SAS中的聚类分析方法总结
说起聚类分析,相信很多人并不陌生。这篇原创博客我想简单说一下我所理解的聚类分析,欢迎各位高手不吝赐教和拍砖。
按照正常的思路,我大概会说如下几个问题:
1. 什么是聚类分析?
2. 聚类分析有什么用?
3. 聚类分析怎么做?
下面我将分聚类分析概述、聚类分析算法及sas实现、案例三部分来系统的回答这些问题。
聚类分析概述
1. 聚类分析的定义
中国有句俗语叫“物以类聚,人以群分”——剔除这句话的贬义色彩。说白了就是物品根据物品的特征和功用可以分门别类,人和人会根据性格、偏好甚至利益结成不同的群体。分门别类和结成群体之后,同类(同群)之间的物品(人)的特征尽可能相似,不同类(同群)之间的物品(人)的特征尽可能不同。这个过程实际上就是聚类分析。从这个过程我们可以知道如下几点:
1) 聚类分析的对象是物(人),说的理论一点就是样本
2) 聚类分析是根据物或者人的特征来进行聚集的,这里的特征说的理论一点就是变量。当然特征选的不一样,聚类的结果也会不一样;
3) 聚类分析中评判相似的标准非常关键。说的理论一点也就是相似性的度量非常关键;
4) 聚类分析结果的好坏没有统一的评判标准;
2. 聚类分析到底有什么用?
1) 说的官腔一点就是为了更好的认识事物和事情,比如我们可以把人按照地域划分为南方人和北方人,你会发现这种分法有时候也蛮有道理。一般来说南方人习惯吃米饭,北方习惯吃面食;
2) 说的实用一点,可以有效对用户进行细分,提供有针对性的产品和服务。比如银行会将用户分成金卡用户、银卡用户和普通卡用户。这种分法一方面能很好的节约银行的资源,另外一方面也能很好针对不同的用户实习分级服务,提高彼此的满意度。
再比如移动会开发全球通、神州行和动感地带三个套餐或者品牌,实际就是根据移动用户的行为习惯做了很好的用户细分——聚类分析;
3) 上升到理论层面,聚类分析是用户细分里面最为重要的工具,而用户细分则是整个精准营销里面的基础。精准营销是目前普遍接纳而且被采用的一种营销手段和方式。
3. 聚类分析的流程是怎样的?
比较简单的聚类分析往往只根据一个维度来进行,比如讲用户按照付费情况分成高端用户、中端用户和低端用户。这 个只需要根据商业目的统计一下相关数据指定一个高端、中端和低端的分界点标准就可以。
如果是比较复杂的聚类分析,比如移动里面经常会基于用户的多种行为(通话、短信、gprs流失扥等)来对用户进行细分,这个就是比较复杂的用户细分。如果是这样的细分通常会作为一个比较标准的数据挖掘项目来执行,所以基本上会按照数据挖掘的流程来执行。具体分如下几步:
1) 业务理解
主要是了解业务目标和数据挖掘的目标及执行计划
2) 数据理解
主要是弄清楚可已取哪些变量数据,具体怎么定义
3) 数据整理
根据之前的定义提取需要的数据,并进行检测异常数据,并对变量进行挑选及探索,比如最终要用那些变量来执行聚类算法、那些变量是离散变量,需要做特殊处理、
数据大概可以聚成几类、类别形状有不规则的情形吗?
4) 建立模型
关键是选用什么样的距离(相似性度量)和算法:
l 比如是样本比较小,形状也比较规则,可以选用层次聚类
l 比如样本比较大,形状规则,各类的样本量基本相当,可以选用k-means算法
l 比如形状规则,但是各类别之间的样本点的密度差异很大,可以选用基于密度的算法
5) 模型评估
主要是评估聚类分析结果的好坏。实际上聚类分析在机器学习里面被称之为无监督学习,是没有大家公认的评估方法的。所以更多会从业务可解释性的角度去评估
聚类分析的好坏;
6) 模型发布
主要是根据聚类分析的结果根据不同的类的特诊去设计不同的产品、服务或者渠道策略,然后去实施营销
4. 具体在sas里面如何执行?
通过前面的讲解我们已经知道,聚类分析涉及到如下6步,对应着6步SAS都会有相应的过程来执行。
1) 距离的计算:proc distance
2) 数据标准化:proc stdize
3) 聚类变量的选择:proc varclus
4) 初始类别数的选择:proc mds和proc princomp
5) 不规则形状的变换:proc aceclus
6) 算法的选择:层次聚类-proc cluster 划分型聚类-proc fastclus(k-means)和
密度型聚类-proc modeclus
7) 类别特征描述:proc means
以上四个部分就从是什么、为什么、怎么样三个角度对聚类分析做了简单的介绍。接下来的帖子我会重点介绍SAS中各种聚类算法的差异、应用范围及实际的案例。
5. 用proc distance做什么?
我们知道数据变量分四类:名义变量、次序变量、interval变量和ritio变量。但sas里面目前的聚类算法都要求变量时ratio变量。那想要对离散变量进行聚类怎么呢?一种想法自然是讲所有的离散变量都转成0-1变量。这会有如下几个问题:
1) 变量的信息可能会有损失,比如次序型变量转成0-1变量后,次序信息就很难保留;
2) 当离散变量的取值非常多时,转成0-1变量后生成的新变量也会非常多,这样也会造成很多处理上的不便;
3) 0-1变量也没法做标准化等等一些运算,因为这种运算其实是没有意义的
那该如何处理离散变量的聚类呢?答案是用proc distance。我们知道聚类过程中首先是从计算距离或者相似度开始的。一个很自然的想法就是针对离散变量定义有意义的距离(对离散变量和连续变量混合类型的数据)。Proc distance就是用来算这种距离的一个很好的过程。距离或者相似度可以看成是连续数据,自然就可以用sas里面的聚类算法了。
6. 用proc stdize做什么?
前面说过聚类算法首先要算的距离,然后通过距离来执行后续的计算。在距离计算的过程方差比较大的变量影响会更大,这个通常不是我们希望看到。所以非常有必要讲参与聚类的变量转换成方差尽量相同。Proc stdize就能实现这种功能。Proc stdize不仅提供了将变量转换了均值为0,方差转换为1的标准化,还提供了很多其它类型的标准化。比如,range标准化(变量减去最小值除以最大值和最小值得差)
7. 用proc varclus做什么?
在做回归分析的时候,我们知道变量过多会有两个问题:
1) 变量过多会影响预测的准确,尤其当无关紧要的变量引入模型之后;
2) 变量过多不可避免的会引起变量之前的共线性,这个会影响参数估计的精度
聚类分析实际上也存在类似的问题,所以有必要先对变量做降维。说到降维,马上有人会说这个可以用主成分啊,这个的确没错。但是主成分的解释性还是有点差。尤其是第二主成分之后的主成分。那用什么比较好呢?答案是proc varclus——斜交主成分。
我们常说的主成分实际上正交主成分。斜交主成分是在正交主成分的基础上再做了一些旋转。这样得到的主成分不仅能保留主成分的优点(主成分变量相关程度比较低)。另外一方面又能有很到的解释性,并且能达到对变量聚类的效果。使同类别里面的变量尽可能相关程度比较高,不同类别里面的变量相关程度尽可能低。这样根据一定的规则我们就可以在每个类别里面选取一些有代表性的变量,这样既能保证原始的数据信息不致损失太多,也能有效消除共线性。有效提升聚类分析的精度。
8. 用proc mds 和proc princomp做什么?
将原始数据降到两维,通过图形探测整个数据聚类后大致大类别数
9. 用proc aceclus做什么?
聚类算法尤其是k-means算法要求聚类数据是球形数据。如果是细长型的数据或者非凸型数据,这些算法的表现就会相当差。一个很自然的变通想法就是,能不能将非球形数据变换成球形数据呢?答案是可以的。这就要用到proc aceclus。
10. 标准化对聚类分析到底有什么影响?
1) 在讲影响之前先罗列一下proc stdize里面的标准化方法吧
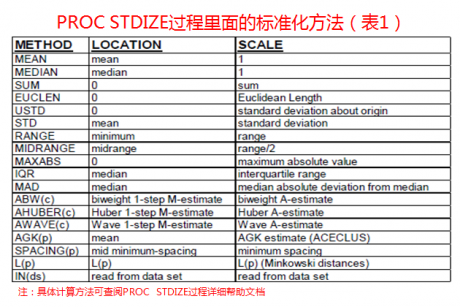
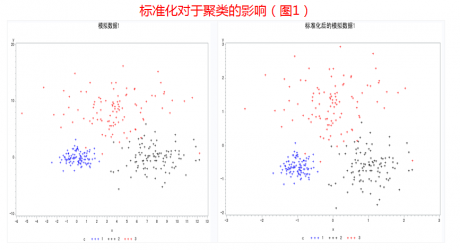
2) 标准化对聚类分析的影响
从图1中不太容易看清楚标准化对于聚类分析的影响
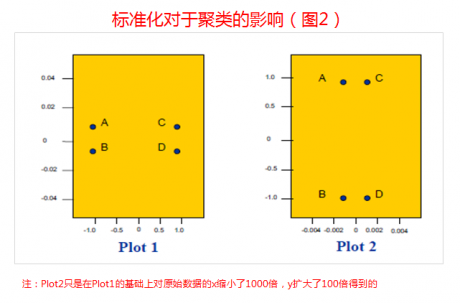
从图2可以清晰的看到标准化对于聚类分析的影响
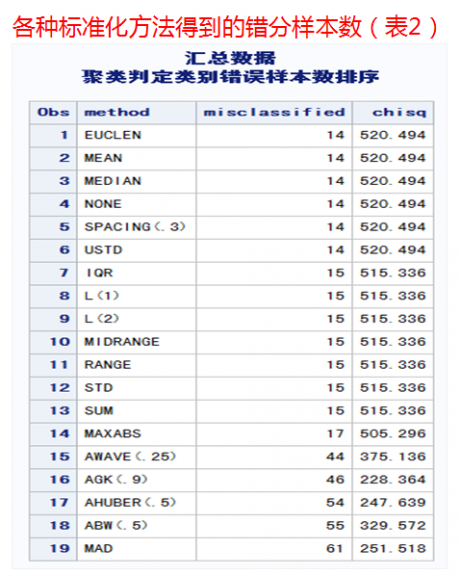
3) 各种标准化方法的比较
一个模拟数据的例子,模拟数据有三个类别,每个类别有100个样本。我们比较了各种标准化方法之后再进行聚类的误判情况,可以大概看出各种标准化方法的差异。但此例并不能说明以下方法中误分类数小的方法就一定优与误分类数大的方法。有时候还跟数据本身的分布特征有关。这个例子也提醒我们有时候我们常用的std和range标准化并不见得是最好的选择。
/*********************************************************/
/*1.模拟数据1;测试标准化方法对聚类的影响
模拟数据,样本量相同,均值和方差不相同*/
/*********************************************************/
data compact;
keep x y c;
n=100;
scale=1; mx=0; my=0; c=1;link generate;
scale=2; mx=8; my=0; c=2;link generate;
scale=3; mx=4; my=8; c=3;link generate;
stop;
generate:
do i=1 to n;
x=rannor(1)*scale+mx;
y=rannor(1)*scale+my;
output;
end;
return;
run;
title ‘模拟数据1’;
proc gplot data=compact;
plot y*x=c;
symbol1 c=blue;
symbol2 c=black;
symbol3 c=red;
run;
proc stdize data=compact method=std
out=scompacted2;
var x y;
run;
title ‘标准化后的模拟数据1’;
proc gplot data=scompacted2;
plot y*x=c;
symbol1 c=blue;
symbol2 c=black;
symbol3 c=red;
run;
/*********************************************************/
/*2.create result table*/
/*********************************************************/
data result;
length method$ 12;
length misclassified 8;
length chisq 8;
stop;
run;
%let inputs=x y;
%let group=c;
%macro standardize(dsn=,nc=,method=);
title “&method”;
%if %bquote(%upcase(&method))=NONE %then %do;
data temp;
set &dsn;
run;
%end;
%else %do;
proc stdize data=&dsn method=&method out=temp;
var &inputs;
run;
%end;
proc fastclus data=temp maxclusters=&nc least=2
out=clusout noprint;
var &inputs;
run;
proc freq data=clusout;
tables &group*cluster / norow nocol nopercent
chisq out=freqout;
output out=stats chisq;
run;
data temp sum;
set freqout end=eof;
by &group;
retain members mode c;
if first.&group then do;
members=0; mode=0;
end;
members=members+count;
if cluster NE . then do;
if count > mode then do;
mode=count;
c=cluster;
end;
end;
if last.&group then do;
cum+(members-mode);
output temp;
end;
if eof then output sum;
run;
proc print data=temp noobs;
var &group c members mode cum;
run;
data result;
merge sum (keep=cum) stats;
if 0 then modify result;
method = “&method”;
misclassified = cum;
chisq = _pchi_;
pchisq = p_pchi;
output result;
run;
%mend standardize;
%standardize(dsn=compact,nc=3,method=ABW(.5));
%standardize(dsn=compact,nc=3,method=AGK(.9));
%standardize(dsn=compact,nc=3,method=AHUBER(.5));
%standardize(dsn=compact,nc=3,method=AWAVE(.25));
%standardize(dsn=compact,nc=3,method=EUCLEN);
%standardize(dsn=compact,nc=3,method=IQR);
%standardize(dsn=compact,nc=3,method=L(1));
%standardize(dsn=compact,nc=3,method=L(2));
%standardize(dsn=compact,nc=3,method=MAD);
%standardize(dsn=compact,nc=3,method=MAXABS);
%standardize(dsn=compact,nc=3,method=MEAN);
%standardize(dsn=compact,nc=3,method=MEDIAN);
%standardize(dsn=compact,nc=3,method=MIDRANGE);
%standardize(dsn=compact,nc=3,method=NONE);
%standardize(dsn=compact,nc=3,method=RANGE);
%standardize(dsn=compact,nc=3,method=SPACING(.3));
%standardize(dsn=compact,nc=3,method=STD);
%standardize(dsn=compact,nc=3,method=SUM);
%standardize(dsn=compact,nc=3,method=USTD);
proc sort data=result;
by misclassified;
run;
title ‘汇总数据’;
title2 ‘聚类判定类别错误样本数排序’;
proc print data=result;
run;
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330