异常检测算法--Isolation Forest
提到森林,自然少不了树,毕竟森林都是由树构成的,看Isolation Forest(简称iForest)前,我们先来看看Isolation Tree(简称iTree)是怎么构成的,iTree是一种随机二叉树,每个节点要么有两个女儿,要么就是叶子节点,一个孩子都没有。给定一堆数据集D,这里D的所有属性都是连续型的变量,iTree的构成过程如下:
-
随机选择一个属性Attr;
-
随机选择该属性的一个值Value;
-
根据Attr对每条记录进行分类,把Attr小于Value的记录放在左女儿,把大于等于Value的记录放在右孩子;
-
然后递归的构造左女儿和右女儿,直到满足以下条件:
-
传入的数据集只有一条记录或者多条一样的记录;
-
树的高度达到了限定高度;

iTree构建好了后,就可以对数据进行预测啦,预测的过程就是把测试记录在iTree上走一下,看测试记录落在哪个叶子节点。iTree能有效检测异常的假设是:异常点一般都是非常稀有的,在iTree中会很快被划分到叶子节点,因此可以用叶子节点到根节点的路径h(x)长度来判断一条记录x是否是异常点;对于一个包含n条记录的数据集,其构造的树的高度最小值为log(n),最大值为n-1,论文提到说用log(n)和n-1归一化不能保证有界和不方便比较,用一个稍微复杂一点的归一化公式:
s(x,n)=2(−h(x)c(n))s(x,n)=2(−h(x)c(n))
,
c(n)=2H(n−1)−(2(n−1)/n),其中H(k)=ln(k)+ξ,ξ为欧拉常数c(n)=2H(n−1)−(2(n−1)/n),其中H(k)=ln(k)+ξ,ξ为欧拉常数
s(x,n)s(x,n)就是记录x在由n个样本的训练数据构成的iTree的异常指数,s(x,n)s(x,n)取值范围为[0,1],越接近1表示是异常点的可能性高,越接近0表示是正常点的可能性比较高,如果大部分的训练样本的s(x,n)都接近于0.5,说明整个数据集都没有明显的异常值。
随机选属性,随机选属性值,一棵树这么随便搞肯定是不靠谱,但是把多棵树结合起来就变强大了;
iForest
iTree搞明白了,我们现在来看看iForest是怎么构造的,给定一个包含n条记录的数据集D,如何构造一个iForest。iForest和Random Forest的方法有些类似,都是随机采样一一部分数据集去构造每一棵树,保证不同树之间的差异性,不过iForest与RF不同,采样的数据量PsiPsi不需要等于n,可以远远小于n,论文中提到采样大小超过256效果就提升不大了,明确越大还会造成计算时间的上的浪费,为什么不像其他算法一样,数据越多效果越好呢,可以看看下面这两个个图,
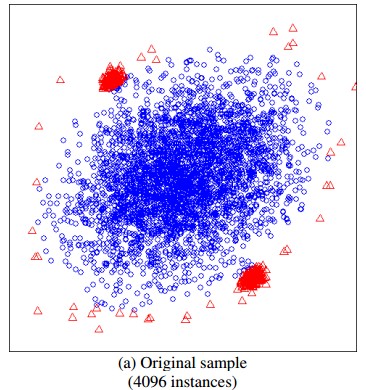
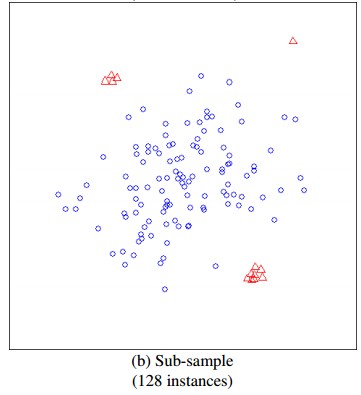
左边是元素数据,右边是采样了数据,蓝色是正常样本,红色是异常样本。可以看到,在采样之前,正常样本和异常样本出现重叠,因此很难分开,但我们采样之和,异常样本和正常样本可以明显的分开。
除了限制采样大小以外,还要给每棵iTree设置最大高度l=ceiling(logΨ2)l=ceiling(log2Ψ),这是因为异常数据记录都比较少,其路径长度也比较低,而我们也只需要把正常记录和异常记录区分开来,因此只需要关心低于平均高度的部分就好,这样算法效率更高,不过这样调整了后,后面可以看到计算h(x)h(x)需要一点点改进,先看iForest的伪代码:

IForest构造好后,对测试进行预测时,需要进行综合每棵树的结果,于是
s(x,n)=2(−E(h(x))c(n))s(x,n)=2(−E(h(x))c(n))
E(h(x))E(h(x))表示记录x在每棵树的高度均值,另外h(x)计算需要改进,在生成叶节点时,算法记录了叶节点包含的记录数量,这时候要用这个数量SizeSize估计一下平均高度,h(x)的计算方法如下:

处理高维数据
在处理高维数据时,可以对算法进行改进,采样之后并不是把所有的属性都用上,而是用峰度系数Kurtosis挑选一些有价值的属性,再进行iTree的构造,这跟随机森林就更像了,随机选记录,再随机选属性。
只使用正常样本
这个算法本质上是一个无监督学习,不需要数据的类标,有时候异常数据太少了,少到我们只舍得拿这几个异常样本进行测试,不能进行训练,论文提到只用正常样本构建IForest也是可行的,效果有降低,但也还不错,并可以通过适当调整采样大小来提高效果。
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330