SPSS重复测量的多因素方差分析
一、概述
重复测量数据的方差分析是对同一因变量进行重复测量的一种试验设计技术。在给予一种或多种处理后,分别在不同的时间点上通过重复测量同一个受试对象获得的指标的观察值,或者是通过重复测量同一个个体的不同部位(或组织)获得的指标的观察值。重复测量数据在科学研究中十分常见。
分析前要对重复测量数据之间是否存在相关性进行球形检验。如果该检验结果为 P﹥0.05,则说明重复测量数据之间不存在相关性,测量数据符合
Huynh-Feldt 条件,可以用单因素方差分析的方法来处理;如果检验结果
P﹤0.05,则说明重复测量数据之间是存在相关性的,所以不能用单因素方差分析的方法处理数据。在科研实际中的重复测量设计资料后者较多,应该使用重复测量设计的方差分析模型。
球形条件不满足时常有两种方法可供选择:
(1)采用 MANOVA(多变量方差分析方法);
(2)对重复测量 ANOVA 检验结果中与时间有关的 F 值的自由度进行调整。
二、实例解析
新生儿胎粪吸入综合征(MAS)是由于胎儿在子宫内或着生产时吸入了混有胎粪的羊水,从而导致呼吸道和肺泡发生机械性阻塞,并伴有肺泡表面活性物质失活,而且肺组织也会发生化学性炎症,胎儿出生后出现的以呼吸窘迫为主,同时伴有其他脏器受损现象的一组综合征
。血管内皮生长因子 (vascular endothelial growth factor,VEGF)
是一种有丝分裂原,它特异作用于血管内皮细胞时,能够调节血管内皮细胞的增殖和迁移,从而使血管通透性增加。而本实验旨在通过观察分析给予外源性肺表面活性物质治疗前后胎粪吸入综合征患儿血清中
VEGF 的含量变化,评价药物治疗的效果。
将收治的诊断胎粪吸入综合症的新生儿共 42
名。将患儿随机分为肺表面活性物质治疗组(PS 组)和常规治疗组(对照组),每组各 21 例。PS
组和对照组两组所有患儿均给予除用药外的其他相应的对症治疗。PS 组患儿给予牛肺表面活性剂 PS 70 mg/kg 治疗。采集 PS
组及对照组患儿 0 小时,治疗后 24 小时和 72 小时静脉血 2 ml,离心并提取上清液后保存备用并记录血清中 VEGF 的含量变化情况。
结果如下:
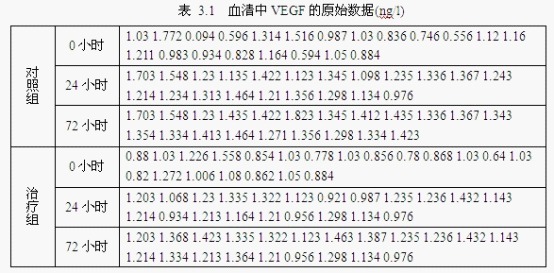
3、统计分析
建立数据文件
变量视图:

数据视图:
菜单选择:
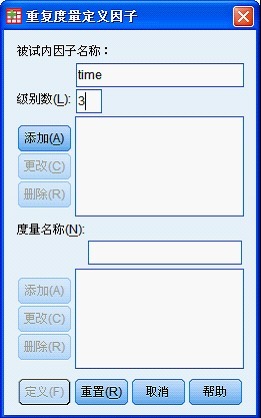
首先进入如下对话框,在「被试内因子名称」中输入「time」,「级别数」输入 3,因为每个患者重复测量了 3 次。
后点击「添加」按钮。此时下方「定义」按钮变为可用,点击进入下列对话框:
将「group」选入「因子列表」框,t1-t3 分别选入「全体内变量(time)」框内,如下图所示:
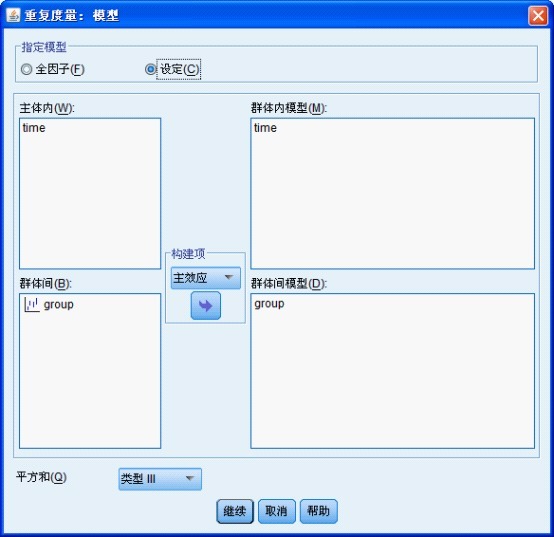
点击右上角「模型」按钮,进入以下对话框,选择「设定」,将「time」选入「全体内模型」框,「group」选入「群体间模型」框,「构建项」选择「主效应」。下方的平方和选「类型 III」,这是对于平衡数据。如果两组样本量不等,则选择「类型 IV」。
点击「继续」返回,点击「绘制」按钮。进入下面对话框:将「time」选入「水平轴」,group 选入「单图」,然后点击「添加」按钮,下面框中会显示「time*group」。
点击「继续」返回,点击「两两比较」按钮,将 group 选入右侧「两两比较检验」框中,选中复选框「LSD」。
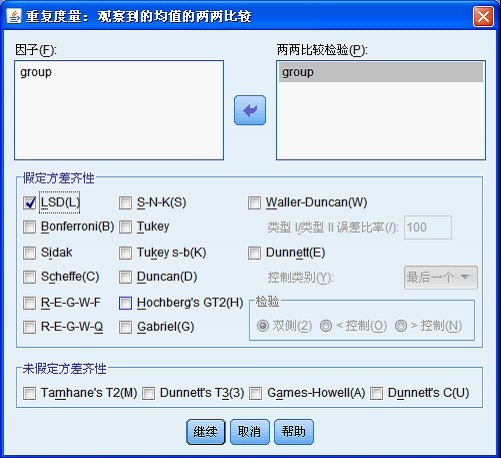
点击「继续」返回,点击「选项」按钮,进入下面对话框:将 time 选入「显示均值框」,选中「比较主效应」复选框,选中下方「描述统计」复选框。

下方显著性水平设为 0.05。点击「继续」返回,点击「确定」输出结果。
4、结果解读:
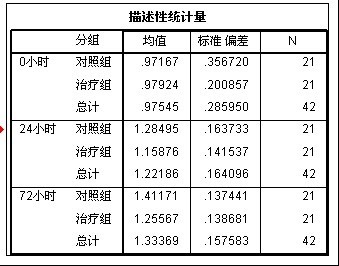
这是一个关于各个时间点的两组数据描述性统计。

这是球形检验结果,p = 0.001<0.05,所以不满足球形分布假设,需要进行多变量方差分析或者自由度调整,SPSS 接下来会给出以上两种结果。
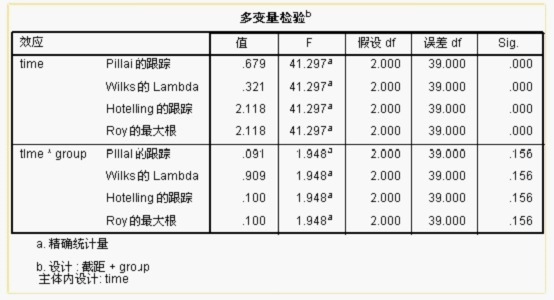
这是进行多变量方差分析的结果,给出了 4 种统计量,它们的检验结果一致,time 的
P<0.001,说明各个时间点的数据的差异有统计学意义,time*group 的
P>0.05,说明时间和分组无交互作用,说明时间因素(即 0 小时、24 小时、72
小时)的作用不随分组(即治疗组和对照组)的不同而不同。

所谓「主体内」,即是重复测量的各个时间点。上表是用各个时间点进行分组的方差分析表,给出 4 种统计量,第一种为满足球星假设的情况,后三种对自由度进行了校正,本题目中不满足球形分布假设,只能看下面的三种检验方法。结果解释同上一个表。
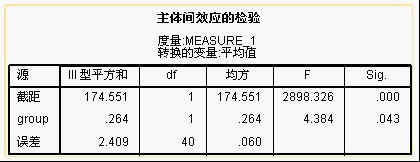
这是对分组的方差分析,对变量进行如下的变换:y =(t1+t2+t3)/sqrt(3)。P = 0.043<0.05,说明有治疗组与对照组之间有统计学差异。

这个图可以直观地看出测量指标随时间的变化趋势。治疗组与对照组两组资料随时间变化的趋势大致相同,治疗组血清中 VEGF 的含量较对照组呈下降趋势,说明治疗组的效果优于对照组。
我们还可以给出在每个时间点上两个分组之间的比较,需要用到多变量方差分析:操作步骤如下:跟之前操作类似,不赘述,看图就行。

结果输出
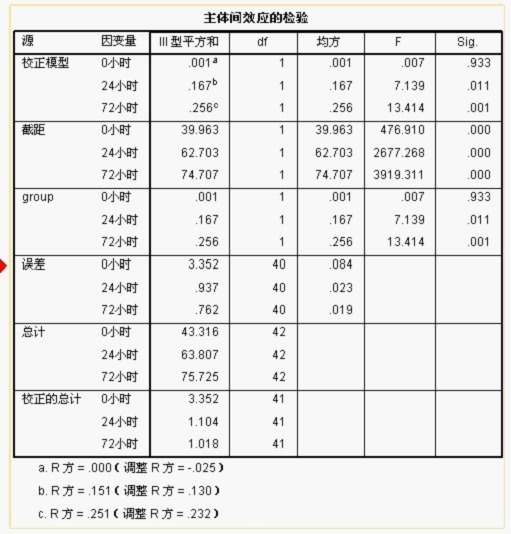
每个时间点上两组之间的比较(即分别比较 0 小时、24 小时及 72 小时时对照组和治疗组的数据)结果显示 0 小时时 P﹥0.05,治疗组和对照组之间没有统计学差异,而 24 小时和 72 小时时 P﹤0.05,治疗组和对照组两组间有显著的统计学差异。
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330