
逻辑回归是数据分析、机器学习、统计建模中应用最广泛的二分类预测模型,常用于风险判断、行为预测、归因分析等场景。在SPSS、Python、R语言等主流分析工具中,构建逻辑回归模型时,所有自变量会被划分为**因子(Fac ...
2026-06-02
数字经济时代,市场竞争日趋同质化,用户消费需求愈发个性化、多元化,传统依托经验、粗放式、广撒网的营销模式弊端日益凸显。长期以来,企业普遍面临营销成本高、投放精准度低、用户转化弱、复购留存差、广告ROI难 ...
2026-06-02
很多数据分析师做过按月份的销售额趋势图,画过按天的流量折线图,但当被问到“时间序列和普通数据有什么本质区别”“季节性和周期性怎么区分”“预测时为什么需要先判断平稳性”时,却常常答不上来。其实,多数 ...
2026-06-02
在市场竞争日趋饱和、用户需求不断细分的当下,企业创业创新、产品迭代与市场拓展不再依赖经验决策,而是需要系统化、工具化的商业逻辑支撑。STP模型、价值主张画布、精益画布是商业分析、产品规划、市场运营中三大 ...
2026-06-01
【核心关键词】调度、岗位、数据库、企业、报表、培训、程序、数据分析、数据加工、业务部门、企业数据、调度工具、业务指标、数据统计、需求承接、数据需求、指标数据、部门需求 【专访摘要】本次CDA持证专访邀请 ...
2026-06-01
很多数据分析师能熟练地计算指标、搭建标签体系,但当被问到“画像到底在解决什么问题”“画像和标签是什么关系”“画像如何指导业务”时,却常常答不上来。其实,标签是对一个用户“打点描述”,画像是对一群人 ...
2026-06-01
在数据统计分析、数据清洗、异常值识别与数据分布研究中,箱型图是最直观、高效、专业的可视化分析工具。相较于柱状图、折线图仅能展示数据大小与变化趋势,箱型图能够完整呈现数据的集中趋势、离散程度、分布偏态与 ...
2026-05-29
Tkinter是Python内置的标准GUI图形界面库,具备无需额外安装、调用简单、兼容性强、轻量化高效等优势,是Python快速开发桌面小程序、工具软件、可视化系统的首选框架。原生Tkinter控件样式老旧、界面单调、色彩单一 ...
2026-05-29
很多分析师在设计标签时思路清晰,但真到落地环节却面临“数据在手,不知如何转化为可用标签”的困境:或因加工方式选择不当导致标签失效,或因规则模糊造成标签口径混乱。其实,好的标签并非设计出来,而是加工 ...
2026-05-29
【核心关键词】大数据、经理、专业、金融、客户、传统、建模、数据产品、互联网金融、产品经理、数据分析、金融行业、数据模型、数据仓库、工作需求、指标体系、数据建模、维度指标 【专访摘要】本次CDA持证专访邀 ...
2026-05-28
很多分析师每天和数据打交道,但当被问到“标签是什么”“标签和指标有什么区别”“标签体系如何设计”时,却常常答不上来。其实,零散的指标告诉你“数字是什么”,系统的标签体系告诉你“业务为什么”。标签体 ...
2026-05-28
随着大数据技术的快速普及,各行各业积累了海量的用户数据、交易数据、生产数据与行为数据。单纯的数据统计与报表分析只能呈现表面结果,无法挖掘数据背后隐藏的关联规律、潜在风险与未来趋势。而数据挖掘正是依托统 ...
2026-05-28
在Python网络请求、接口测试、数据爬取、业务对接开发中,Requests库是最简洁、最高效的HTTP请求工具,凭借简洁的语法、完善的适配性,替代了Python内置的urllib库,成为开发者对接网络接口、获取网络数据的首选工具 ...
2026-05-27
2025 年,零售与服务行业的竞争已从 “经验驱动” 全面转向 “数据驱动”。中小企业门店普遍面临数据零散、分析浅层、决策凭感觉的痛点:只看营业额,却不知客流为何下滑;只做促销,却不懂转化低效根源;只维护老客 ...
2026-05-27
很多数据分析师每天都在写SQL,但当被问到“数据查询语言(DQL)的本质是什么”“SELECT语句中各子句的书写顺序与实际执行顺序有什么区别”“INNER JOIN和LEFT JOIN在业务分析中分别适用什么场景”时,却常常语 ...
2026-05-27
在统计学分析、实验研究、业务数据复盘过程中,单因素方差分析是检验自变量对因变量是否存在显著影响的核心方法。其中,两个水平单因素方差分析是单因素方差分析的基础场景,指仅包含一个自变量、且该自变量仅有两个 ...
2026-05-26
【核心关键词】算法、客户、大数据、互联网、调优、建模、模型优化、机器学习、评分卡模型、模型开发、智能风控、业务场景、数字化转型、模型运营、模型评估、运营分析、模型调优、模型逻辑 【专访摘要】本次CDA持 ...
2026-05-26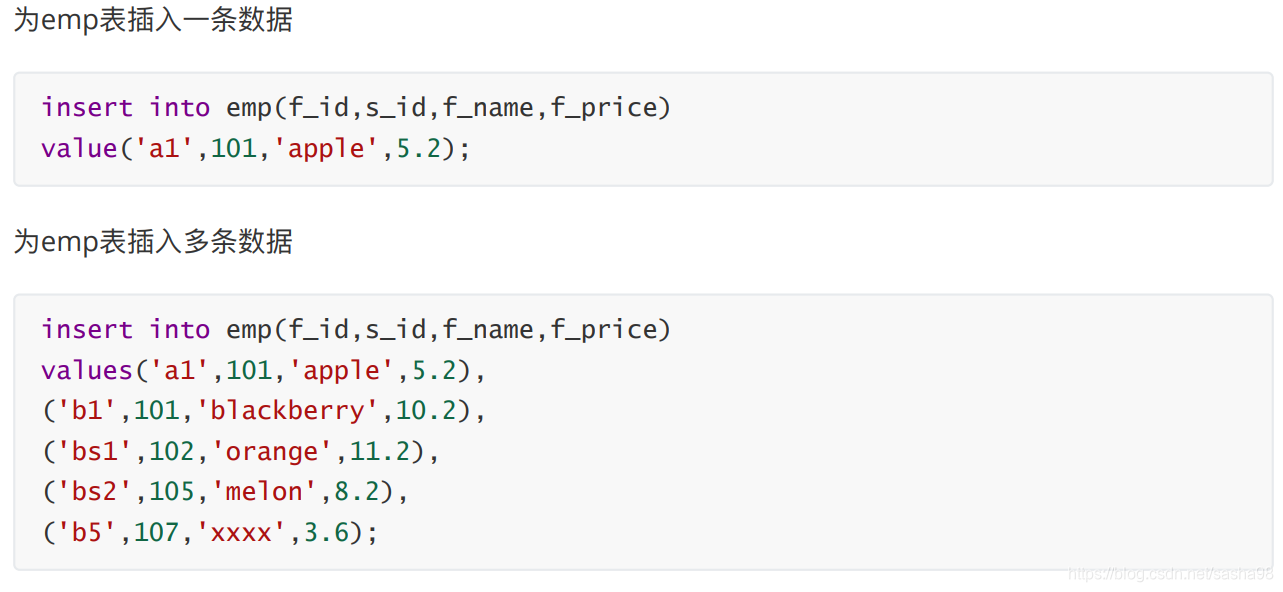
很多数据分析师写过无数个 SELECT,但当被问到“新建一张表,该如何定义字段类型来保证数据质量”“创建视图和存储物理表有什么区别,分别应该在什么业务场景下使用”时,却常常陷入支支吾吾的困境。其实,CURD ...
2026-05-26
在数据清洗、统计分析与数据质量检测工作中,箱型图(又称箱线图、Box Plot)是最直观、最高效的可视化分析工具之一。相较于柱状图、折线图仅能展示数据大小与变化趋势,箱型图可以完整呈现数据的分布特征、集中趋势 ...
2026-05-25
在大数据分析、数据清洗、质量管控、风险监测等领域,异常数据识别是保障数据质量、确保分析结论精准、规避业务决策失误的核心基础。数据集中存在的极端异常值,会严重扭曲均值、标准差等统计指标,破坏数据分布规律 ...
2026-05-25在问卷调研的数据分析流程中,“先检验信效度,再开展进阶统计分析”是通用的规范逻辑。很多从业者会听到“问卷效度高,后续可以 ...
2026-07-30【核心关键词】大数据、统计学、专业、毕业生、论文、课程、计算机、建模、知识、数据分析、机器学习、数据科学、大数据技术、 ...
2026-07-30 很多数据分析师掌握了Excel函数、会写SQL查询,但当被问到“数据从哪里来”“数据加工有哪些步骤”“如何使用分析工具连接数 ...
2026-07-30在业务数据分析中,按天拆分统计夜间时段的数据是高频需求——比如电商夜间订单监测、平台夜间用户活跃度分析、运维系统夜间异常 ...
2026-07-29在机器学习建模与特征工程实践中,判断不同特征对模型预测效果的贡献度,是特征筛选、模型解释、业务归因的核心环节。特征置换重 ...
2026-07-29 很多数据分析师精通Excel单元格操作,但当被问到“表结构数据的基本处理单位是什么”“字段和记录的本质区别”“为什么表结 ...
2026-07-29【核心关键词】岗位、数字化、经验、课程、方法论、决策、企业、大方向、数据分析、销售管理、理论知识、思维方式、分析销售、 ...
2026-07-28在问卷调研、用户分群、效果对比等业务数据分析中,分类变量的关联性与差异性验证是高频需求。卡方检验作为针对离散分类数据的经 ...
2026-07-28 数据分析师八成以上的时间在和数据表格打交道,但许多人拿到Excel后习惯性地先算、先分析,结果回头发现漏了一列关键数据, ...
2026-07-28在Excel数据分析与报表制作中,数据透视表是快速完成多维度汇总、分组统计的核心工具。很多从业者在得到透视表汇总结果后,为了 ...
2026-07-27 很多数据分析师每天与Excel打交道,但当被问到“表格结构数据的基本处理单位是什么”“数据类型误判会引发哪些分析错误”“ ...
2026-07-27当下,我们已然步入数据要素价值全面释放的智能时代。数据不再只是零散的数字记录,更是驱动新质生产力运转的核心动能、滋养人工 ...
2026-07-27【核心关键词】客户、数据分析、指标体系、数据采集、数据指标、业务数据、分析思路、业务需求、分析方法 【专访摘要】本次 CDA ...
2026-07-24在数据分析、业务建模与数字化运营体系中,原始业务数据普遍存在缺失、重复、异常、口径不一致等质量问题,直接用于分析与建模会 ...
2026-07-24 很多数据分析师能熟练计算均值、标准差,但当被问到“如何用一张图让业务方3秒内看懂核心结论”“面对不同数据类型该怎么选 ...
2026-07-24在数据驱动的精细化运营体系中,指标是业务判断、效果复盘、策略优化的核心依据。随着企业数据化程度提升,指标数量持续膨胀,但 ...
2026-07-23在用户运营与产品增长体系中,留存是衡量产品真实价值与用户粘性的核心标尺,也是决定用户生命周期价值、获客投产比的底层因素。 ...
2026-07-23 很多数据分析师精通Excel、SQL、Python等工具,但当被问到“面对一个具体的业务问题,该用什么分析方法”“描述性分析和诊断 ...
2026-07-23【核心关键词】埋点、产品、互联网、数据库、决策、数据分析、产品经理、商业模式、移动互联网、指标体系、运营模块、大数据平 ...
2026-07-22在高并发、大数据量的业务系统中,单表数据量达到千万级甚至亿级后,会出现查询性能骤降、索引维护成本飙升、存储扩容困难等问题 ...
2026-07-22





