热度碾压 Java、C#、C++的 Python,为什么速度那么慢
眼下 Python 异常火爆,不论是 DevOps、数据科学、Web 开发还是安全领域,都在用 Python——但是它在速度上却没有任何优势。
与
C、C++、C# 或 Python 相比,Java
的速度如何?答案很大程度上依赖于你需要运行的应用种类。世上没有完美的性能测试,但计算机语言评测游戏(Computer Language
Benchmarks Game)是个很好的测试方式:http://algs4.cs.princeton.edu/faq/。
我从十年前就开始谈论计算机语言评测游戏。与
Java、C#、Go、Java、C++ 等其他语言相比,Python 是最慢的语言之一。这里包括JIT(Just In
Time)语言(如C#、Java)和 AOT(Ahead Of Time)语言(C、C++)编译器,也有 Java 这种解释语言。

注:本文中所说的“Python”是指语言的具体实现,即 CPython。本文也会提到其他运行。
我希望回答以下问题:如果 Python 完成相同的任务要花费其他语言二至十倍的时间,那么它为什么慢,能不能更快一些呢?
以下是几种常见的原因:
-
“因为它是GIL(全局解释器锁)”
-
“因为它是解释语言不是编译语言”
-
“因为它是动态类型语言”
究竟哪个原因对性能的影响最大?
“因为它是GIL”
现代计算机的
CPU 有多个核心,有时甚至有多个处理器。为了利用所有计算能力,操作系统定义了一个底层结构,叫做线程,而一个进程(例如
Chrome浏览器)能够生成多个线程,通过线程来执行系统指令。这样如果一个进程是要使用很多
CPU,那么计算负载就会由多个核心分担,最终使得绝大多数应用能更快地完成任务。
在撰写本文时,我的 Chrome 浏览器开了 44 个线程。另外,基于 POSIX 的操作系统(如 Mac OS 和 Linux)的线程结构和 API 与 Windows 操作系统是不一样的。操作系统还负责线程的调度。
如果你没写过多线程程序,那么你应该了解一下锁的概念。与单线程进程不同,在多线程编程中,你要确保改变内存中的变量时,多个线程不会试图同时修改或访问同一个内存地址。
CPython 在创建变量时会分配内存,然后用一个计数器计算对该变量的引用的次数。这个概念叫做“引用计数”。如果引用的数目为 0,那就可以将这个变量从系统中释放掉。这样,创建“临时”变量(如在 for 循环的上下文环境中)不会耗光应用程序的内存。
随之而来的问题就是,如果变量在多个线程中共享,CPython 需要对引用计数器加锁。有一个“全局解释器锁”会谨慎地控制线程的执行。不管有多少个线程,解释器一次只能执行一个操作。
这对 Python 应用的性能有什么影响?
如果应用程序是单线程、单解释器的,那么这不会对速度有任何影响。去掉 GIL 也不会影响代码的性能。
但如果想用一个解释器(一个 Python 进程)通过线程实现并发,而且线程是IO 密集型的(即有很多网络输入输出或磁盘输入输出),那么就会出现下面这种 GIL 竞争:

来自于David Beazley的“图解GIL”一文:http://dabeaz.blogspot.com/2010/01/python-gil-visualized.html
如果 Web
应用(如 Django)使用了 WSGI,那么发往 Web 应用的每个请求都会由独立的 Python
解释器执行,因此每个请求都只会有一个锁。由于 Python 解释器启动很慢,一些 WSGI 实现就支持“守护模式”,保持 Python
进程长期运行。
其他 Python 运行时如何?
PyPy 的 GIL 通常要比 CPython 快三倍以上。
Jython 没有 GIL 因为 Jython 中的 Python 线程由 Java 线程表示,因此能享受到 JVM 内存管理系统的好处。
Java 怎么处理这个问题i?
首先,所有 Java 引擎都是用标记-清除垃圾回收算法。如前所述,对 GIL 的需求主要是由 CPython 的内存管理算法导致的。
Java 没有 GIL,但它也是单线程的,所以它根本不需要。Java 的时间循环和 Promise/Callback 模式实现了异步编程,取代了并发编程。Python 也能通过 asyncio 的事件循环实现类似的模式。
“因为它是解释语言”
这条理由我也听过很多,我发现它过于简化了 CPython 的实际工作原理。当你在终端上写 python my.py 时,CPython 会启动一长串操作,包括读取、词法分析、语法分析、编译、解释以及执行。
如果你对这些过程感兴趣,可以看看我之前写的文章:
6分钟修改Python语言:https://hackernoon.com/modifying-the-python-language-in-7-minutes-b94b0a99ce14
这个过程的重点就是它会在编译阶段生成.pyc文件,字节码会写到__pycache__/下的文件中(如果是Python 3),或者写到与源代码同一个目录中(Python 2)。不仅你编写的脚本是这样,所有你导入的代码都是这样,包括第三方模块。
因此绝大多数情况下(除非你写的代码只会运行一次),Python是在解释字节码并在本地执行。与Java和C#.NET比较一下:
Java将源代码编译成“中间语言”,然后Java虚拟机读取字节码并即时编译成机器码。.NET CIL也是一样的,.NET的公共语言运行时(CLR)使用即时编译将字节码编译成机器码。
那么,既然它们都使用虚拟机,以及某种字节码,为什么Python在性能测试中比Java和C#慢那么多?第一个原因是,.NET和Java是即时编译的(JIT)。
即时编译,即JIT(Just-in-time),需要一种中间语言,将代码分割成小块(或者称帧)。而提前编译(Ahead of Time,简称AOT)是编译器把源代码翻译成CPU能理解的代码之后再执行。
JIT本身并不能让执行更快,因为它执行的是同样的字节码序列。但是,JIT可以在运行时做出优化。好的GIT优化器能找到应用程序中执行最多的部分,称为“热点”。然后对那些字节码进行优化,将它们替换成效率更高的代码。
这就是说,如果你的应用程序会反复做某件事情,那么速度就会快很多。此外,别忘了Java和C#都是强类型语言,所以优化器可以对代码做更多的假设。
前面说过,PyPy有个JIT,因此它比CPython要快很多。下面这篇性能测试的文章介绍得更详细:
哪个版本的Python最快?
https://hackernoon.com/which-is-the-fastest-version-of-python-2ae7c61a6b2b
那么为什么CPython不用JIT?
JIT也有缺点:首先就是启动速度。CPython的启动速度已经比较慢了,而PyPy的启动速度要比CPython慢两到三倍。Java虚拟机的启动速度也是出了名的慢。.NET
CLR在系统启动时启动,因此避免了这个问题,但这要归功于CLR和操作系统是同一拨开发者开发的。
如果你有一个Python进程需要运行很长时间,而且代码里包含“热点”可以被优化,那么使用JIT就很不错。
但是,CPython是个通用的实现。因此如果要用Python开发命令行程序,那么每次都要等待JIT调用CLI就特别慢了。
CPython试图满足大部分情况下的需求。有一个在CPython中实现JIT(https://www.slideshare.net/AnthonyShaw5/pyjion-a-jit-extension-system-for-cpython)的项目,不过这个项目已经停止很久了。
如果你想要享受JIT的好处,并且要处理的任务适合JIT,那就使用PyPy。
“因为它是动态类型语言”
“静态类型”语言要求必须在变量定义时指定其类型,例如C、C++、Java、C#和Go等。
而动态类型语言中尽管也有类型的概念,但变量的类型是动态的。
a=1
a="foo"
在这个例子中,Python用相同的名字和str类型定义了第二个变量,同时释放了第一个a的实例占用的内存。
静态类型语言的设计目的并不是折磨人,这样设计是因为CPU就是这样工作的。如果任何操作最终都要转化成简单的二进制操作,那就需要将对象和类型都转换成低级数据结构。
Python帮你做了这一切,只不过你从来没有关心过,也不需要关心。
不需要定义类型并不是Python慢的原因。Python的设计可以让你把一切都做成动态的。你可以在运行时替换对象的方法,可以在运行时给底层系统调用打补丁。几乎一切都有可能。
而这种设计使得Python的优化变得很困难。
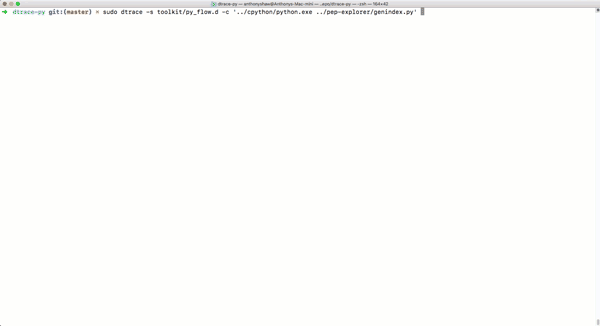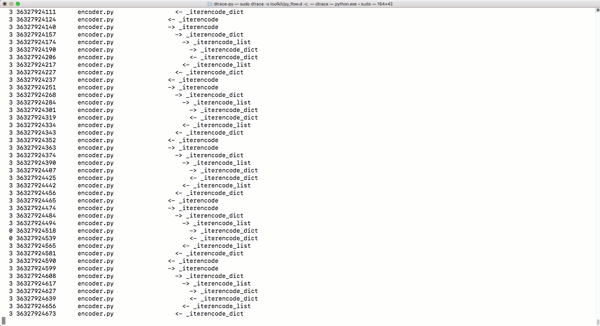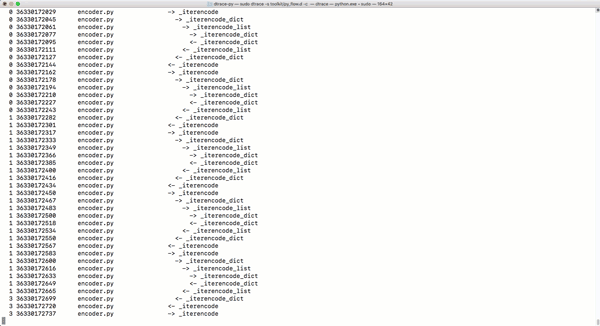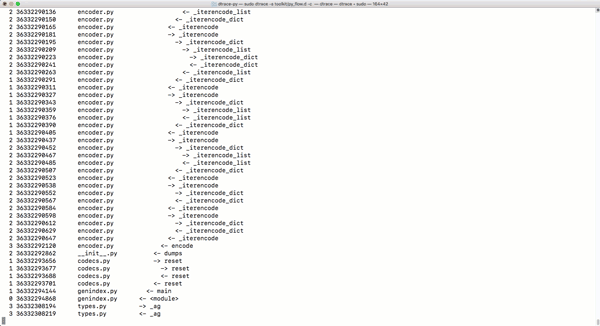
为了演示这个观点,我使用了一个Mac OS下的系统调用跟踪工具,叫做Dtrace。CPython的发布并不支持DTrace,因此需要重新编译CPython。演示中用的是Python 3.6.6:
wget https://github.com/python/cpython/archive/v3.6.6.zip
unzip v3.6.6.zip
cd v3.6.6
./configure --with-dtrace
make
现在Python.exe的代码中包含了Dtrace的跟踪代码。Paul
Ross有一篇非常好的关于DTrace的演讲(https://github.com/paulross/dtrace-py#the-lightning-talk)。可以从这里下载DTrace用于Python的文件(https://github.com/paulross/dtrace-py/tree/master/toolkit)用来测量函数调用、执行时间、CPU时间、系统调用以及各种函数等等。
sudo dtrace -s toolkit/<tracer>.d -c ‘../cpython/python.exe .py’
py_callflow跟踪器会显示应用程序的所有函数调用。
-
那么,Python的动态类型是否让Python更慢?
-
比较并转换类型的代价很大。每次读取、写入或引用变脸时都会检查类型
-
动态类型的语言很难优化。许多替代Python的语言很快的原因就是它们牺牲了便利性来交换性能。
-
例如Cython(http://cython.org/),它通过结合C的静态类型和Python的方式,使得代码中的类型已知,从而优化代码,能够获得84倍的性能提升(http://notes-on-cython.readthedocs.io/en/latest/std_dev.html)
结论
Python慢的主要原因是因为它的动态和多样性。它能用于解决各种问题,但多数问题都有优化得更好和更快的解决方案。
但Python应用也有许多优化措施,如使用异步、理解性能测试工具,以及使用多解释器等。
对于启动时间不重要,而代码可能享受到JIT的好处的应用,可以考虑使用PyPy。
对于代码中性能很重要的部分,如果变量大多是静态类型,可以考虑使用Cython。
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330