如何利用数据仓库优化数据分析
在整个数据分析流程中,数据处理的时间往往要占据70%以上!这个数字有没有让你震惊呢?为了提高分析效率和质量,借用数据仓库进行数据分析是一个很好的选择,详细的工作方法本文都有所介绍。
首先,我们来了解一下数据仓库吧!数据仓库是一个面向主题的、集成的、相对稳定的、反应历史变化的数据集合。那数据分析又是干什么的呢?笔者凭借个人的经验认为,基于业务需求,结合历史数据,利用相关统计学方法和某些数据挖掘工具对数据进行整合、分析,并形成一套最终解决某个业务场景的方案就是数据分析的过程。
数据分析大致包括以下流程:
业务理解 – 数据理解 – 数据准备 – 建模 – 评估 – 部署
由于数据分析对数据质量、格式的要求天然就比较高,对数据的理解也必须非常深刻,使得数据契合业务需求也要一定的过程,这样,根据我们的经验,在整个数据分析流程中,用于数据处理的时间往往要占据70%以上。
因此,如何高效、快速地进行数据理解和处理,往往决定了数据分析项目的进度和质量。而数据仓库具有集成、稳定、高质量等特点,基于数据仓库为数据分析提供数据,往往能够更加保证数据质量和数据完整性。
利用数据仓库进行数据分析无疑能够给我们的工作带来很大便利,那么,究竟要如何操作呢?我们首先需要了解数据仓库的优势,数据仓库至少可以从如下三个方面提升数据分析效率:
1. 数据理解
数据仓库是面向主题的,所以其自身与业务结合就相对紧密和完善,更方便数据分析师基于数据理解业务。下图是Teradata关于金融行业的成熟模型:
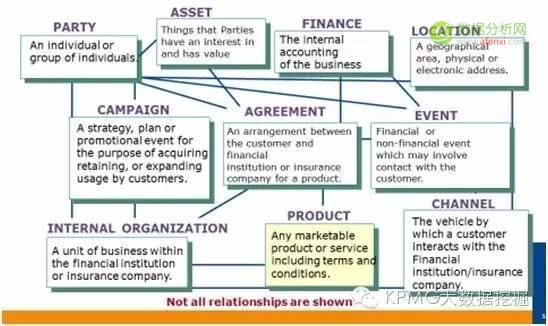
(出自Teradata FS-LDM官方文档)
我们可以看到,整个数据仓库被分为十大主题,而金融行业所有的数据、业务都会被这十大主题涵盖。当我们需要找某个信用卡账户信息时,我们就去协议(AGREEMENT)主题,需要某次存款交易信息时就去探寻事件(EVENT)主题,需要某个理财产品相关信息就挖掘产品(PRODUCT)主题,如此类推,我们就会发现十大主题将整个金融行业的数据划分得非常清晰,我们需要做的就是拿到业务需求,理解数据仓库的模型,数据理解也就水到渠成了。
2. 数据质量
数据分析要求数据是干净、完整的,而数据仓库最核心的一项工作就是ETL过程,流程如下:

而数据仓库已经对源系统的数据进行了业务契合的转换,以及脏数据的清洗,这就为数据分析的数据质量做了较好的保障。
3. 数据跨系统关联
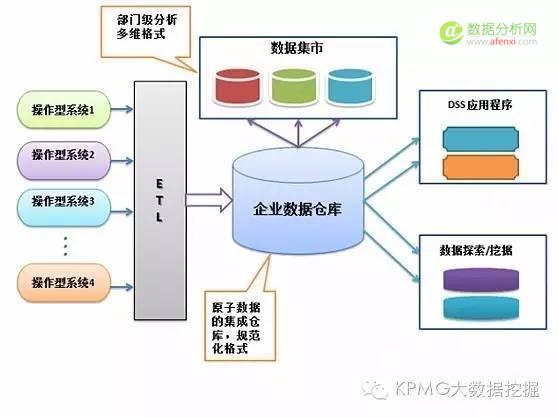
上图是数据仓库的一个简单架构,可以看到,各业务源系统的数据经过ETL过程后流入数据仓库,当不同系统数据整合到数据仓库之后,至少解决了数据分析中的两个问题:
第一,跨系统数据收集问题,同一个客户的储蓄交易和理财交易我们在同一张事件表就可以找到;
第二,跨系统关联问题,同一个客户可能在不同系统中记录了不同的客户号,甚至存在不同的账号,进行数据整合时,总是需要找到共同的“纽带”来关联来自不同系统的信息,而数据仓库在ETL过程中就会整合相关客户信息,完美解决跨系统关联问题。
可见,数据仓库是整合的、面向主题的、数据质量高的、跨系统的优质数据源,那么,我们该如何充分利用这些优势呢?笔者总结了如下经验:
1. 研究数据仓库模型:数仓的精髓就是面向主题的模型,能理解各大主题域范畴,熟悉不同主题间的关系,基本就掌握了数仓的架构;
2. 学习数据仓库设计文档:设计文档是业务与数据,数仓与源系统的桥梁,熟悉表间mapping映射,就能快速定位需求变量的来源和处理逻辑,全面了解相关业务;
3. 熟悉数据字典表:数据字典是数据仓库物理存储的信息库,可以通过数据字典了解库、表、字段不同层级的关系、存储、类型等信息;
4. 研究ETL脚本:学习几个数据仓库ETL加工脚本,能更细致的探索数据加工处理逻辑,更清楚的理解数仓加工模式,快速掌握数据加工技巧;
5. 观察明细数据:想要真正了解数据,就必须对具体数据进行不同维度和层次的观察;比如事件表,从交易类型、时间、渠道、业务种类等多个维度捞几条数据,观察某个相同条件下不同维度的交易变化,了解银行交易的全景信息,帮助理解业务,熟悉数据。
事实上,除此之外,数据处理人员还应该从中学习到数据仓库的思想:面向主题,逐层加工。
面向主题是指让杂乱的数据结合业务划分,更容易着手处理原本杂乱的数据,数据处理人员只需知道哪些数据属于哪个主题,然后基于主题再进一步处理;逐层加工则是指让细粒度的数据走向宽表的过程清晰,有层次,数据处理过程中清楚每一步的产出是什么。
其实,每一个数据分析师或者数据处理师都会有自己的工作习惯和经验,以上是笔者经历两年多数据仓库开发、三年数据仓库和数据分析兼职者的经验总结的一些心得,希望对大家有所帮助。
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330