
“你喜欢旅游吗?”
这个简单的问题经常会得到一个积极的回复甚至还会额外收到一个或两个冒险的故事。通常来讲,旅行是一种体验新文化和拓宽自己视野的好方法。
但如果把问题换成“你喜欢查机票的过程吗?”,我敢肯定大家的反应一定会不那么热情......
那么,用Python解决你的难点吧!本文作者Fábio Neves,一位资深的商业数据分析师将会带你建立一个网络爬虫项目,帮助我们找到最优惠的价格!
具体做法是对特定目的地以及灵活的日期范围(根据你选择的日期前后最多3天)进行航班价格搜索。
搜索结果保存到一个excel中并为你发送一封展示快速统计信息的电子邮件。显然,最终的目的是帮助我们找到最优惠的价格!
如果你真的想试试,你可以在服务器上执行这个脚本(一个简单的Raspberry Pi就可以(注:Raspberry Pi树莓派又称卡片式电脑,外形只有信用卡大小,运算性能和智能手机相仿。So大家在自己笔记本电脑上折腾就足够了。。)),并且每天运行一次或两次。它会将检索结果以邮件的形式发给你,我建议将excel文件保存到Dropbox云端,这样你就可以随时随地访问它。
注:Dropbox是一个类似于百度云的云端服务
我还是没找到任何错误低价票,但我想还是有可能的!
它会根据“弹性日期范围”进行检索,以便查找你首选日期的前后最多3天的所有航班。尽管该脚本一次只适用于一组from/to目的地,但你可以轻松地调整它在每个循环内运行多组行程目的地。你甚至可能最终找到一些错误低价票......简直棒极了!
爬虫脚本
当我第一次开始做网络爬虫时,我对这块并不特别感兴趣。我本想用预测建模,财务分析和一些情绪分析来做更多的项目,但事实证明,弄明白如何构建第一个网络爬虫是很有趣的。随着我不断学习,我意识到网络抓取是互联网运转的精髓。

是的......就像Larry 和 Sergey一样,在启动爬虫程序后去尽情享受按摩浴缸吧!
你可能认为这是一个非常大胆的想法,但如果我告诉你谷歌就诞生于Larry 和 Sergey通过Java和Python写的爬虫程序呢?谷歌通过爬取整个互联网来试图为你的问题提供最佳答案。有非常多关于网络爬虫的应用程序,即便你更喜欢数据科学中的其他主题,你仍然需要一些爬虫技能来获取想要的数据。
Python可以来拯救你
第一个挑战是选择从哪个平台抓取信息。这其实并不容易,但我最终选择了Kayak。决定之前我尝试了Momondo,Skyscanner,Expedia等等,但这些网站上的验证码部分真的是让人抓狂。经过几次尝试选择交通信号灯,人行横道和自行车的这种“你是真人吗”的检查后,我的结论是Kayak是目前最好的选择,即使它在短时间内加载太多页面时也会抛出安全性校验。
我设置机器人以4到6小时的间隔来查询网站,这样就不会有问题了。在这里和那里偶尔可能会出现卡壳中断现象,但是如果你遇到验证码校验,那么你需要手动进行验证码认证,确认完毕后再启动机器人程序,然后等待几个小时它就会重置。你也可以随意将这些代码应用到其他平台,欢迎你在评论部分分享你的应用!
如果你是个爬虫新手,或者还不了解为什么有一些网站总会设置各种障碍来阻止网络抓取,那么在写第一行爬虫代码之前,请你先阅读了解一下谷歌“ 网络抓取礼仪 ”。如果你像疯子一样准备好了开始网络抓取,你获得努力成果可能会比你想象的要快得多。
网络抓取礼仪 :
http://lmgtfy.com/?q=web+scraping+etiquette

请系好安全带……
打开chrome标签页后,我们将定义一些在循环内使用的函数。关于整体结构的大致想法是这样的:
-
一个函数将启动机器人,声明我们想要搜索的城市和日期。此功能获取第一批搜索结果并按“最佳”航班进行排序,随后点击“加载更多结果”。另一个函数将抓取整个页面,并会返回一个dataframe数据集重复步骤2和3获取“最便宜”和“最快”的排序结果。电子邮件将价格的最终结果(最便宜和平均值)发送给你,并且将三个排序(价格、时间、整体最佳)的数据集保存为一个excel文件前面的所有步骤循环重复,每隔X小时运行一次。
OK,每个Selenium项目都将以webdriver作为开头。我用的是ChromeDriver,当然还有其他选择。比如,PhantomJS或Firefox也很受欢迎。webdriver下载好之后,将其放在一个文件夹中就可以了。代码的第一行将会自动打开一个空白的Chrome标签页。
请注意,我不是在这里开辟新天地,或是提出一种非常具有开拓性的创新。当下确实已经有更先进的方法来寻找便宜的票价,但我希望我的这个帖子可以跟大家分享一些简单而实用的东西!
这些是我用于整个项目所引用的包。我将使用randint来让机器人在每次搜索之间随机停顿几秒钟。这是所有机器人所必备的功能。如果你运行了前面的代码,则需要先打开一个Chrome网页窗口作为机器人检索的入口。
所以,先让我们来快速测试一下,在新网页打开http://kayak.com。选择你要飞往的城市和日期。选择日期时,请务必选择“+ -3天”。我已经编写了相关的代码,如果你只想搜索特定日期,那么你需要适当地进行一些调整。我将尽量在整个文本中指出所有的变动值。
点击搜索按钮并获取地址栏中的链接。这个链接应该就是我在下面需要用的链接,在这里我将变量kayak定义为url并调用webdriver的get方法。你的搜索结果接下来应该就会出现了。
每当短时间内多次使用get命令的时候,系统就会跳出验证码检查。你可以手动解决验证码问题,并在下一个问题出现之前继续测试脚本。从我的测试来看,第一次搜索运行似乎一切正常,所以如果你想要用这段代码,并且让它们之间保持较长的执行间隔,就可以解决掉这个难题。你并不需要每10分钟就更新这些价格,不是吗?!
XPath的坑
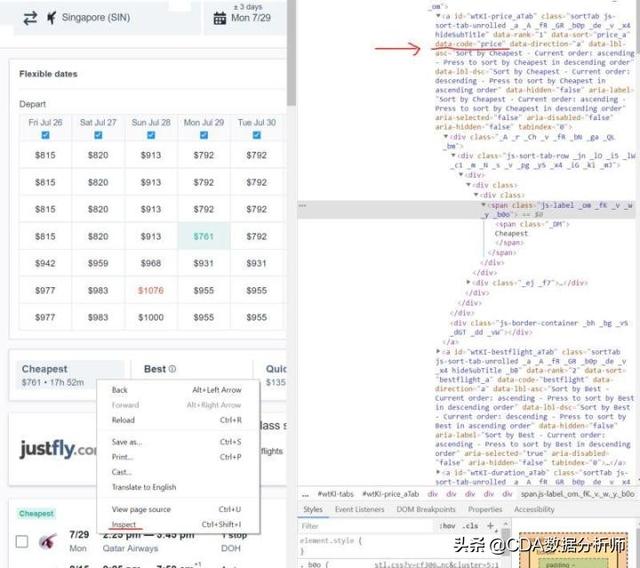
目前为止,我们打开了一个浏览器窗口并获得了网址。接下来我会使用XPath或者CSS选择器来抓取价格等其他信息。曾经我也只用XPath,当时我觉得没必要用CSS,但是现在看来最好结合着用。你可以直接用浏览器复制网页XPath来用,你也会发现由XPath虽可以定位网页元素但是可读性很差,所以我渐渐意识到只用XPath很难获得你想要的页面元素。有时候,指向得越细就越不好用。
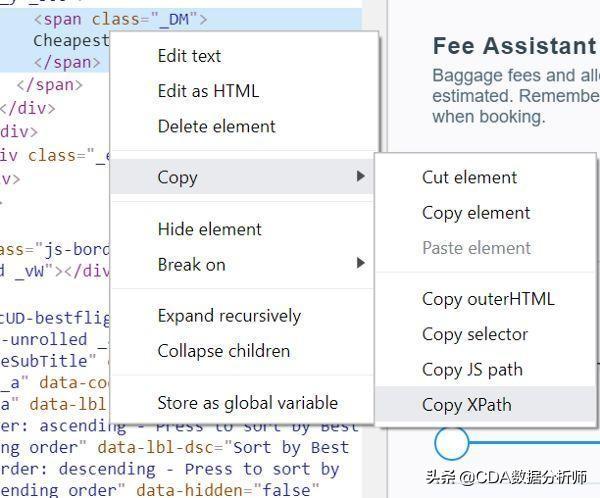
接下来,我们用Python来选择出最低票价的页面元素。上述代码中红色部分就是XPath选择器的代码,在网页中,你可以在任意位置点击右键并选择“检查”来找到它。试试吧,在你想看代码的地方点右键,“检查”它。
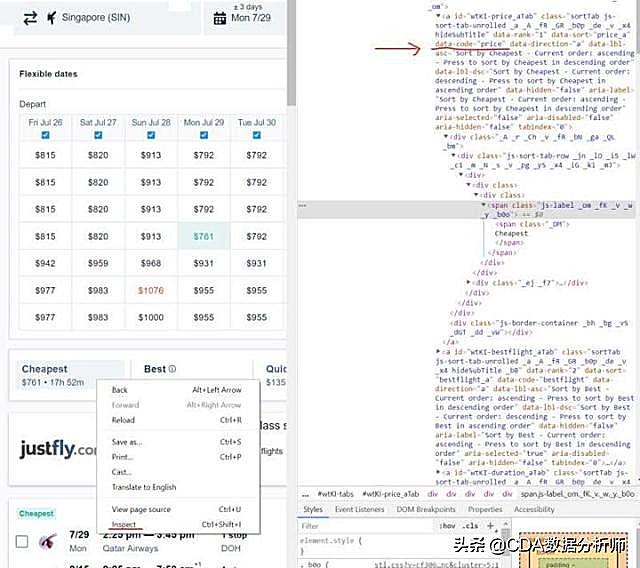
为了说明我前面所说的XPath的不足,请大家对比如下差异:
1 # This is what the copy method would return. Right click highlighted rows on the right side and select "copy > Copy XPath"//*[@id="wtKI-price_aTab"]/div[1]/div/div/div[1]/div/span/span2 # This is what I used to define the "Cheapest" buttoncheap_results = ‘//a[@data-code = “price”]’
上述代码中,第二种方式的简洁性清晰可见。它会去搜素具有data-code属性值为price的a元素。而第一种方式则是去搜素一个id为wtKI-price_aTab元素,且该元素嵌在5层div及2层span内。对于这次页面,它能起作用,但这里的坑在于,下次加载页面时,这个id会变,而且每次加载时wtKI值也是动态变化的,所以到时候这段代码就无效了。所以多花点功夫研究一下XPath表示的内容还是对你有价值的。
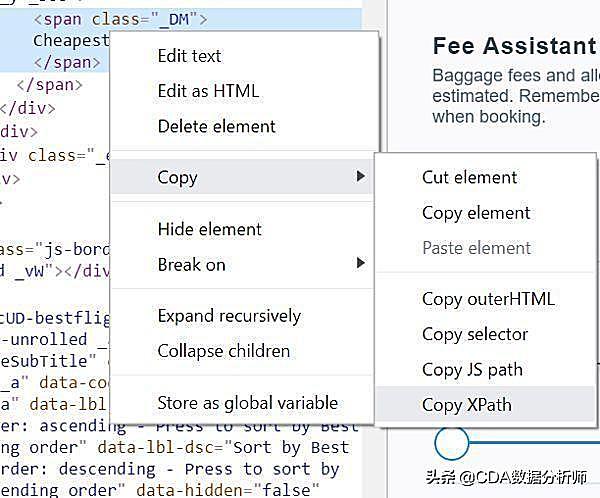
不过这种直接复制XPath的方法对于那些不是很复杂善变的页面来说还是蛮好用的。
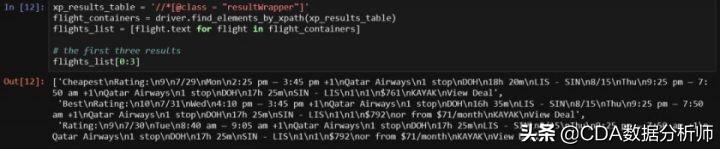
基于上述代码结果,如果我想找出所有匹配的结果并存到list里,该怎么做呢?很简单,因为所有结果都在CSS对象resultWrapper中,只要按照我下图代码中写个for循环就能获得所有结果。这个思路掌握了,那下图的代码你也就基本看明白了。也就是说,先选定最外层的页面元素(如本文网站中的resultWrapper),再找一种方式(如XPath)来获取信息,最后再将信息存到可读的对象中(本例中先存在flight_containers中,再存在flights_list中)。
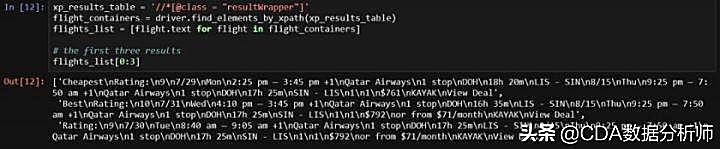
我把前三个结果详细内容都打印出来了,里面有我们需要的全部有用信息,但我们还是要找个更好的方法提取它们,这时我们就要对这些元素单独解析。
开始爬数据!
最简单的代码就是读取更多这个函数,我们先从这里开始。我希望在不触发安全校验的情况下获取尽量多的航班,所以在每次加载完页面我都会点击“load more results”按钮。值得注意的是我用到了try语句,因为有的时候不一定会存在这个按钮。
哦嘞,前期铺垫的有点长(抱歉,我确实比较容易跑偏)。我们现在要开始定义用于爬数据的函数了。
我在下文会提到的page_scrape函数中解析了大部分元素。有时候,返回来的航班list中会有两段行程。我简单粗暴地把它拆成两个变量,如section_a_list 和section_b_list。当然,函数还是会返回一个名为flights_df 的DataFrame对象,有了它我们接下来就可以任意排序并视情况切片或合并。
变量名中带a的表示第一段行程,带b的表示第二段行程。接着看下一个函数。
别急,还有干货!
到现在为止,我们有用于加载更多结果的函数,有用于解析这些结果的函数。你可以认为这就完事了,可以靠着它们去手动地爬网页了,但我前面还提到过,我们的目标是能给自己发邮件,当然还能包括一些其他信息。看看下面这个函数start_kayak,所有这些都在里面。
这需要我们定义一下要查询的航班的地点和日期。我们会打开kayak变量中的网址,并且查询结果会直接按照“best”方式排序。在第一次爬数之后,我就获得了页面上方的价格矩阵数据集,它将用于计算均价和最低价,然后和Kayak的预测价(页面的左上角)一起通过电子邮件发出。在单个日期搜素时可能导致错误,因为这种情况下页面顶端没有价格矩阵。
我用outlook邮箱(http://hotmail.com)做了测试。虽然Gmail我没试过,甚至还有其他各种邮箱,但我想应该都没问题。而且我前文提到的书中也写了其他发邮件的方式,如果你有hotmail邮箱,可以直接在代码中替换你的邮箱信息,就可以用了。
如果你想知道脚本中某部分代码的功能,你要把那部分拷出来测试一下,因为只有这样你才能彻底地理解它。
把代码跑起来
当然,我们还能把我们前面编的函数放进循环里让它一直执行。写明4个输入提示,包括起降的城市和起止时间(输入)。但在测试的时候,我们并不想每次都去输入这个四个变量,就直接修改4个变量,如注释的那四行代码所示。
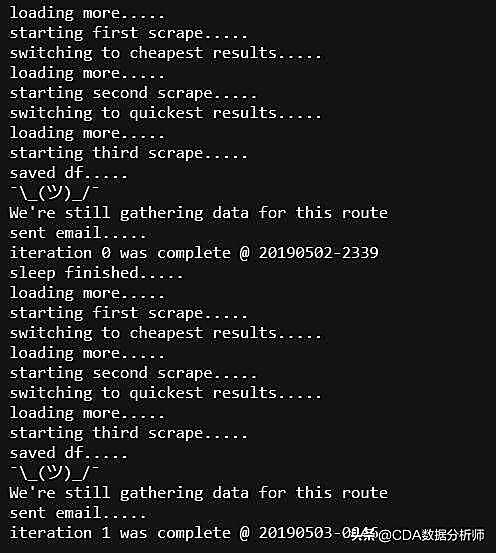
恭喜各位,至此我们已经大功告成了!其实还有很多可以改进的地方,比如我能想到的还可以用Twilio实现发送短信进而取代邮件。你还能架VPN或者以其他隐蔽的方式,同时通过多个服务器来爬数据。还有验证码问题,它们总会不时地跳出来,不过这还是有办法解决的。如果你有比较好的基础,我觉得你可以试试加上这些功能。甚至你还会想把Excel文件作为邮件的附件一起发出。
编译:高延、熊琰、胡笳、蒋宝尚
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;















 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330