如何使用队列数据分析来留住你的用户
在数据分析的世界中,队列分析因为看似非常复杂而总是被人忽视。这一次让我们来看一看队列分析究竟能为我们提供什么?以及怎样进行这种分析。
在种种数据分析工具中,有一种工具经常不被人使用,那就是队列分析。虽然队列分析是一种非常强大的分析方式,但因为它看起来非常复杂而总是被人放在一边。然而,队列分析能够为我们提供大量的有效结果,今天就让我们深入浅出的了解一下它。
让我们首先来解释一下什么是队列分析。队列分析能够帮助你在特定的时间段对具有共同特征的一组人群的行为动作进行分析。它能够让你通过更加精密的“显微镜”来观察数据,将一个大难题拆分成细碎的拼图,然后在每块拼图上展示出细节。
例如,对于每一个开发者或者分析师来说,他们最想知道的数据分析结果之一就是应用的保留率。因为你有很多种办法可以让人们去下载你的应用,但是你会非常希望知道有多少人最终保留了你的应用。保留率是一个关键的指标。正如人们所说的:“留住用户而不是获得用户才意味着真正的增长。”在这种情况下,你需要分析安装移动应用的用户数据,以及在5天内与该应用进行了交互的用户数据,用来测量保留率。
这些信息一般会以如下的表格形式显示:
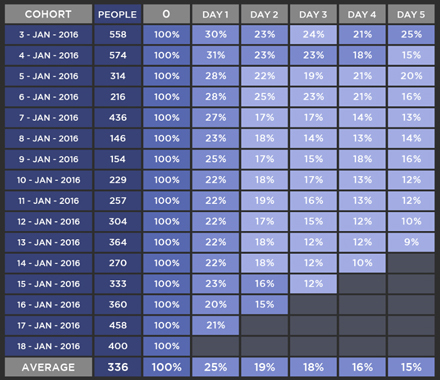
在上表中,558位用户在1月3日安装了应用,在其中有30%的用户在一天之后回来访问了这个应用,有23%的用户在两天以后访问了这个应用,有24%是在3天以后,21%是在4天以后,而25%是在5天之后。
这种类型的数据让人很难清楚地理解数字之间的关系并且作出快速的推断。作为一名分析师,你会希望通过这5天的数字了解保留率的趋势以及在日期与日期之间的趋势,比如在安装以后第1天与第3天之间的保留情况。
此外,你还需要测量保留用户与安装用户的总数量。这些数字对于队列分析是非常有用的,如果保留率比较低但安装用户很高,那么这显然是不希望看到的。
假设我们想看到应用安装后第1天、第3天和第5天的保留数量,那么通过队列分析,数据就可以以下面的视图总结并展示出来:
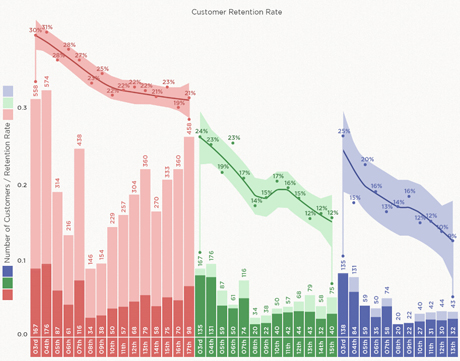
上面的图表展示了所选定时间段中每天的队列数据变化情况。这3个队列分别代表第1天、第3天和第5天。
图表中竖条的浅色与深色分别代表了用户总数与保留用户的数量。粉色竖条显示的是到第1天日末当天队列数据的变化情况。绿色显示的是从第1天到第3天的变化情况。而紫色则显示的是从第3天到第5天的每日队列数据变化情况。在第1天也就是1月3日总共安装用户为558人,而留存用户则是深粉色显示的167人。绿色图表的显示也是一致的。在第3天,总用户是第1天留存的167人,而在这167人中只有135个人保留住了,因此显示出一个向下的趋势。
在图标顶部的曲线显示的是趋势分析。粉色、绿色和蓝色的平滑曲线分别代表着第1天、第3天和第5天的保留率队列变化情况,围绕着曲线的3种颜色的带状区域是保留率的可信区间。
分析结果:
用户保留率出现了明显的下降趋势。在应用安装的第3天之后出现了急剧的下降,下降原因需要进一步探讨。
1月3日获取的用户在第3天到第5天之间表现出了最高的保留率,几乎没有下降,和其他区间的队列数据完全不同,需要深入的了解1月3日所获取用户的类型以及特点。此外,用户总量在这个阶段也是最高的。
在1月4日获取的用户在第5天的保留率相较于第1天与第3天都要低。保留率低于可信区间的下限。
1月6日获取的用户的第3天保留率明显高于其他区间。23%的保留率超过了可信区间的上限。
数据显示1月17日的用户获取数量出现了一次高峰。
通过应用队列分析我们可以了解到很多信息,能够获取总体趋势、特定区间的趋势以及与其它信息包括实施营销策略与获取用户策略相混合时的各种趋势,能够帮助我们得出合理的结论,进一步制定更有效的用户获取与用户保留策略。
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330