一些算法。
现在,我们来看看处理缺失值的方法。
4、删除缺失值的行
最简单的方法就是删除包含缺失值的行。
Pandas提供了dropna ( ) 函数,可用于删除列或缺少数据的行。我们可以使用dropna ( )来删除所有缺少数据的行,如下所示:

我们现在有一个数据集,我们可以使用它来评估LDA等对缺失值敏感的算法。
删除缺失值的行可能对不适用与某些预测建模问题,另一种方法则是估算丢失值。
5、估算缺失值
引用(imputing),指使用模型替换缺失值。
在替换缺少的值时可以考虑许多选择,例如:
• 在域内具有含义的常量值,例如0,不同于其他所有值。
• 来自另一个随机记录的值。
• 该列的平均值,中值或模式值。
• 由另一预测模型估计的值。
如果最终模型需要做预测,那么所有对于训练数据集进行的imputing都要应用到未来的新数据中。这会影响我们选择如何估算缺失值。
例如,如果您选择使用平均列值进行估算,这些平均值的列将需要存储到文件中,以备将来新数据含有缺失值时使用。
Pandas提供了fillna ( ) 函数来替换具有特定值的缺失值。例如,我们可以使用fillna ( ),平均值来替换每列的缺失值,如下所示:

运行每列中缺少值的计数,显示缺失值为零。

scikit学习库提供可用于替换缺失值的Imputer ( ) 预处理类。
这是一个很灵活的类,允许指定要替换的值(可以是NaN以外的)和用于替换它的东西(如平均值,中值或模式)。Imputer类直接在NumPy数组而不是
DataFrame上运行。
下面的示例使用Imputer类平均值替换每列的缺失值,然后得到转换矩阵中的NaN值的计数。
无论哪种情况,我们都可以对缺失值敏感的算法(如LDA)使用转化后的数据集进行训练 。
下面的例子显示了在Imputer转换数据集中训练LDA算法

尝试用其他值替换缺少的值,并查看是否可以提升模型的表现。
也许缺少值在数据中是有意义的。
接下来,我们将使用将缺失值视为另一个值的做法。
6、支持缺失值的算法
当缺少数据时,并不是所有的算法都会失效。
有一些可以灵活对待缺失值的算法,例如k-Nearest Neighbors,当值缺失时,它可以将其不计入距离测量。
另一些算法,例如分类和回归树,可以在构建预测模型时将缺失值看作唯一且不同的值。
遗憾的是,
决策树和k-Nearest Neighbors对于缺失值并不友好。
不管怎样,如果你考虑使用其他算法(如xgboost)或开发自己的执行,这依然是一个选择
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;














 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330