一篇文章解决你所有关于数据分析的问题
1. 数据分析多层模型介绍
这个金字塔图像是数据分析的多层模型,从下往上一共有六层:
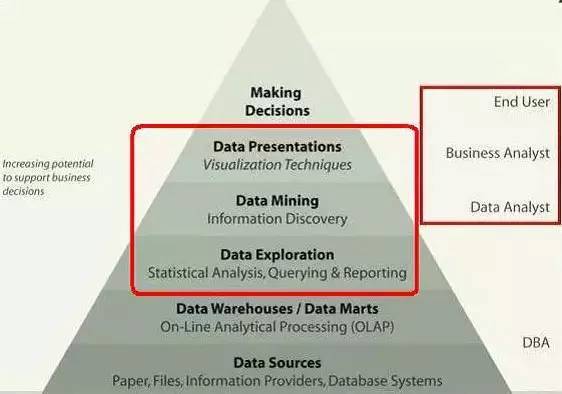
底下第一层称为Data Sources 元数据层。
比如说在生产线上,在生产的数据库里面,各种各样的数据,可能是银行的业务数据,也可能是电信运营商在交换机里面采集下来的数据等等,然后这些生产的数据通过ETL,是英文
Extract-Transform-Load
的缩写,用来描述将数据从来源端经过抽取(extract)、转换(transform)、加载(load)至目的端的过程,通过这个过程,我们可以把需要的数据放到数据仓库里面,那这个数据仓库就是多层模型中的第二层。
数据仓库主要是给我们需要存放的数据提供一个物理基础,我们对数据进行分析,原材料都放在这个数据仓库里面,这几年以来,除了数据仓库这个概念,还兴起了数据集市这个概念,数据集市其实就是部门级的数据仓库,规模比较小一点的数据仓库。
再上面一层是Data Exploration,这层主要做统计分析的事情,比如我们算均值、标准差、方差、排序、求最小\大值、中位数、众数等等,这些统计学比较常用的指标,另外还有些SQL查询语句,总的来说主要是做一些目标比较明确,计算方法比较清楚的事情。
第四层是Data Mining数据挖掘层,数据挖掘与数据分析(统计分析)有什么区别呢,数据分析往往是统计量和算法比较清楚,数据挖掘往往是目标不是很清楚,在实现目标的过程中采用什么方法不能确定,所以数据挖掘比数据分析难度要高很多。
第五层是数据展现层,把数据分析和数据挖掘得出来的结果通过数据展现层的图表、报表把他展现出来,也可以称为数据可视化。
最后把这些图表、报表交给决策者,以这个为基础做一些决策。
2. 数据分析工具简介
常用的数据分析工具,包括一些厂商的数据库产品,包括IBM的DB2、甲骨文的Oracle数据库。这些厂商的数据库本身带有一些统计分析的包,里面有些标准的功能可以做数据分析工作,但用这些自带的数据分析工具功能相对不够专业。主要反映在缺乏标准的统计函数,比如做一个线性回归模型,需要写一大堆SQL语句,甚至要写一个plsql程序才能完成。但是在专业的统计软件只需要写一个简单的函数就可以完成。

目前最主流的统计软件有R、SAS、SPSS,R是一个免费的开源软件。
SAS大概是历史最悠久的统计软件,是一个商业软件,在60年代就诞生,在70年代以后逐渐商业化,发展到现在SAS已经成为国际标准。
SPSS也是一个历史悠久的统计软件,SPSS一开始是一个仿真软件,后来演变成一个统计软件,目前已经发展成为一个数据挖掘软件,目前被IBM收购,变成IBM旗下的一个产品,在社会学研究院领域有很多的应用。
其他的还有一些软件,比如说水晶报表(Crystal Reports),在做BI和报表非常擅长,另外如UCINET也是在社会学比较常用的软件,它可以画群体的网络图,社交关系图非常擅长。
3. 常用统计方法
使用统计方法,有目的地对收集到的数据进行分析处理,并且解读分析结果:

常用算法

4. 数据挖掘
数据挖掘是以查找隐藏在数据中的信息为目标的技术,是应用算法从大型数据库中提取知识的过程,这些算法确定信息项之间的隐性关联,并且向用户显示这些关联。
数据挖掘思想来源:假设检验,模式识别,人工智能,机器学习
常见数据挖掘任务:关联分析,聚类分析,孤立点分析等等
例:啤酒与尿布的故事
5. 展现层:报表与图形
展现层在数据分析中是一个很重要的组成部分,在大家的心目中数据分析软件只是读数据和算数据,结果算出来就OK了。但其实结果算出来以后对于数据分析还远没有结束,还需要把结果展现出来,有些时候可能结果的展现比计算花的时间还要多。
下图是一个比较老土的报表。

如果那这种报表给老板看,那体验效果肯定很差,其实人的特点对数字的感觉不敏感,如果你那一大堆数字组成的报表给老板看,老板肯定不是很高兴。
人对图形会比较敏感,所以在统计学里面通常有比较标准的图,如饼图、柱形图(垂直和水平)、虚线图、水泡图、鱼骨图、箱线图等等。
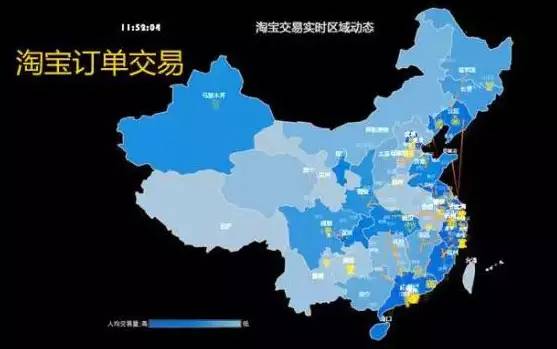
下面是一张在地图上展现数据的展现形式
下图是关于使用安卓手机的数据展现

根据信息图显示,Android先生的头发有47%的可能是黑色的,戴眼镜的几率为37%,有36%的可能是北美人,30%的可能脸上长雀斑。71%的时
间会穿T恤,下身穿牛仔裤的时间占了62%。工作只占了38%,玩游戏却占了62%,平均每个月会用掉582MB的数据流量。这种图称为信息图,在数据分析这个行业里面,是数据展现工作的主要组成部分。
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330