



2018-11-16
阅读量:
1412
阐述随机森林原理
先回顾一下决策树原理:
1.给定数据框(nxp),树基于规则(if-else)对数据进行分层或分区。 是的,一棵树创造了规则。 这些规则将数据集划分为不同的和不重叠的区域。 这些规则由变量对所得子节点(X2,X3)的均匀性或纯度的贡献来确定。
2.变量X1导致子节点中的最高同质性,因此它成为根节点。 根节点处的变量也被视为数据集中最重要的变量。
3,但这种同质性或纯度如何确定? 换句话说,树如何决定拆分哪个变量?
- 在回归树中 (其中使用终端节点中的观察的平均值来预测输出),分裂决策基于最小化RSS。 选择导致RSS最大可能减少的变量作为根节点。 树分裂采用自上而下的贪婪方法,也称为递归二进制分裂 。 我们称之为“贪婪”,因为该算法需要在当前步骤中进行最佳分割,而不是在未来节点上保存分割以获得更好的结果。
- 在分类树中 (使用终端节点中的观察模式预测输出),分裂决策基于以下方法:
- 基尼指数 - 它是节点纯度的衡量标准。 如果Gini索引采用较小的值,则表明该节点是纯粹的。 要进行拆分,子节点的Gini索引应小于父节点的Gini索引。
- 熵 - 熵是节点杂质的量度。 对于二进制类(a,b),计算它的公式如下所示。 熵在p = 0.5时最大。 对于p(X = a)= 0.5或p(X = b)= 0.5意味着,新观察结果有50%-50%的机会被分类到任一类。 当概率为0或1时,熵最小。
Entropy = - p(a)*log(p(a)) - p(b)*log(p(b))
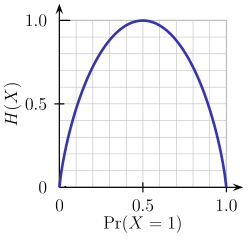
简而言之,每棵树都试图以这样的方式创建规则,使得最终的终端节点尽可能地纯净。 纯度越高,做出决定的不确定性越小。
但决策树的差异很大。 “高方差”意味着在看不见的数据上获得高预测误差。 我们可以通过使用更多数据进行培训来克服方差问题。 但由于可用的数据集仅限于我们,我们可以使用重新取样技术(如装袋和随机林)来生成更多数据。
构建许多决策树就变成了森林 。 随机森林的工作方式如下:
- 首先,它使用Bagging(Bootstrap Aggregating)算法创建随机样本。 给定数据集D1(n行和p列),它通过随机抽样n个案例并从原始数据中替换来创建新数据集(D2)。 D1中大约1/3的行被省略,称为Out of Bag(OOB)样本。
- 然后,模型在D2上训练。 OOB样本用于确定误差的无偏估计。
- 在p列中,在数据集中的每个节点处选择P << p列。 P列是随机选择的。 通常,对于回归树,P的默认选择是p / 3,对于分类树,P是sqrt(p)。
- 与树不同,在随机森林中不进行修剪; 即,每棵树都完全生长。 在决策树中,修剪是一种避免过度拟合的方法。 修剪意味着选择导致最低测试错误率的子树。 我们可以使用交叉验证来确定子树的测试错误率。
- 种植了几棵树,通过平均或投票获得最终预测。
每棵树都生长在不同的原始数据样本上。 由于随机林具有在内部计算OOB错误的功能,因此交叉验证在随机林中没有多大意义。
 0.0000
0.0000
 0
0
 2
2

 关注作者
关注作者
 收藏
收藏

评论(0)
 发表评论
发表评论
暂无数据







推荐帖子
CDA助教老师
2023-06-20
0条评论
CDA助教老师
2021-03-31
0条评论
CDA助教老师
2021-03-30
0条评论