如何建立时间序列预测模型?
1. 背景
先来看两个例子,下面两幅图展示了百度在趋势预测方面的应用案例,一个是世界杯期间的比赛输赢预测,另一个是北京各旅游景区的游客人数预测。
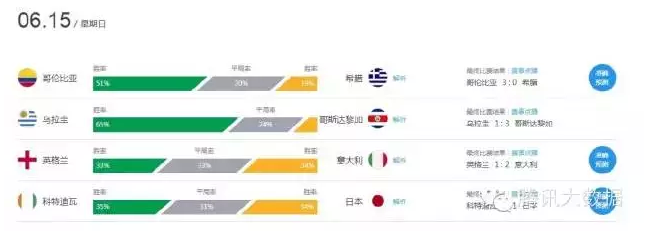

这两幅图代表了大数据环境下趋势预测的典型场景,即事件预测和时序预测,本文重点关注第二幅图中的场景,即与时间维度相关的时间序列预测。
2. 时间序列预测
时间序列预测即以时间数列所能反映的社会经济现象的发展过程和规律性,进行引伸外推,预测其发展趋势的方法,简单来说就是从已知事件测定未知事件。
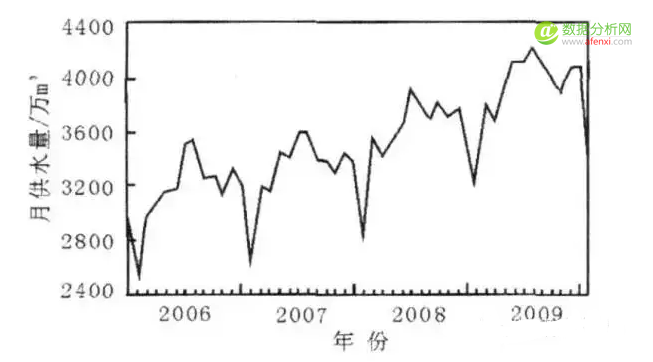
上图展示了时间序列的一般趋势,时间序列数据的趋势变动可分为以下四点:
趋势性:某个变量随着时间进展或自变量变化,呈现一种比较缓慢而长期的持续上升、下降、停留的同性质变动趋向,但变动幅度可能不等。周期性:某因素由于外部影响随着自然季节的交替出现高峰与低谷的规律。
随机性:个别为随机变动,整体呈统计规律。
综合性:实际变化情况一般是几种变动的叠加或组合。预测时一般设法过滤除去不规则变动,突出反映趋势性和周期性变动。
3. 方法综述
时间序列预测法分为传统的时间序列预测方法和机器学习方法。传统的时间序列方法指仅根据历史时间序列的趋势发展来预测未来时间序列的趋势发展的方法,此类方法通过建立适当的数学模型拟合历史时间趋势曲线,根据所建模型预测未来时间序列的趋势曲线,常见模型包括ARMA,VAR,TAR,ARCH等。传统时间序列方法所依赖的数据较简单,只需要历史时间序列趋势曲线便可构建模型,因此可适用于多种场景,模型较为通用。但是,传统时间序列预测法常面临滞后性问题,即预测值晚于真实值几个时间单位。
为提高预测的精度,机器学习算法被引入时序预测,此类方法根据具体的应用场景,选取可能影响预测值的features,将这些features引入模型,应用机器学习的分类/回归模型来进行预测。为提取features,机器学习方法需要多个维度的数据,预测精度较高,建立的模型较为复杂,但是模型往往不够通用,针对不同应用场景需要重新提取features,建立模型。现实预测中,机器学习方法往往结合传统时序预测法来运用。
4. ARIMA模型
ARIMA模型全称自回归积分滑动平均模型(Autoregressive Integrated Moving Average Model),是经典的时间序列预测方法,我们从ARIMA模型入手,进行了实时趋势预测的初步探索。

ARIMA模型公式分为自回归(AR)和移动平均(MA)两部分,p为自回归项数,q为移动平均项数,为保证时间序列的平稳性,往往需对时间序列做d阶差分。自回归方法基于假设当前时期的指标值依赖于过去时期的指标值,对过去时期的指标值进行加权平均得到当前的指标值;移动平均方法的思想是模拟指标值的随机性,指标值受白噪声序激励的影响。
5. 预测实验
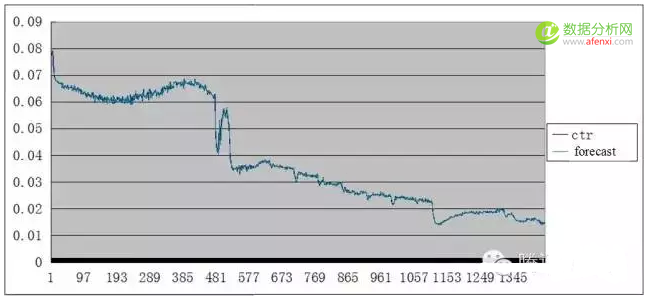
我们采用了某个业务的ctr数据,分别以分钟为单位和以小时为单位进行预测,希望可以准确预测下一时间单位(分钟,小时)的ctr。
分钟ctr预测(一天内的ctr变化情况):
局部细节展示:
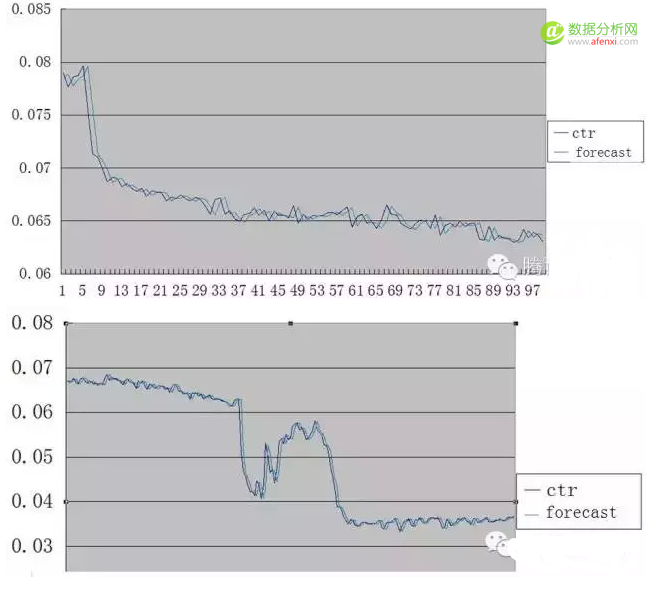
小时ctr(一周内的小时ctr变化情况):
6. 展望
大数据时代的时序预测得到越来越多的关注,能够准确预测趋势是时序预测的基础应用,其他场景如异常检测等也应用了时序预测方法,我们期待时序预测能够有更多的应用场景,比如通过精准预测,发现可能出现的突发事件以提高应对措施;加入空间维度,产生时空组合下的预测,提高预测的实际应用价值,比如通过预测滴滴打车某一地区的打车人数,引导用户和出租车,产生更好的资源利用;精准的金融预测,如预测理财通的买入买出数额,以帮助管理者合理指定策略等。这里初步探索的ARIMA模型是通用场景下的时序预测,在具体应用场景下,预测可以做的更精确。
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330