


2023-06-20
阅读量:
2349
CDA数据分析学习之机器学习中损失函数、代价函数和目标函数的区别
损失函数(Loss Function )是定义在单个样本上的,算的是一个样本的误差。
代价函数(Cost Function )是定义在整个训练集上的,是所有样本误差的平均,也就是损失函数的平均。
目标函数(Object Function)定义为:最终需要优化的函数。等于经验风险+结构风险(也就是Cost Function + 正则化项)。
PS:关于目标函数和代价函数的区别还有一种通俗的区别:目标函数是最大化或者最小化,而代价函数是最小化。
举个例子解释一下:(图片来自Andrew Ng Machine Learning公开课视频)

上面三个图的函数依次为,
,
。我们是想用这三个函数分别来拟合Price,Price的真实值记为
。
我们给定,这三个函数都会输出一个
,这个输出的
与真实值
可能是相同的,也可能是不同的,为了表示我们拟合的好坏,我们就用一个函数来度量拟合的程度,比如:
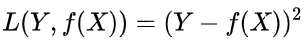 ,这个函数就称为损失函数(loss function),或者叫代价函数(cost function)(有的地方将损失函数和代价函数没有细分也就是两者等同的)。损失函数越小,就代表模型拟合的越好。
,这个函数就称为损失函数(loss function),或者叫代价函数(cost function)(有的地方将损失函数和代价函数没有细分也就是两者等同的)。损失函数越小,就代表模型拟合的越好。
那是不是我们的目标就只是让loss function越小越好呢?还不是。
这个时候还有一个概念叫风险函数(risk function)。风险函数是损失函数的期望,这是由于我们输入输出的 遵循一个联合分布,但是这个联合分布是未知的,所以无法计算。但是我们是有历史数据的,就是我们的训练集,
关于训练集的平均损失称作经验风险(empirical risk),即
 ,所以我们的目标就是最小化 ,
,所以我们的目标就是最小化 ,
称为经验风险最小化。
如果到这一步就完了的话,那我们看上面的图,那肯定是最右面的 的经验风险函数最小了,因为它对历史的数据拟合的最好嘛。但是我们从图上来看
肯定不是最好的,因为它过度学习历史数据,导致它在真正预测时效果会很不好,这种情况称为过拟合(over-fitting)。
为什么会造成这种结果?大白话说就是它的函数太复杂了,都有四次方了,这就引出了下面的概念,我们不仅要让经验风险尽量小,还要让结构风险尽量小。。这个时候就定义了一个函数 ,这个函数专门用来度量模型的复杂度,在机器学习中也叫正则化(regularization)。常用的有
,
范数。
到这一步我们就可以说我们最终的优化函数是: ,即最优化经验风险和结构风险,而这个函数就被称为目标函数。
,即最优化经验风险和结构风险,而这个函数就被称为目标函数。
结合上面的例子来分析:最左面的 结构风险最小(模型结构最简单),但是经验风险最大(对历史数据拟合的最差);最右面的
经验风险最小(对历史数据拟合的最好),但是结构风险最大(模型结构最复杂);而
达到了二者的良好平衡,最适合用来预测未知数据集。
 0.0000
0.0000
 0
0
 0
0

 关注作者
关注作者
 收藏
收藏

评论(0)
 发表评论
发表评论
暂无数据







推荐帖子
CDA助教老师
2024-10-15
0条评论
大傻叉1号
2024-10-08
0条评论
CDA助教老师
2024-04-17
1条评论
CDA138749
2024-04-01
0条评论