考虑一种棘手的情况:训练数据中大部分样本没有标签。此时,我们可以考虑使用半监督学习方法来处理。半监督学习能够利用这些额外的未标记数据,更好地捕捉数据分布的潜在形状,并在新样本上的泛化能力更强。当我们只有非常少量的已标记数据,同时有大量未标记数据点时,这种算法可以表现得非常出色。
在sklearn中,基于图算法的半监督学习有Label Propagation和Label Spreading两种。他们的主要区别是第二种方法带有正则化机制。
一、Label Propagation
基本原理:
Label Propagation算法基于图理论。算法首先构建一个图,其中每个节点代表一个数据点,无论是标记的还是未标记的。节点之间的边代表数据点之间的相似性。算法的目的是通过图传播标签信息,使未标记数据获得标签。
关键特点:
相似性度量:通常使用K近邻(KNN)或者基于核的方法来定义数据点之间的相似性。
标签传播:标签信息从标记数据点传播到未标记数据点,通过迭代过程实现。
适用场景:适合于数据量较大、标记数据稀缺的情况。
二、Label Spreading
基本原理:
Label Spreading和Label Propagation非常相似,但在处理标签信息和正则化方面有所不同。它同样基于构建图来传播标签。
关键特点:
正则化机制:Label Spreading引入了正则化参数,可以控制标签传播的过程,使算法更加健壮。
稳定性:由于正则化的存在,Label Spreading在面对噪声数据时通常比Label Propagation更稳定。
适用场景:同样适用于有大量未标记数据的情况,尤其当数据包含噪声时。
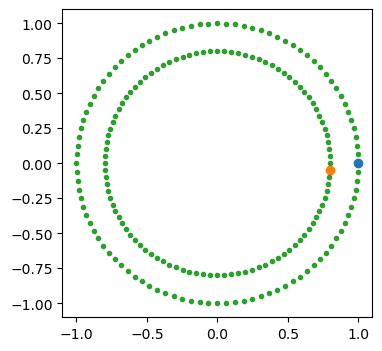
本文首先介绍Label Propagation,带有正则的Label Spreading 将在下篇介绍。首先生成一些凹的数据。
import numpy as np
from sklearn.datasets import make_circles
X, y = make_circles(n_samples=200, shuffle=False)
outer, inner = 0, 1
labels = np.full(200, -1.0)
labels[0] = outer
labels[-1] = inner
import matplotlib.pyplot as plt
plt.figure(figsize=(4, 4))
plt.scatter(X[labels == outer, 0], X[labels == outer, 1],)
plt.scatter(X[labels == inner, 0], X[labels == inner, 1],)
plt.scatter(X[labels == -1, 0], X[labels == -1, 1], marker=".",);
标签处理是CDA数据分析师二级考试的核心内容,在给工商银行等银行做内训时,这一部分技能是银行最重视的,因为银行防作弊放欺诈最核心的就是对用户打标签,如果大家想提升这块的能力,点击下方链接。
Label Propagation算法的迭代计算过程是基于图论原理的。在这个过程中,算法首先构建一个图,其中每个节点代表一个数据点,然后通过图中的连接来传播标签信息。下面是详细的步骤介绍:
1、构建图
首先,算法构建一个图,图中的每个节点代表一个数据样本。这些节点包括已标记的节点和未标记的节点。
2、确定相似性权重
在图中,节点之间的边代表数据点之间的相似性。这种相似性通常通过一些度量来计算,比如欧几里得距离(用于K近邻方法)或者基于核的相似性函数(如高斯核)。每条边的权重反映了两个节点之间的相似度。
3、初始化标签信息
对于每个数据点,算法维护一个标签分布向量。对于已标记的数据点,这个向量直接反映了其标签信息。对于未标记的数据点,标签分布初始通常是均匀的,或者用其他方式初始化。
4、迭代更新标签
接下来,算法进入迭代过程。在每次迭代中,每个未标记节点的标签信息会根据其邻居节点(包括已标记和未标记的节点)的标签信息进行更新。具体来说,一个节点的新标签分布是其所有邻居节点的标签分布的加权平均,权重由相似性权重决定。
5、归一化
更新完所有未标记节点的标签分布后,通常需要对这些分布进行归一化处理,以确保它们表示有效的概率分布。
6、收敛判断
这个过程会不断迭代,直到达到某个收敛条件,比如迭代次数达到预设的上限,或者标签分布的变化小于某个阈值。
7、确定最终标签
一旦算法收敛,每个未标记数据点的标签被确定为其标签分布中概率最高的标签。
from sklearn.semi_supervised import LabelPropagation
label_propagation = LabelPropagation(kernel="knn")
label_propagation.fit(X, labels)
output= np.asarray(label_propagation.transduction_)
outer_numbers = np.where(output == outer)[0]
inner_numbers = np.where(output == inner)[0]
plt.figure(figsize=(4, 4))
plt.scatter(X[outer_numbers, 0], X[outer_numbers, 1],)
plt.scatter(X[inner_numbers, 0], X[inner_numbers, 1],);
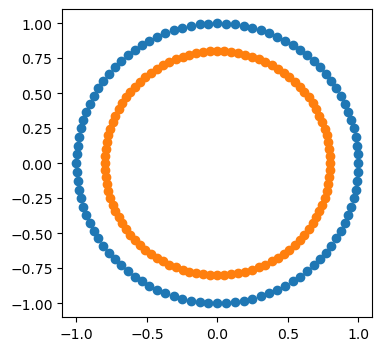
注意参数kernel="knn"。可以发现,若把kernel换成rbf,则无法得到正确传播结果。这是因为rbf是考虑全局的数据分布,因此内圈初始的标签扩散出去后很难被更新。KNN只考虑局部,不会出现此问题。
数据点分布稀疏,且局部邻域信息足够区分标签(如聚类明显的情况下)。
RBF 图
数据点分布紧密,且需要捕获全局信息(如图像或文本的复杂分布)。
抓住机遇,狠狠提升自己
随着各行各业进行数字化转型,数据分析能力已经成了职场的刚需能力,这也是这两年CDA数据分析师大火的原因。和领导提建议再说“我感觉”“我觉得”,自己都觉得心虚,如果说“数据分析发现……”,肯定更有说服力。想在职场精进一步还是要学习数据分析的,统计学、概率论、商业模型、SQL,Python还是要会一些,能让你工作效率提升不少。备考CDA数据分析师的过程就是个自我提升的过程。

CDA 考试官方报名入口:https://www.cdaglobal.com/pinggu.html











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330