让商家选址更有“数”百度大数据新势能爆发
在一个愈来愈讲究用数字说话的时代,大数据的概念如同这个盛夏般持续火热。曾在春运迁徙、高考作文预测表现优异的百度大数据如今又将应用领域拓展了。在近日召开的中国云计算大会上,百度展示了一套利用大数据能够帮助客户自动确定最优店铺选址的解决方案。该方案由百度研究院大数据实验室(BigDataLab,BaiduResearch)的数据科学家研发,能够精准发现明确的消费者,自动挖掘出未覆盖的需求分布,通过机器学习优化算法自动寻找最优的店铺位置。这让与会的不少企业家眼前一亮。
这一次,百度将服务对象瞄向商家,展开一场基于大数据驱动商业地产优化的试验。
精准营销前,大数据还能为商家带来什么?

维克托?迈尔?舍恩伯格在《大数据时代:生活、工作与思维的大变革》已经用“黑匣子”将大数据的意义概括地很形象。问题从一个端口进去,中间是一个集合成千上万数据的“黑匣子”,经过一番计算机工程后,答案从另一个端口出去。所以,思忖一下大数据对于这个信息化时代的价值便是——它是将充斥世界的海量数据采用数学算法予以“提纯”、钻取并随后或抽出规律,或处理成有用信息。
于是,在最急切寻求将技术党手中大数据变成切实真金白银的商家而言,追求人和商品高匹配的精准营销成了大数据的最普遍应用方式。成功案例当然也屡出不穷,沃尔玛曾用大数据分析“啤酒与尿布”的购买关联性,这个发现为商家带来了客观的利润,也成为同行纷纷效仿的经典商业案例。
但如果研究另一个美国品牌案例,人们可能也会发现另一个有意思的细节。众所周知,麦当劳的强大一点不仅仅在于它的汉堡,在每一次商业变现前,他们都在从事一个精准选址的过程,一个对数据深入挖掘、可能带来一桩意义远大于卖汉堡的的“房地产生意”。而每一次选址点似乎总在被它的对手KFC观摩与模仿。
这意味着事实上在商业链条的每个阶段,大数据都有应用的空间,并可以给企业带来科学、准确的决策依据。当然不仅仅停留在“当你买了一支电动牙刷,网站自动给你推送牙膏、牙线”的精准营销阶段。
百度如何实现让商铺选址更有“数”?
关于商铺选址,派人深入该地实地调查应该是最笨的土办法。而当将范围扩展至全国百余城市的重点商业圈时,个人和小团队仅凭商业直觉和有限的知识是远远不够的。这从而推动了利用商业地理数据进行商业选址及消费者地理细分的普及。但目前市面上已有基于数据驱动的选址方案同样也存在一定问题,一般是通过人群密度或者人群画像,来观察可能的消费者的分布。但是人群密度大的地方,并不代表潜在的消费者分布也多;同样,人群画像的属性也难以准确表达用户对具体位置服务的需求。
这些痛点也给百度大数据应用商业选址提供了发挥空间。
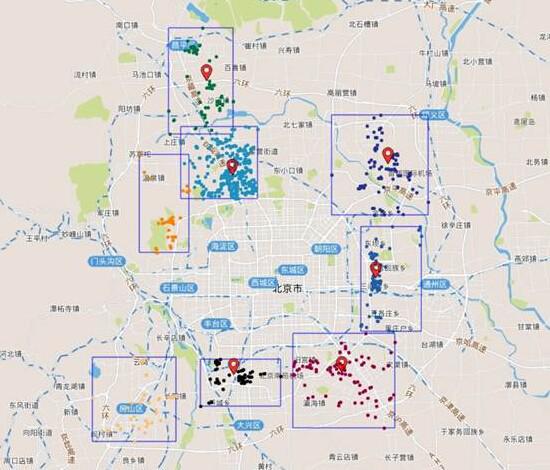
选址优化模型计算出的新网点候选位置,如图中气泡标示
百度让商铺选址更加有“数”:第一,基于用户需求。百度大数据实验室主要通过挖掘线上移动端数据检索数据量化,可将有直接服务需求的用户予以反馈。这避免了传统人群画像方法带来的误差。比如,在传统人群画像中,消费星巴克咖啡的大多为商务人士。但按照基于用户需求的方式,会发现中学生其实也构成星巴克消费的一大群体;第二,基于用户需求后的步步优化路径。当用户给出需求为覆盖的大概区域后,百度将结合机器学习优化算法,融合将不同类型的约束,如空间、时间、交通资源、周围网点等信息逐渐缩小范围,最终给客户提供优化后的网点候选位置。
当然,这一切让商家更有“数”的背后基于百度背后的技术实力。
作为全球最大的中文搜索引擎、中国最大的移动分发平台及视频播放平台,各维度数据成功构筑成百度的大数据仓库,在数据就是“石油”的今天,百度本身就是一个天然的巨大“金矿”。尤其在移动端,百度旗下14款app产品注册用户已达10亿,百度地图月活跃用户3亿,而这些都是用户搜索与位置数据的来源。当将搜索+LBS技术打通后,倘若北京某六环外城乡结合部频繁出现“火锅”关键词搜索后,海底捞、小肥羊们可以适时可以考虑开家分店了。
隐藏在强大产品矩阵背后的技术还有看不到的百度云端,包含深度学习算法、数据建模、大规模GPU并行化平台等技术。
未来,让数据继续在商家与用户充分流淌
商业地产+大数据,对于百度而言是一场探寻商业地产新模式的落地机会。而这个模式最完整和理想的状态早在去年百度与万科方面的合作已得到初显轮廓。
去年6月,万科与百度正式确立了战略合作伙伴关系,通过百度技术可以将线下消费者行为大数据收集、整合、分析进而转化为线上语言,从而为万科打通商业经营的整个环节。万科可以针对用户偏好进行选址、招商策略,也可以分析商场消费人群,掌握人流活动轨迹、消费习惯等,提供个性化定制服务和精准营销。
当这一切针对商家的服务链条打通后,其实也便实现了大数据可以提供个性化服务、实时反哺用户的价值。对,此处强调的是实时反哺。只有当数据在商家与用户间充分流淌,才可以打破二者之间的信息鸿沟,让双方的需求能够及时得到反馈,得到最优化的解决方案。
根据此前相关机构预测,2015年全世界的电子数据存储量会达到天文数字般的800万拍字节,这相当于十多万个美国国会图书馆的藏书量。对于急于寻求经济回报的商家而言,如此海量的数据其实是开启一个新商业时代的钥匙。而当这把钥匙旋转前,必须同时发挥其反哺服务商家和用户的价值。
在充分发挥大数据反哺意义前,李彦宏在2014年百度联盟大会上给大数据提出了最中肯的建议——要想找到有价值的数据,除了技术,最关键的还有domainknowledge(领域知识)、experience(经验)、以及跨领域的思考能力。
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330