如何区分理解数据科学家与机器学习工程师
导读:
-
真正让“数据科学”发挥出了强大威力的,是在人们意识到,数据不仅止于精算统计、商业智能和数据仓库的时候。将数据人和其他部门(软件开发、营销、管理、人力资源)隔离开来的筒仓被打破后,数据科学才真正彰显出了自己的独特之处。这门学科的中心思想,便是数据适用于万事万物。
-
在任何应用中,严格属于“机器学习”的部分其实都不算大:总需要有人去维护服务器设施,监控数据收集管道,确保计算资源充足什么的。
-
据我们所知,尚未出现过专门针对机器学习系统的严重攻击。但机器学习系统将成日渐成为诱人的攻击目标。机器学习会带来怎样的新型漏洞?有没有可能在训练系统用的数据中“下毒”,或者强迫系统在错误的时候接受重新训练?由于机器学习系统会自我训练,我们需要想到,全新漏洞类型的出现必不可免。
原文翻译:
十年来,我们一直在谈论数据科学和数据科学家。虽然在怎么才叫“数据科学家”的问题上始终存在着争议,但如今已有很多大学、网校和训练营都在提供数据科学课程:硕士学位、资格证书等等,凡是你能想到的都有。当我们只有统计学的时候,这个世界显得更加简单,但简单并不总是科学的。而除了世界对数据科学家的需求程度以外,数据科学课程如此多种多样,其实也说明不了什么。
随着数据科学领域的发展,出现了很多难以区分的专业。公司用“数据科学家”和“数据科学团队”来描述各种各样的角色,包括:
进行专门分析与报告(包括商业智能和商业分析)的人
负责统计分析和建模(很多情况下会涉及到正式的实验和测试)的人
越来越多地使用笔记本电脑来开发原型的机器学习建模师
这当中并没有提及DJ·帕提尔(DJ Patil)和杰夫·哈默巴赫(Jeff Hammerbacher)在发明“数据科学家”这个称谓时所想到的人——依据数据打造产品的人。
他们所想的这种数据科学家倒是跟机器学习建模师最为接近,只不过他们的工作是打造产品——一切以产品为中心,而不是秉持着研究人员的身份。他们的工作通常涉及到数据产品的很大一部分。无论具体的职务为何,数据科学家的角色绝非单纯的统计学家。他们往往拥有理科博士学位,在处理大量数据方面拥有丰富的实践经验。他们基本上都是优秀的程序员,绝非只是精通R或其他某种统计软件包。他们懂得数据获取、数据清洗、原型开发、原型投产、产品设计、搭建和管理数据设施等等。在实践中,他们是典型的硅谷“独角兽”:稀有,非常难招到。
重点并不是我们设立了边界明确的专业。在一个欣欣向荣的领域里,总会存在着十分广袤的灰色地带。真正让“数据科学”发挥出了强大威力的,是在人们意识到,数据不仅止于精算统计、商业智能和数据仓库的时候。将数据人和其他部门(软件开发、营销、管理、人力资源)隔离开来的筒仓被打破后,数据科学才真正彰显出了自己的独特之处。这门学科的中心思想,便是数据适用于万事万物。数据科学家的使命就是收集和利用所有的数据。所有部门都会牵涉其中。
当我们找不着独角兽的时候,就把他们的能力分解成不同的专业,而数据科学在开始盛行起来后,也遭遇了这一出。突然之间,我们就有了数据工程师。数据工程师并非以数学家或统计学家为主要身份,但他们都懂数学和统计学;他们的主要身份也不是软件开发人员,但他们也懂软件。数据工程师负责数据堆栈的操作和维护。他们能让笔记本电脑上运行的原型在生产中可靠运行。他们负责弄清楚如何搭建和维护Hadoop或Spark集群,还有整个生态系统中的很多其他工具:数据库(比如Hbase、Cassandra),流数据平台(Kafka、SparkStreaming、Apache
Flink),还有更多的活动部件[princeray1] 。他们知道如何在云端操作,充分利用Amazon Web
Services、MicrosoftAzure和Google Compute Engine的性能。
如今,我们已经进入了“数据科学”的第二个十年,机器学习已大行其道,于是“数据工程师”的定义也变得更加明确。2015年,谷歌发表了一篇后来得到广泛引用的论文,里面凸显了一项事实:除了分析模型以外,现实世界中的机器学习系统还有很多其他构成要素。企业开始注重打造数据产品,并将他们一直以来所采用的技术运用到生产中。在任何应用中,严格属于“机器学习”的部分其实都不算大:总需要有人去维护服务器设施,监控数据收集管道,确保计算资源充足什么的。于是,开始有越来越多的企业建立机器学习工程师队伍。这其实算不上一个新的专业领域,随着机器学习(尤其是深度学习)在数据科学圈子里变得炙手可热,数据工程师必然会有进一步的发展空间。但是机器学习工程师和数据工程师之间的区别到底是什么呢?
从某种程度上来说,机器学习工程师所做的正是一直以来软件工程师(和优秀数据工程师)的工作。以下是机器学习工程师的几个重要特征:
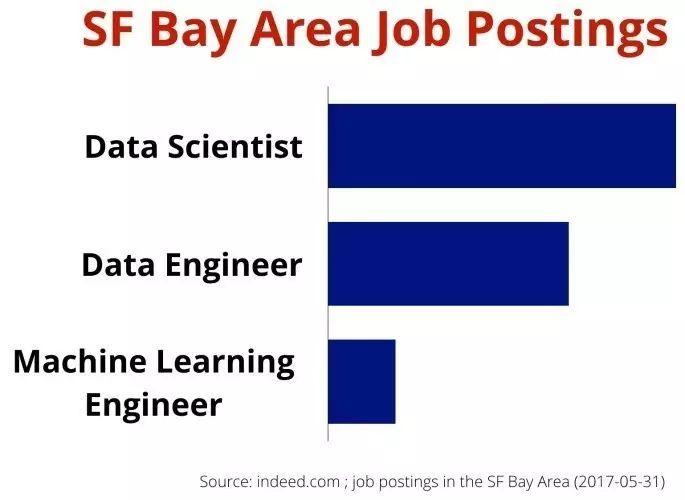
·他们拥有比常见的数据科学家更厉害的软件工程技能。机器学习工程师能够和维护产品系统的工程师协同工作(有时就在同一个团队)。他们懂得软件开发方法、敏捷实践和现代软件开发人员使用的全套工具,从Eclipse和IntelliJ这样的集成开发环境,到持续部署流水线的各个环节,他们样样精通。
由于他们的焦点放在能让数据产品顺利投产上,他们会进行全面思考,甚至将日志记录、AB测试设施等环节也一并考虑进来。
他们对在生产活动中监控数据产品所特有的问题有着最新的认识。监控应用程序的办法有很多,但机器学习让这个任务的要求上升到了一个新的层面。数据管道和模型都有可能过时,需要重新训练,也可能遭到对手采用并不适用于传统网络应用的方式大肆攻击。机器学习系统会不会因为提供输入的数据管道被黑而失真?会,所以机器学习工程师必须知道可如何探测到这些攻击。
深度学习的兴起催生出一种与其相关但更加专门化的岗位——深度学习工程师。我们还看到了“数据运维团队”的出现,但在如何定义这类团队的问题上,(截至目前)人们似乎仍未达成共识。
机器学习工程师的工作涉及到软件架构和设计。他们懂得AB测试这样的实务操作,但更重要的是,他们不只是“懂得”AB测试——他们还知道如何进行生产系统的AB测试。他们也懂得日志、安全这一类的问题,而且知道如何让日志数据在数据工程师那里派上用场。所有这一切没有什么新鲜东西:这只是岗位的深化,而不是改变。
机器学习和“数据科学”又有什么不同?显然,数据科学的涵盖面更广,但深度学习的工作方式却存在着一些格外不同的地方。人们总是容易把数据科学家想象成挖掘数据的人——研究不同的方法和模型,从中找出一个切实可行的。图基(Tukey)的探索性数据分析等经典方法为很多数据科学家迄今为止的工作定下了基调:挖掘分析大量数据,找到其中隐藏的价值。
深度学习显著改变了这种模式。你不再亲自处理数据。你知道你想要什么样的结果,但你让软件去发现它。你想要打造一台能够打败围棋冠军、正确标记照片或者实现语言翻译的机器。在机器学习的范畴中,这些目标不会通过细致的挖掘来达成。在很多情况下,要挖掘的数据量实在太大,维度也太多。(围棋的维度有多少?语言的维度呢?)机器学习能做到的,就是自己建立模型——自己进行数据挖掘和调整。
于是,数据科学家并没有做多少挖掘的工作。他们的目标并非找到数据的意义。他们认为价值本来就在那里。他们真正的目标是打造能够分析数据和生成结果的机器——创建出一张可以被调教到能使用输入数据生成可靠结果的神经网络。统计学不再那么重要。事实上,机器学习的大神器是“大众化”,让机器学习系统可由主题专家而不是人工智能博士打造。我们想让围棋选手打造出下一代的AlphaGo,而不是研究人员。我们想让说西班牙语的人打造出能把其他语言自动翻译成西班牙语的引擎。
这种变化也对机器学习工程师产生了相应的影响。在机器学习的范畴里,模型不是静态的。随着时间的推移,模型可能会逐渐失效。必须有人来监控系统,在必要时对其重新训练。这项工作对于当初打造该系统的开发人员来说,可能很是无趣,但当中的技术性却很强。而且,这也需要对监控工具有充分了解,因为这些监控工具在设计时并不会考虑到数据应用的问题。
所有的软件开发人员和IT从业人员都应该对安全性这个问题有所了解。据我们所知,尚未出现过专门针对机器学习系统的严重攻击。但机器学习系统将成日渐成为诱人的攻击目标。机器学习会带来怎样的新型漏洞?有没有可能在训练系统用的数据中“下毒”,或者强迫系统在错误的时候接受重新训练?由于机器学习系统会自我训练,我们需要想到,全新漏洞类型的出现必不可免。
随着工具的改进,我们将看到更多的数据科学家有能力转型到生产系统领域。云环境和软件即服务(SaaS)让数据科学家能够更简单地部署数据科学原型,将其投入生产,而诸如Clipper、Ground(美国加州大学伯克利分校RISE实验室的新项目)这样的开源工具也正开始涌现。但我们仍将需要数据工程师和机器学习工程师——那些通晓数据科学和机器学习知识,知道如何在生产中部署和运行系统,能够为机器学习产品提供支持的工程师。他们才是最终极的“人性因素”。
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330