如何用Python高效地学习数据结构
今天的每日一答,我们来看看如何高效地学习一门语言的数据结构,今天我们先看Python篇。
所谓数据结构,是指相互之间存在一种或多种特定关系的数据类型的集合。
Python在数据分析领域中,最常用的数据结构,莫过于DataFrame了,今天我们就介绍如何高效地学习DataFrame这种数据结构。
要学习好一种东西,最好给自己找一个目标,达到了这个目标,我们就是学好了。一般,我在学习一门新的语言的数据结构的时候,一般要求自己达到以下五个要求:
第一个问题:概念,这种数据结构的概念是什么呢?
第二个问题:定义,如何定义这种数据结构呢?
第三个问题:限制,使用这种数据结构,有什么限制呢?
第四个问题:访问,访问这种数据结构内的数据的方式是什么呢?
第五个问题:修改,如何对这种数据结构进行增加元素、删除元素以及修改元素呢?
好,今天我们就来回答一下以上五个问题。
第一个问题:概念,这种数据结构的概念是什么呢?
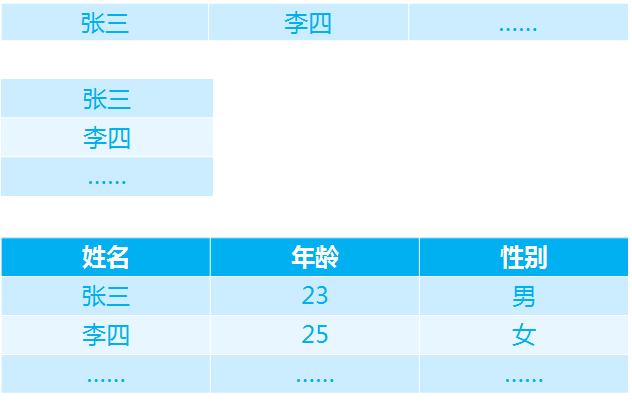
数据框是用于存储多行和多列的数据集合,下面我们使用一张图片,形象地讲解它的内部结构:

OK,这个就是数据框的概念了。
第二个问题:定义,如何定义这种数据结构呢?
DataFrame函数语法
DataFrame(columnsMap)
代码举例:
>>>df=DataFrame({
'age':Series([21,22,23]),
'name':Series(['KEN','John','JIMI'])
});
>>>df
age name
0 21 KEN
1 22 John
2 23 JIMI
OK,这个就是定义数据框DataFrame的方法了。
第三个问题:限制,使用这种数据结构,有什么限制呢?
一般而言,限制是对于这种数据结构是否只能存储某种数据类型,在Python的数据框中,允许存放多种数据类型,基本上对于默认的数据类型,没有任何限制。
第四个问题:访问,访问这种数据结构内的数据的方式是什么呢?
|
访问位置
|
方法
|
备注
|
|
访问列
|
变量名[列名]
|
访问对应列
|
|
访问行
|
变量名[n:m]
|
访问n行到m-1行的数据
|
|
访问行和列
|
变量名.iloc[n1:n2,m1:m2]
|
访问n1到n2-1列,m1到m2-1行的数据
|
|
访问位置
|
变量名.at[n, 列名]
|
访问n行,列位置
|
代码举例
>>>df['age']
0 21
1 22
2 23
Name:age,dtype:int64
>>>df[1:2]
age name
1 22 John
>>>df.iloc[0:1,0:2]
agename
0 21 KEN
>>>df.at[0,'name']
'KEN'
>>>df[['age','name']]
agename
021KEN
122John
223JIMI
>>>
第五个问题:修改,如何对这种数据结构进行增加元素、删除元素以及修改元素呢?
这个问题,我并没有在课程中跟大家讨论过,主要是为了避免大家觉得学习起来很难。
也因此,这篇博文到了这里才是真正的干货,之前的那些都是课程中出现过的内容了,哈哈,
修改包括:
1、修改列名,行索引
2、增加/删除/修改行
3、增加/删除/修改列
好,下面我们上代码:
frompandasimportSeries;
frompandasimportDataFrame;
df=DataFrame({
'age':Series([21,22,23]),
'name':Series(['KEN','John','JIMI'])
});
#1.1、修改列名
>>>df.columns
Index(['age','name'],dtype='object')
>>>df.columns=['age2','name2']
>>>df
age2name2
021KEN
122John
223JIMI
#1.2、修改行名
>>>df.index
Int64Index([0,1,2],dtype='int64')
>>>df.index=range(1,4)
>>>df.index
Int64Index([1,2,3],dtype='int64')
#2.1、删除行
>>>df.drop(1)
age2name2
222John
323JIMI
>>>df
age2name2
121KEN
222John
323JIMI
#注意,删除后的DataFrame需要一个变量来接收,并不会直接修改原来的DataFrame.
>>>newdf=df.drop(1);
>>>newdf
age2name2
222John
323JIMI
#2.2、删除列
>>>delnewdf['age2']
>>>newdf
name2
2John
3JIMI
#3.1、增加行
>>>df.loc[len(df)+1]=[24,"KENKEN"];
>>>df
age2name2
121KEN
222John
323JIMI
424KENKEN
#3.2、增加列
>>>df['newColumn']=[2,4,6,8];
>>>df
age2name2newColumn
121KEN2
222John4
323JIMI6
424KENKEN8
以上就是全部五个问题的答案了,通过自问自答这五个问题,我们就可以高效地学习某种数据结构了。
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330