
CDA数据分析师 出品
作者:Mika
数据:真达
如果说冬天对北方人来说只是一个季节,而对南方人来说是一场“渡劫”。北方的冷是干冷,物理攻击,多穿一点就好了。而且室内有暖气,在室内可以穿着短袖吃冰棍。
而南方的冷是湿冷,魔法攻击,穿再多没有用。而且室内还没暖气,各种段子也是层出不穷:
“你在北方的暖气里四季如春,我在南方的寒冬下冻成冰棍儿”
“北方人过冬靠的是暖气,南方人过冬靠的是一身正气”
“我是一只来自北方的狼,来到南方却被冻成了狗”

一到冬天南方人除了靠一身浩然正气,空调、电热毯、油汀、电暖气等各类花式取暖电器都得安排上。
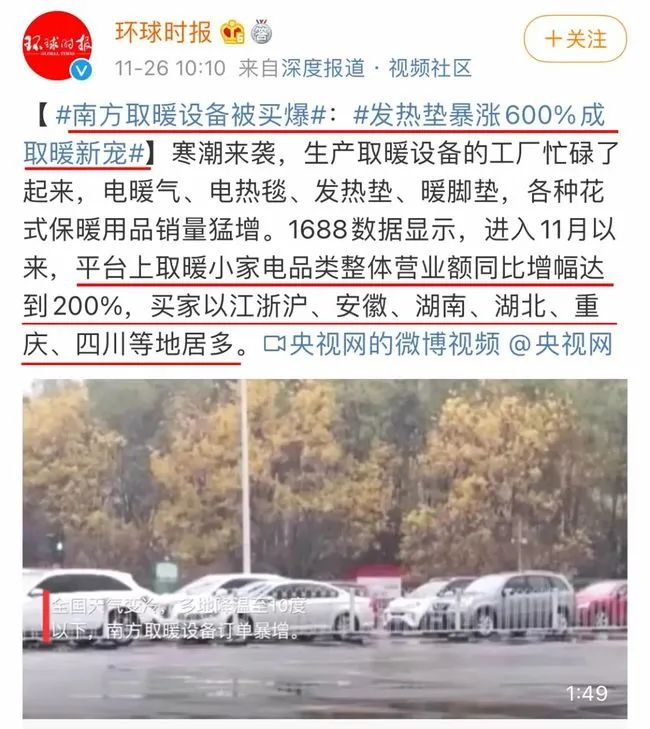
内贸批发平台1688上获取的数据显示,进入11月以来,暖气片在南方城市的销量比去年同期增长了300%,平台上取暖小家电品类整体营业额同比增幅达到200%,其中发热垫的同比增速甚至高达600%。
据显示,暖气片和暖气设备销量贡献最大的国内客户,主要都是来自长江沿线城市,以江浙沪、安徽、湖南、湖北、重庆、四川等地居多,一时间“南方取暖设备被买爆”话题登上了微博热搜,让人不禁感叹南方人过个冬天实在是太难了。
那么取暖器的全网销售数据是怎样的呢?今天我们就带你用看一看。
用Python分析全网取暖器数据
我们使用Python获取了淘宝网搜索关键词暖气片、取暖器、壁挂炉的商品数据,并进行了数据分析。
1.读取数据
首先导入获取的数据。
# 导入工具包 import numpy as np import pandas as pd from pyecharts.charts import Bar, Pie, Map, Page from pyecharts import options as opts import jieba
# 读取数据 df_all = pd.read_csv('../data/导出数据.csv')
df_all.head()
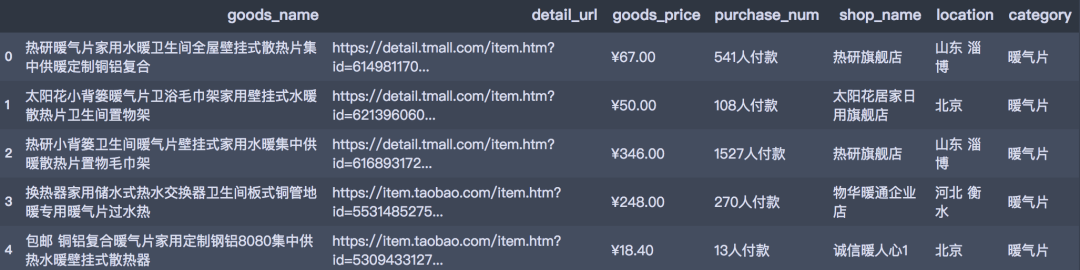
df_all.shape (13212, 7)
2.数据清洗和整理
此处我们需要对数据集进行数据清洗以便后续分析和可视化,主要工作内容如下:
-
删除记录的重复值
-
goods_price列处理:提取数值
-
purchase_num列处理:提取数值
-
计算销售额sales_volume = goods_price*purchase_num
-
删除多余的列
代码实现如下:
df = df_all.copy() # 去除重复值 df.drop_duplicates(inplace=True)
df.shape
(6849, 7)
# 筛选记录 df = df[df['purchase_num'].str.contains('人付款')] # goods_price列处理 df['goods_price'] = df['goods_price'].str.extract('(d+.{0,1}d*)')
df['goods_price'] = df['goods_price'].astype('float') # purchase_num列处理 df['num'] = df['purchase_num'].str.extract('(d+.{0,1}d*)')
df['num'] = df['num'].astype('float')
df['unit'] = [10000 if '万' in i else 1 for i in df['purchase_num']] # 计算销量 df['purchase_num'] = df['num'] * df['unit'] # 计算销售额 df['sales_volume'] = df['goods_price'] * df['purchase_num'] # 提取省份字段 df['province_name'] = df['location'].astype('str').str.split(' ').apply(lambda x:x[0]) # 删除多余的列 df.drop(['num', 'unit', 'detail_url'], axis=1, inplace=True) # 重置索引 df = df.reset_index(drop=True)
df.head()

3.数据可视化
此处我们对店铺销量、产地分布、商品价格等方面进行可视化分析:
市场上的取暖器种类较多,有暖风机、小太阳、电热膜、油汀、快热炉、踢脚线等取暖设备,我们首先看到这些取暖器的标题词云。
商品标题词云图

可以看到"取暖器" "暖风机" "暖气片"都是出现的高频词。在特征方面"家用" "节能" "速热"都十分常见。
接着,看到店铺月销量排名Top10。
店铺月销量排名Top10
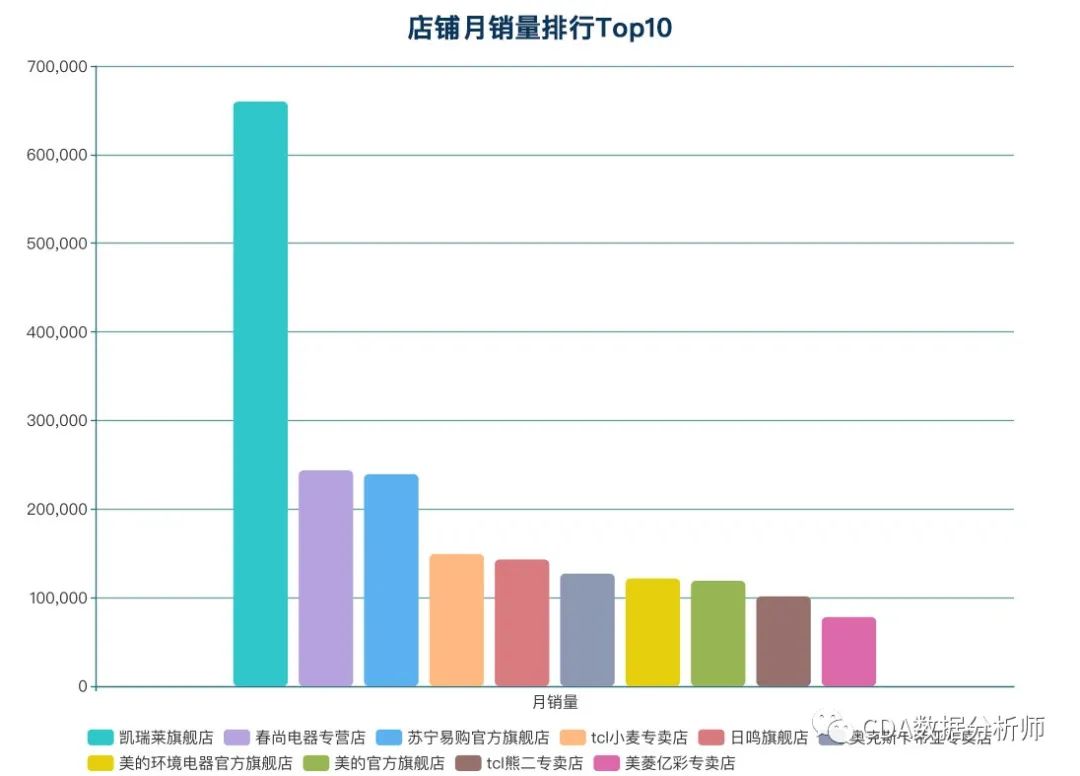
可以看到店铺销量前十,凯瑞莱旗舰店位居第一。其后春尚电器专营店和苏宁易购分别是第二第三名。排在前十的还有美的、tcl等品牌。
# 计算top10店铺 shop_top10 = df.groupby('shop_name')['purchase_num'].sum().sort_values(ascending=False).head(10)
全国各省份产地销量排名Top10
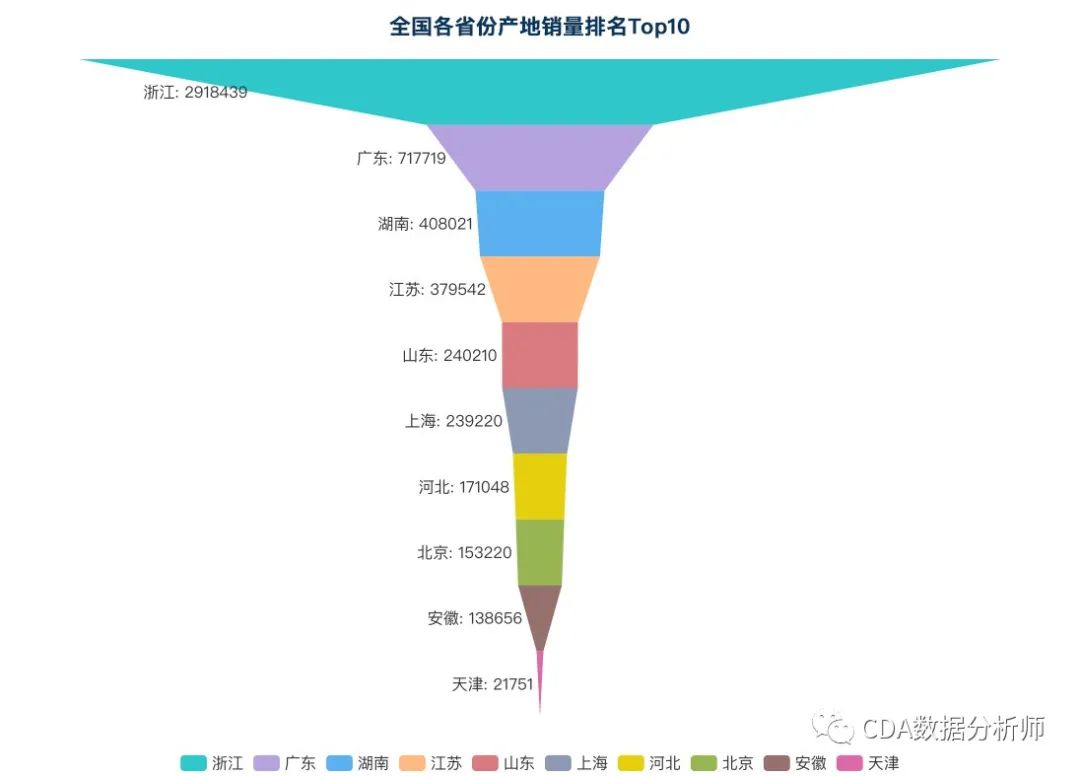
这些取暖器的产地都在哪儿呢?经过分析发现,浙江是生产取暖器的头号大省,在产地销量排名中一骑绝尘位居第一。之后排在第二位的是广东。湖南、江苏、山东分别位居第三第四第五名。
# 计算销量top10 province_top10 = df.groupby('province_name')['purchase_num'].sum().sort_values(ascending=False).head(10)
不同价格区间的商品数量占比
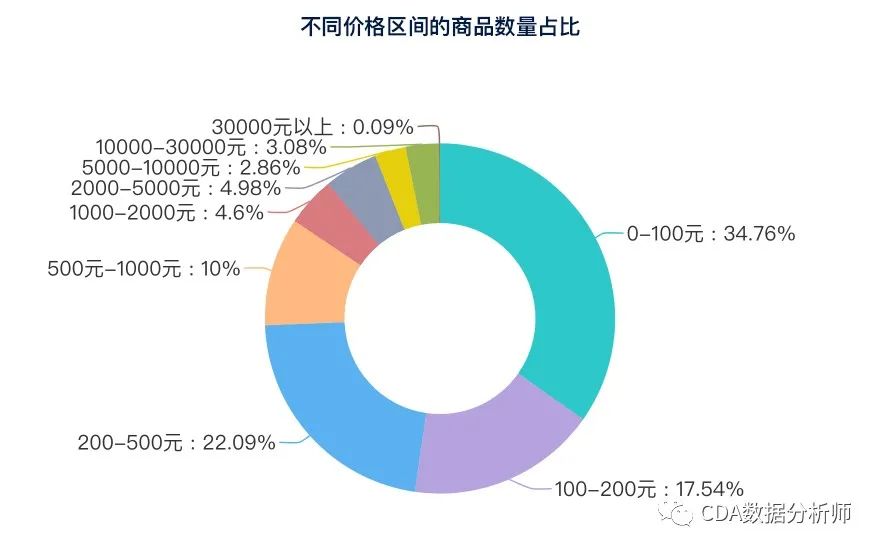
取暖器都卖多少钱呢?经过分析发现,100元以下的商品是最多占比高达34.76%。其次是200-500元的商品,占比22.09%。
不同价格区间的销量占比
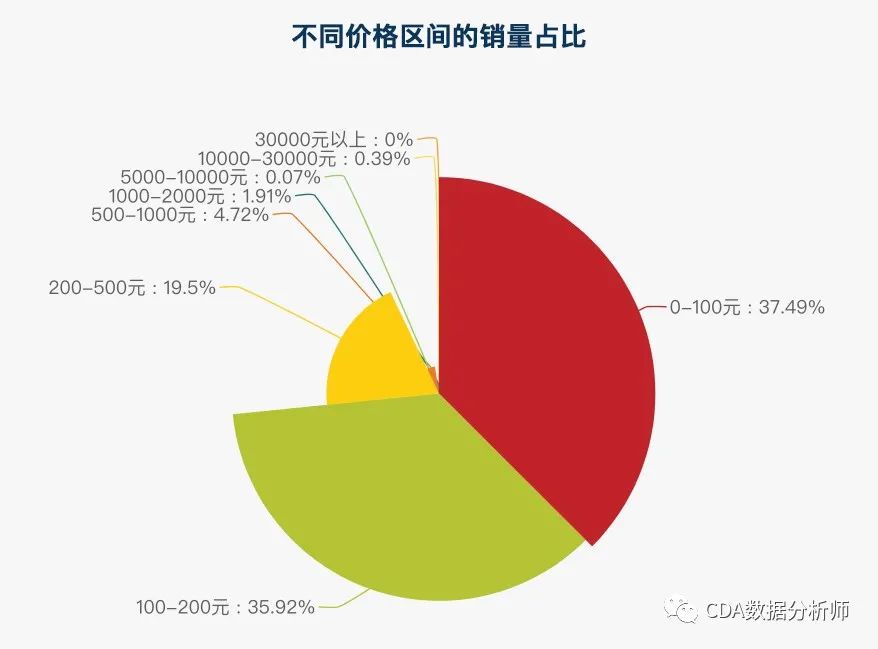
与此同时,在销量方面,价格在100元以下和100-200元之间的取暖产品也是销量最好的,全网销售量分别占比37.49%和35.92%。
结语
有了各式各样的取暖器,南方冬天就好过了吗?并不,空调开久了干,踢脚线耗电高,油汀等电暖气更适合局部取暖,大空间制热效果差。
虽然近年来也有很多南方家庭选择全房装地暖的,然而电暖用起来一个月电费就高达2、3千,这可能就是北方一个冬天的暖气费用了。这么对比起来,似乎还是开空调和取暖器实在啊。
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330