作者:Python进阶者
来源:Python爬虫与数据挖掘
一、前言
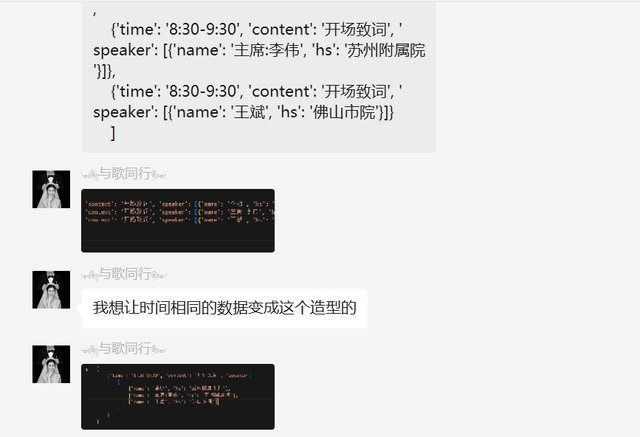
前几天在Python最强王者交流群【༺ཉི།།与歌同行ཉྀ༻】问了一个Python字典的处理问题,提问截图如下:
下面是他的元素数据。
a = [
{'time': '8:30-9:30', 'content': '开场致词', 'speaker': [{'name': '李明', 'hs': '重庆附属永川'}]},
{'time': '8:30-9:30', 'content': '开场致词', 'speaker': [{'name': '主席:李伟', 'hs': '苏州附属院'}]},
{'time': '8:30-9:30', 'content': '开场致词', 'speaker': [{'name': '王斌', 'hs': '佛山市院'}]}
]
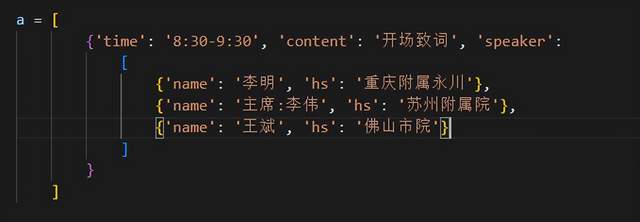
想要达到预期的效果如下图所示:
二、实现过程
这里【甯同学】提供了一个代码,如下所示:
后来我自己也给了一个代码,代码如下:
a = [
{'time': '8:30-9:30', 'content': '开场致词', 'speaker': [{'name': '李明', 'hs': '重庆附属永川'}]},
{'time': '8:30-9:30', 'content': '开场致词', 'speaker': [{'name': '主席:李伟', 'hs': '苏州附属院'}]},
{'time': '8:30-9:30', 'content': '开场致词', 'speaker': [{'name': '王斌', 'hs': '佛山市院'}]}
]
new_dict = {}
new_lst = [] for item in a:
new_dict.setdefault('speaker', []).append(item['speaker']) front_dict = {'time': '8:30-9:30', 'content': '开场致词'} final_dict = {**front_dict, **new_dict} print(final_dict)
有些冗余,但是也是可以得到预期的效果的。
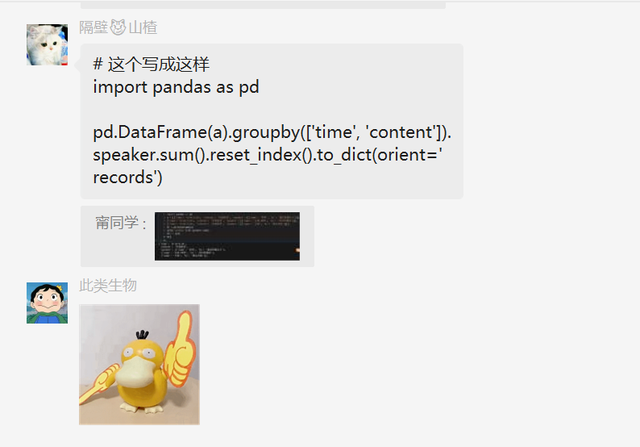
后来【甯同学】还使用Pandas秀了一把,如下所示:
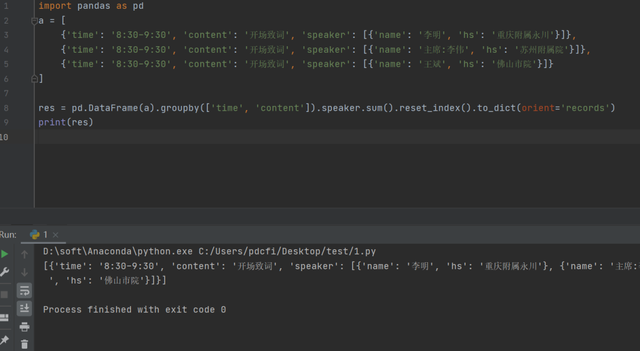
后来【隔壁山楂】针对上面的两个代码,都做了一次优化,代码分别如下:
from itertools import groupby from operator import itemgetter
[dict(zip(('time', 'content', 'speaker'),
(*key, sum([i['speaker'] for i in value], [])))) for key, value in groupby(a, itemgetter('time', 'content'))]
针对Pandas的写法,代码如下:
# 这个写成这样 import pandas as pd pd.DataFrame(a).groupby(['time', 'content']).speaker.sum().reset_index().to_dict(orient='records')
简直太秀了!
三、总结
大家好,我是皮皮。这篇文章主要盘点了一个Python字典处理的问题,文中针对该问题给出了具体的解析和代码实现,帮助粉丝顺利解决了问题。
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;















 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330