数据科学家 / 统计学家应该养成哪些好习惯
做过一点统计模型,做过一点数据分析,现在工作名字叫数据科学家,厚着脸皮抛砖引玉,聊聊数据分析中需要养成的良好习惯。
1. 了解数据分析的目的/需求
做数据分析的新人可能都遇到过,辛辛苦苦花了几个小时做出来的结果,跟客户 / 合作伙伴 / PM / 老板要的不是一个东西,运气好的话回去修补一下,花个半小时之类的,运气不好的话直接推倒重来,搞不好又得晚上加班了。
比如说下午六点,正准备收拾东西回家,PM
跟你说想看知乎用户的活跃度,跟数据分析师提出需求说,我们来看看大家使用时长吧。那么问题来了,是看平均呢还是看中位数?是看某一种客户端比如移动端吗,或者是想每种客户端都分开来看?要根据用户的注册时间来做下划分吗?是否想看具体某个城市的?
甚至再退后一步,PM 想看这个干什么?仅仅是好奇,还是现在有个很重要的决定需要以此为基础?数据分析师需要以此来决定这件事情的优先级,是可以推回去的呢?还是说需要立马动手做,下班之前就需要给结果的。
二十岁的人生,三十年的工作经验,都是加班闹的。

2. 用常识来验证结果
虽然说数据说话,但是前提是数据来源、分析过程、解读等都是正确的。如何保证结果的正确性,最基本的一点就是不同方面来快速验证一下数量级。
比如说 PM 想看知乎用户使用 Live 的数量,发现迄今为止有 50 万 iPhone 用户点击了 Live 的页面,2
万安卓用户点击了 Live 的页面。同时还知道知乎有五百万 iPhone 日活,而安卓的日活是三千万,由此可见 iPhone
用户就是舍得花钱啊,同时安卓用户那里还有很大的机会。然后简单比较一下可以发现,二者的参与率差了 150
倍,常识判断这差得有点太大了,难以解释。再仔细研究一下数据来源发现,原来安卓客户端的数据记录是取样 1% 的,所以直接看只有 2
万安卓用户点击,但实际上应该在两百万左右,这样一来 iPhone 和安卓的差别就比较合理了。
时刻谨记常识

3. 时刻注意数据分析的结果是否具有误导性
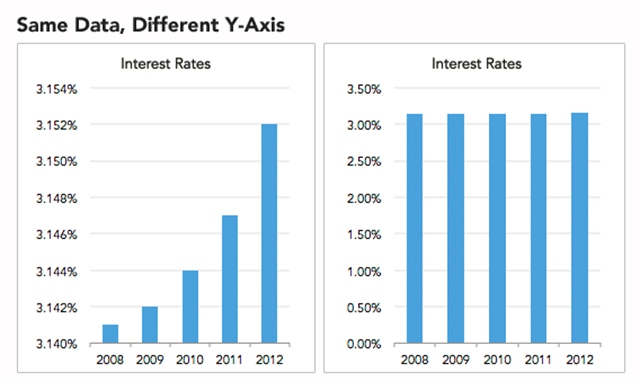
经常说的一句话叫“数据会说谎”。然后数据自身是不会说谎的,而是取决于如何做数据分析、如何展示结果。有时候是数据分析无意中引入了误导性元素,比如说不合理的坐标轴,有时候是刻意引入某些误导性元素,以达到特别的目的,这些都是应该尽量避免的。
比如说下图同样的增幅,因为用了不同的 y 轴,左右看起来就完全不一样了。如果听众没有仔细看坐标轴而仅仅看图形的话,妥妥的就被忽悠了。
此外还有一些数据分析中常见的错误,可以参考下面文章:
数据分析中会常犯哪些错误,如何解决?
4. 想想你的听众是谁
数据很多时候不仅仅是一个人埋头苦干,还需要跟人交流,比如说跟合作伙伴的沟通,跟老板的沟通,跟其他组员的沟通,跟不同部门的人沟通。针对不同的听众,相应的需要强调不同方面。
比如说跟合作伙伴沟通的时候,可能他们知道你做这个的目的是什么,可能会对结果更感兴趣,以及由数据提供了什么建议或者决定。至于具体数据来源或者分析方法之类对他们来说不是那么重要,大多数时候只要确保数据分析师知道自己在做什么就可以了。
跟老板沟通结果的时候,大部分时候可能他们知道你做的大致方向,对分析思路的方法基本一点就通,细节方面可能无法面面俱到。
而跟不同部门的人沟通的时候,分享数据分析的结果之前,最好还能讲讲这件事情的目的,一些背景,大方向是什么诸如此类。

5. 动手之前先看看这件事情是不是已经有人做过了
这点在大一点的公司尤其明显,PM 或者老板提出一个需求,或者数据分析师自己对某一个问题感兴趣,然后想也没想,就 SQL 写得飞快跑了起来。很快一天过去了,产出了一大堆数据和报表,被自己的高效感动了,收拾书包回家。
晚上打开电脑,突然不知道哪根经搭错了,想白天做的这个事情会不会已经有人做过了呢?于是内网搜了一下,豁然发现某个角落里有一堆早就做好的 pipeline,数据、报表一应俱全,90% 想要的结果都在里面了,真是不知道该哭还是想笑。
数据分析很多时候是不需要重新造轮子的。

6. 数据大小很重要又不重要
几年前,有个大数据的笑话,Big data is like teenage sex: everyone talks about it,
nobody really knows how to do it, everyone thinks everyone else is
doing it, so everyone claims they are doing it. 看不懂的请 google translate.
几年过去了,teenage 应该也长大成人不再是 teenage sex 了,很多时候大家是真的在做大数据了。虽然 size matters,但是数据分析师更应该关注数据能提供什么价值。
本来想放个 size matters 的图,然后 google 了一下之后,出来的都是办公室不宜的,所以你们自己脑补吧。
7. So what?
描述性的数据据分析很重要,是了解用户,了解产品,感受大方向的基础。比如针对知乎活跃用户做个画像,发现 55% 男性,40%
女性(别问我剩下 5% 怎么回事),70% 年薪百万,80% 985/211,90% 健身,100%
都是活跃用户(废话),如此种种。这么一大堆图表、信息堆起来之后,需要仔细想想这到底说明了什么问题?对改进产品有什么启示,比如说开个健身爆照专栏轮带逛?如果仅仅是停留在描述性数据分析阶段的话,那么就无法发挥数据的最大作用,从数据的角度引导产品的改进。
ps. 引导产品改进可以是多个方面的,数据引导仅仅是其中的一部分。
8. 保持好奇心
数据分析不是一个新的学科,但是工具、内容、应用方向等一直在不断改变,所以保持好奇心,持续学习进步,探索新领域对长期发展是最重要的一点,(个人认为)没有之一。
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330