SPSS分析技术:单因素方差分析
接下来将会介绍如何用SPSS做各种类型的方差分析,包括单因素方差分析,多因素方差分析,协方差分析,多元方差分析,重复测量方差分析和方差成分分析等应用原理和案例。
单因素方差分析
单因素方差分析用于分析单个自变量的不同水平是否对因变量产生显著影响。单因素方差分析将总方差分为两部分:可以由自变量解释的系统误差和无法由自变量解释的随机误差,若系统误差显著超过随机误差,则认为该自变量在取不同水平时因变量均值存在显著差异。
方差分析的原理
前面的文章虽然介绍过单因素方差分析的数据分析过程,这里再简单强调一遍。当样本数据可以做这样的归类处理,如下图所示:

首先,单因素方差分析的成对假设是:
原假设:因素的k个水平的均值相等;
备择假设:因素的k个水平的均值不完全相等;注意是不完全相等,而不是k个均值互不相等。
其次,求取组内方差和组间方差;
组间方差的计算公式为:

组内方差的计算公式为:

第三步是计算F统计量的值,以及做出假设检验判断;

上式中MSB和MSE分布称为组间方差和组内方差。在原假设为真的条件下,统计量服从自由度为k-1和k(n-1)的F分布。如果F统计量观测值较小,说明组内方差大,组间方差小,此时不能拒绝原假设;相反,就要拒绝原假设,认为自变量(因素)的k个水平对自变量有显著影响。SPSS会自动计算F统计量的观测值以及相应的概率P值,根据P值就可以完成统计检验。
案例分析
某体育高校对来自全国各地的2016级新生做了一次抽样检查,对抽到学生的身高、体重和胸围作了测量和记录,并将所有参与抽样体检的学生按省份划分为东部、中部和西部,试图分析来自不同地区学生的身高是否有差异。

问题分析
研究的问题是来自全国不同地区学生的身高是否有差异,可以理解为地区因素是否对学生身高有影响,影响因素(自变量)是地区,地区因素有三个水平(东部,中部和西部),所以适用单因素方差分析(单因素,三水平)。
分析步骤
1、选择菜单【分析】-【比较平均值】-【单因素ANOVA】,在【单因素方差分析】中选择变量【身高】,选入因变量列表;选择【地区】,将其选入因子。程序可以同时对多个因变量进行单因素方差分析,但是【因子】只能选取一个自变量。

2、单击【对比】,打开【单因素ANOVA:对比】。该选项是用来做因素不同水平的均值对比的。将多项式选中,在度中可以选择线性、二次项到五次项,表示可以利用不同的多项式对均值进行对比。我们选中线性,然后再系数中输入-1,0.5,0.5,点击下一页,再输入0.5,-1,0.5,再点击下一页,输入0.5,0.5,-1。表示将东部,中部和西部的均值配上系数进行加减对比。例如第一组系数-1,0.5,0.5,表示-1*东部均值+0.5*中部值+0.5*西部均值。

3、事后多重比较设置
单击【事后多重设置】,打开【单因素ANOVA:事后多重比较】。该对话框包括假定方差齐性和未假定方差齐性的总共18种两两对比方式,具体不同可以点击SPSS的帮助文档。这里我们选择LSD、Tukey和Tamhane’s T2检验。

4、单击【选项】,打开【单因素ANVOA】,选中描述性、方差齐性检验和平均值图。

结果解释
1、描述性统计表。

从描述性统计量表可以看出东部地区学生的平均身高和中西部的差异较大,而中西部学生的身高平均值接近。
2、方差分析表

由方差齐性检验表可得显著性概率P为0.640,大于0.05,说明东部、中部和西部三组间的方差在0.05水平上没有显著差异,即方差齐性检验通过,这是能够进行方差分析的必要条件。
3、方差分析表和线性对比

从方差分析表可以知道,F值为12.164,对应的显著性为0.000,小于0.05,所以方差分析结果是显著的,表明东部,中部和西部三组学生身高之间是有显著性差异的,具体那一组或那几组之间有差异,需要看事后两两比较。

对三组学生身高的均值赋予不同的系数,然后进行检验。由于是方差齐性的,所以看三个结果,显著性分别为0.000,0.008和0.030,说明三组系数的均值对比均有显著性差异。
4、事后检验表

可以得到两种检验方法的结果基本一致:东部与中部和东部与西部两组均值对比检验的P值均为0.000,说明两组同学间的平均身高差异显著。
5、子集检验表
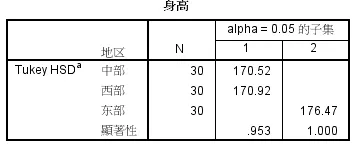

将没有显著性的水平进行子集检验,可以得到中部和西部学生身高之间没有显著性差异,但是与东部学生身高有显著性差异。
6、身高均值折线图
身高均值折线图一样也可看出东部地区和中西部差异显著。
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330