大道至简的数据分析方法论
学习数据分析师对大多数人而言是一件痛苦的事情,尤其看着厚厚的专业书籍、各种难以理解又缺乏解释说明的术语定义,会让这种痛苦加剧。但是有些书或文章能将复杂的理论用非常通俗、口语化的方式讲述出来,让读者不费劲,一下就能明白。这些内容实在是读书人的一种福音。说到底,互联网思维中的用户思维谈了这么久,教育、培训类内容的创作者们也应该好好改变一下,站在读者的角度说话了。
本文谈的是数据分析方法。根据笔者对众多企业的接触和了解,虽然现在大部分企业都对数据越来越重视,但目前仍有相当多的企业和从业者还没有摸清数据分析的门道,不知道自己的数据该怎么分析,希望得专业人员的到帮助。
笔者以前学习数据分析方法时也很痛苦,看了不少书,内容很多,但难以记全,更难以运用,后来加入永洪科技给众多企业做数据分析系统,通过大量的项目实践,才慢慢能谈得上入门。
好的方法论应该是易学易用的。现在,本文就努力尝试用最简单易懂的文笔,让初学数据分析的人看完就能理解并掌握数据分析方法中最核心、最常用的要点,至少能满足90%的日常需求。做到这一点,必须将博大精深的数据分析方法提炼成人们能记得住的3点,而不是30点,再浓缩到一篇文章的篇幅,而不是一本书的厚度。
1、数据分两种,维度和度量,分析就是维度和度量的组合
下面是一个最简单的消费者购物的数据例子。
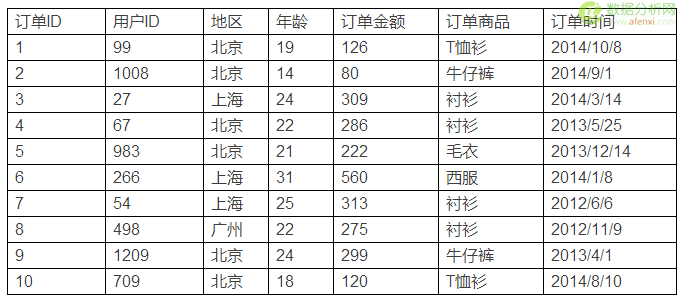
先不管这个数据表是存在excel里还是数据库里,只关注数据本身。表里涉及到的数据项(或者叫字段)有“订单ID”、“用户ID”、“地区”、“年龄”、“订单金额”、“订单商品”、“订单时间”。
这些数据项有什么差异呢?总体而言,数据分两种,一种叫维度,一种叫度量(或者叫指标)。上面这个例子里,“订单金额”是度量,其余数据项都是维度。
可以看出,度量是具体的计算用的量化数值,而维度是描述事物的各种属性信息。我们在做数据分析时,归根结底就是在不停的做各种维度和度量的组合,比如北京地区的订单金额总和,21到30岁用户的订单金额平均数;或者单独对维度和度量进行数学公式计算,比如所有的订单金额总和,用户数(用户ID的不重复计数)等等。
从数据类型上看,度量都是数值,但是数值不一定是度量,比如订单ID,虽然是数值,但是不是度量而是维度,而时间、文本类的数据都是维度。
有一点需要格外注意,维度和度量是可以转换的。比如要看“年龄”的平均数,这里的“年龄”就是度量,要看19岁用户的订单情况,这里的“年龄”就是维度。对于一个数据项而言,到底它是维度还是度量,是根据用户的需求而定的,很像量子效应,状态只有需求确定后才会随之确定。
另外,维度可以衍生出新的维度和度量,比如用“地区”维度衍生出一个大区维度,“北京”、“天津”都对应“华北大区”,或者用“年龄”维度衍生出一个年龄范围维度,20到29岁=“青年人”,30到39岁=“中年人”,40到49岁=“资深中年人”。再比如上述的平均年龄,就是用“年龄”维度衍生出一个度量。
度量也可以衍生出新的维度和度量,比如用“订单金额”度量衍生出一个金额范围维度,100元以下对应“小额订单”,500元以上对应“大额订单”等等。再比如用“收入”度量和“成本”度量相减,可以得到一个“利润”度量。
2、做判断用对比
下面提出一个问题:企业A今年收入8000万,是高还是低?大家看着这个问题,应该会感到无从判断,因为没有参照物,即没有对比。因此,拿到一个数据,要判断是好是坏是高是低,必须要进行对比。
首先,企业A可以跟自己比。如果前年收入2000万,去年收入4000万,那今年8000万算很好了。去年收入1个亿,今年8000万就是糟糕了。这叫纵向对比。
其次,企业A也可以跟其他人比。同行的几家竞争对手企业今年都收入几个亿,那企业A的8000万就不理想。这叫横向对比。
第三,企业A还可以对比不同的维度和度量。比如竞争对手都做全国市场,企业A只做山东市场。企业A在山东市场的收入比竞争对手在山东市场的收入高,那么就本地区而言,企业A做的更好,而放眼全国,企业A做的就有局限。比如如果竞争对手都做了十几年,而企业A刚做四五年,那企业A就算做的不错,但如果成立的时间相仿的竞争对手已经过亿了,那企业A就算做的不够好。这叫综合对比。
孩子考试考了95分,家长很高兴,因为知道满分是100分,有参照物。最近一次考试考了80分,家长会发火,因为过去的95分成了新参照物。后来一问,发现这次卷子出难了,孩子已经是班级第一了,就又转怒为喜,这里其他孩子就成了参(xi)照(sheng)物(pin)。
对比的参照物不同,得到的判断结论也就不同。为了避免结论片面、不客观,应该尽量多用综合对比。
3、找原因用细分
今年利润下降了,老板很生气,下令查找原因,缉拿“嫌犯”。原因怎么找呢?注意是找原因,不是找理由。很多人往往不知道如何查找原因,最后给出的都是理由。
先看一个示例的原因结论是什么——“因为四季度华南区域洗衣机的销量下降了,导致了今年利润的下降”。让我们分析一下这个原因有什么特点。
我们会发现,这个原因是由时间、区域、产品这三个维度和销量这一个度量组成的,于是我们可以知道,对于问题原因的查找定位,本质上就是在回答哪些维度下的哪些度量的下降或上升,导致了问题的发生。
这就是在做细分。
我们可以按维度细分,有多少维度,就可以有多少种细分的方向。比如看是去年所有月份都下降了,还是只有某几个月下降。如果是后者,那么就可以缩小查找的数据范围。聚焦到这几个月后,可以再看是哪些区域下降了,进一步细分。
入手的维度的先后顺序影响不大,问题原因涉及的维度也无法预知,因此可以从任意一个维度作为入口开始进行细分。
如果出问题的指标有相关的先导指标,则要想进一步挖掘问题原因,细分后还要看不同的度量,比如上述的原因结论示例是“因为四季度华南区域洗衣机的销量下降了,导致了今年利润的下降”,问题是“利润”而原因是“销量”,因为利润是通过别的度量计算衍生出来的。
细分无止境,细到什么地步才够呢?答案是,到可操作的区间才够。
比如就细分到“四季度利润下降,其它季度没有下降”,还是没有解决问题的办法,必须细到哪个时间段哪个区域哪条产品线,直到细到某一个最终责任人,才具有可操作性。需要注意的是,在真实情况中,问题往往不一定只有一个原因,而是多个原因综合起来形成的。
我司永洪科技主推的一站式大数据分析平台软件,为什么提供“缩放”和“笔刷”两种交互操作,就是为了满足“对比”和“细分”两种场景。
举一个例子,如下图,左图是各产品的收入毛利对比,右图是各品类利润趋势,现在用户想聚焦到“花茶”品类下的三种产品上,看看它们的利润如何。


有人可能会问,这个效果很类似筛选,为什么不在旁边放一些筛选器来实现呢?筛选器可以有,但现实情况中,当我们在一个图表上发现问题,不一定就能很容易地找到与其对应的筛选条件,尤其是散点图。因此,直接在图表上选择会非常方便高效。
再举一个例子,下图是产品利润趋势分析,用户发现从2009年7月开始,利润有连续4个月的下滑(如红框所示),用户想知道为什么。

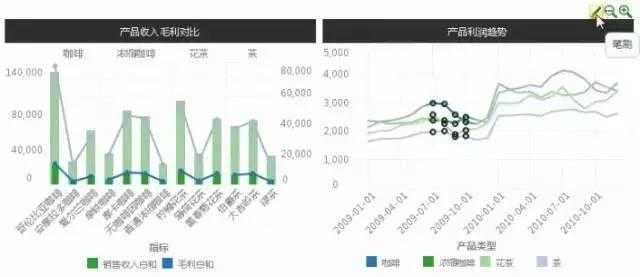
与“缩放”不同,“笔刷”方便用户将局部数据和整体数据进行对比。因为在上面这个例子中,单纯看哪些产品这4个月销售收入的绝对值低,并不能说明什么,有些产品本来卖的就少,一定要看哪些产品在这4个月相对表现不好。
先判断数据好不好,再分析原因是什么,数据分析的环节链条基本就算完整了。
什么时候去碰机器学习、数据挖掘这样高大上的东东。一句话,先把上述的数据发分析方法做到游刃有余,再搞那些高大上的。不要迷信复杂的算法,很多企业内部数据分析的大拿,往往都是深度理解业务,用的都是普通的计算方法,就能完成很精彩实用的分析过程。
机器学习,数据挖掘等什么时候会用到?简单而言,数据项多到人眼看不过来的时候会用到。如果总共就十来个数据项,每个拿出来单独出张图看一眼就看出端倪了,其实就不太需要用挖掘算法。如果总共几百个数据项,想看某一个数据项是受哪几个数据项影响最大,人眼看不过来,用挖掘算法就比较合适cda数据分析师培训
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330