
作者 | Sowmya VB
翻译 | Mika
本文为 CDA 数据分析师原创作品,转载需授权
我在多伦多的一家中型软件公司担任数据科学家。在过去的几个月里,我担任了三场数据科学职位面试的面试官,这三场面试面向数据工程师、数据科学家和数据科学QA。
本文包含了我作为面试官在筛选简历时的一些想法。希望这篇文章能够对想找是数据科学相关工作的人有所帮助。
在公司中,“数据科学”团队是一个相对较新的现象,其中包括各种各样的角色。随着这些角色越来越多,也有越来越多的机构提供数据科学认证课程。暂时不考虑当中哪些认证是好的,我们开始看到许多带有“认证数据科学家”标签的简历,这也加大了评估简历的难度。
通常情况下,当你在挑选数据科学团队成员时,你会寻找哪些点呢?
我会注重这几点:
a)与团队工作相关的经验
b)在简历中提到的相关能力的细节。
经验部分很明显,关于第二点具体而言我主要看到这几点:
1. 清楚并完整描述求职者曾在何时何地工作/学习
2. 作品集:在Github主页或技术博客
3. 具体的技能和成果部分
4. 简历的长度

下面我会具体谈谈这几点,以及为什么我认为这些很重要。
1. 清楚并完整的描述
有些简历中没有提到求职者目前工作的国家或城市。我认为这很重要,特别对于有签证限制或希望雇用当地人的雇主(我不评论这是好是,但这只是一些雇主的偏好)。直到面试后期才意识到这方面的问题是很浪费时间的。
还有些求职者候没有提到毕业院校的国家或地区。虽然这并不是太大的问题,但我认为还是不太完整,因为并非所有大学都很有名。如果有人写毕业于“斯坦福大学”,但没有写清楚具体国家,我仍然称之为不完整,但不是很严重的那种。然而,如果有人写了毕业于“ABC工程学院”,且之后没有具体的说明,那该简历的真实性是有些可疑的。这点只是我的个人意见,但我确信不止我一个人这么想。改善这点也很简单,写明具体的国家或城市,这样能让简历更准确且完整。
2. 作品集
我认为这对于刚接触数据科学的人来说尤其重要,特别是对于刚完成相关认证课程和项目的人群。列出完成的课程是不够的,因为完成课程的人都必须完成某些项目。除此之外,求职者还必须展现给面试官,他们学到了什么,并且能够将所学应用到具体的问题情景中。
完成个人数据科学项目。例如,不属于任何课程的Kaggle比赛等;发布过一些文章,关于最近阅读的内容,或喜欢的工具、算法等。
3.所提到的技能或成果
这里并不是指像MS Office、敏捷方法论、参加每日Scrum会议,在机器学习课程中取得优异成绩等。我希望在技能方面看到求职者展现的是,所掌握的编程语言、机器学习库、可视化库、项目管理等。以及一些实际的成就,比如我构建的模型A减少了软件B中XX%的错误之类。在简历中堆满相关技能的关键字也是不可取的,这可能会通过机器筛选,但会在人为筛选中被刷下来。
4.简历的长度
对于简历的长度,不同国家有不同的规范。最近,在LinkedIn上,Andriy Burkov关于这个问题提出了他的看法。
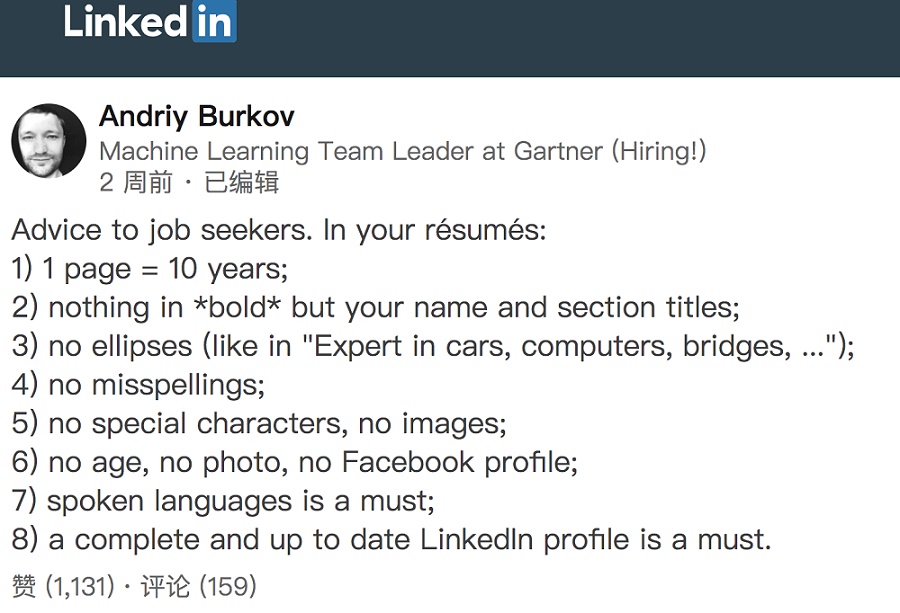
他认为,对于工作经验不到10年的人来说,简历应该只有1页。但是,我经常看到长达7-8页的简历,而且当中没给我任何有价值的信息。每个小项目都详细地进行解释,而许多项目甚至与数据科学无关。
一些博士生和博士后会在简历列出所有发表的文章,但这并不太符合行业背景。我本人有博士学位,对于有些工作我会提交长8页的简历,当中列出我发表的全部文章。但我还有一份2页的简历,专门针对那些与工程团队联系更紧密的职位。
除此之外,另一件让我感到不解的是,有些人在电话面试中表现得很冷漠。表现出对这份工作的兴趣,更多地了解团队构成,比如数据科学团队有多少人,工作流程是怎样的等等,以及对面试过程的好奇心。这些都体现出求职者对这份工作的兴趣。在我有限的经验中,不问这些问题是危险信号。
总而言之,在准备简历和准备面试时,要记住以下五点:
1.确保简历清晰、简洁
2.建立个人作品集,在简历中附有具体的链接,比如GitHub个人主页或博客
3.简明扼要地描述技能和成果,且与职位相关
4.不要让简历太长
5.表现出对公司和职位的兴趣
那么,这是否意味着没有数据科学经验的人不应该申请呢?
当然不是。让我们以P为例,他是一位自学的数据科学家。他上了一些在线课程,然后开始自己做个人项目。他不写博客,也没有在github列出所有项目内容,但他能够详细描述自己所做的内容。那么该如何展示在简历中呢?可以类一个“个人数据科学项目”的部分,罗列完成的个人项目,每个项目3、4句话。仅仅是Kaggle比赛还不够,毕竟它们与真实情况有些距离。
最终,每个人的目标都是让自己的简历在其他求职者中脱颖而出。

CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330