Social Network 社交网络分析_数据分析师
一:什么是SNA-社交网络分析
社交网络分析的威力何在?我想几个案例来说明。
案例1:对一个毫无了解的组织(这个组织可以是一个公司,亦或是一个组织),如果能够拿到这个组织成员之间的信息流动记录(例如通话记录/或邮件记录),那么通过SNA可以分析出谁是这个组织的实际控制者(要知道有必要加上实际二字),谁是这些成员中有影响力的人,那些成员更倾向于聚集在一起。对上述问题的回答可以用来做公关-把精力用在对的人身上;用来处理组织架构;用来游说获得支持--关系紧密的人会更倾向于支持同一种意见,一方面是由于观点相同所以关系紧密,另一方面你的大部分朋友都支持的事情你总不会下脸来做那个少数派吧。
案例2:举个现实中的例子吧,鹅厂刚推出朋友圈的时候我对这个产品的印象非常好,因为它给我推荐的朋友有一些是很多年都没有联系,不特意提起都想不起来名字的“朋友”。包括人人网推荐的好友也是很精准的。这些产品的背后就是用的SNA-朋友的朋友也是我的朋友,敌人的朋友是我的敌人,敌人的敌人是我的朋友,朋友的敌人是我的敌人。
这两个案例是直观印象中的社交网络分析,网络中的节点是人。如果把SNA只用在人身上那就太狭隘了。相同的思想完全可以用在物身上。例如:
案例3:豆瓣FM也是我很喜欢的一款产品---与你喜欢的音乐不期而遇。一些歌曲是我对某一个时期的感觉印记,有些印记记忆犹新,有些印记逐渐模糊。时不时就能在豆瓣FM和这些或清晰或模糊的印记不期而遇,让人惊喜。为什么豆瓣FM能做到这点那?是它对歌曲按照什么节奏/曲调/风格/歌词做了分类吗?如果你这样认为那就太傻太天真了。这里的SNA每一首歌就是网络中的每个节点,而你的喜欢或不再播放就给你听过的歌曲之间加强/减弱了联系。
经过上面三个案例,可以对SNA有个初步了解。
二:我的好友圈
一般来说有两大途径来获得好友圈:1)社交应用/社交网站,比如人人/微博/微信。2)通信记录-电话/邮件/短信。后者数据都掌握在相应的运营商,前者的数据可以从应用开放的API或者简单粗暴一点自己写蜘蛛爬。
我采用写爬虫的方式得到了人人的好友圈。抓了两层好友,即我的好友,和我好友的好友。其实这个层数可以自己设定,用递归函数很容易实现。唯一消耗的是运行时间和存储。即使只抓两层好友圈,用我的笔记本也跑了15分钟。
接下来该networkx登场了。一通运算之后得到如下结果:
1)两层好友圈
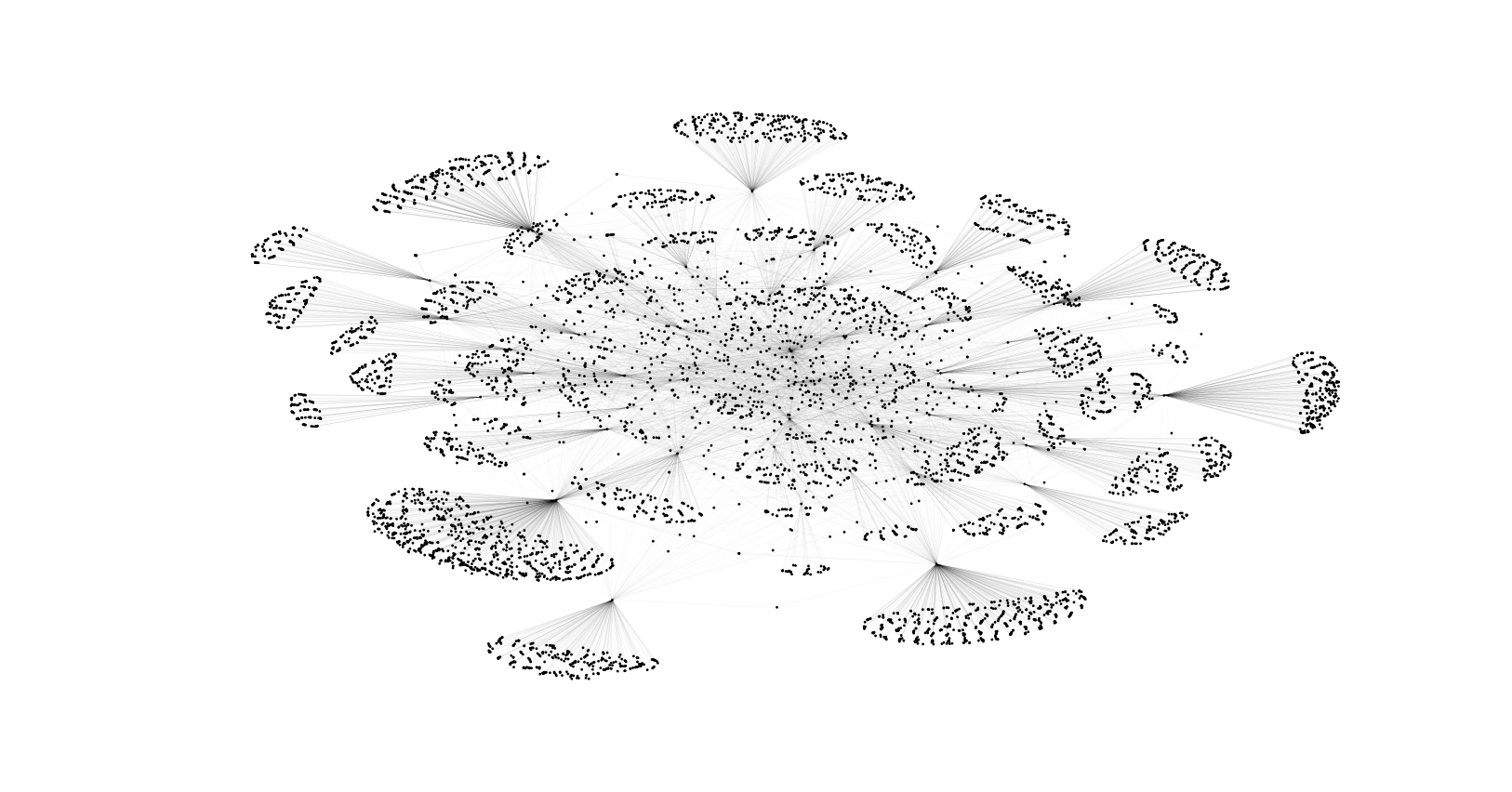
这是对7169个好友关系的做图。当然最中心的点是我自己。可以看到周围一圈是相对孤立的“云”,那是因为我只抓了两层的原因。
七千多个好友,这么多层关系,如何分析?别担心,社交网络分析不是一个新兴的领域,看米国文献说这个领域从六七十年代就有了,只不过是近十年火起来的。所以有一大堆现成的算法来基本搞定你的大部分需求。
对七千多个好友的基本分析如下:
---------------2014-06-08 21时32分16秒开始整体分析----------------
社交网总共有7169个好友
排名前10的好友数
1--徐希文--909
2--刘杉--607
3--李超--505
4--colipso--405
5--吕秀芳--343
6--藏新汀--336
7--王大舸--312
8--王卉卉--258
9--孙昊--255
10--杨子旭--248
--------2014-06-08 21时32分16秒开始受欢迎指数分析(基于closenes centrality)------------
受欢迎指数排名前10的好友为
1--colipso--0.51
2--马佳--0.50
3--徐希文--0.40
4--贾丽娜--0.40
5--洛锋--0.39
6--张伟--0.39
7--陈欣--0.39
8--王蕴杰--0.39
9--孙峰--0.39
10--张宁--0.38
---------2014-06-08 21时35分15秒开始枢纽指数分析(基于Betweenness centrality算法 )----------
处于枢纽节点的前10好友为
1--徐希文--0.21
2--colipso--0.20
3--刘杉--0.14
4--马佳--0.12
5--李超--0.11
6--吕秀芳--0.08
7--藏新汀--0.08
8--王大舸--0.08
9--王卉卉--0.06
10--陈欣--0.05
----------2014-06-08 21时49分07秒开始幕后黑手指数分析(基于Eigenvector centrality算法)---------
Not defined for multigraphs.
-------2014-06-08 21时49分07秒开始Google PageRank指数分析(基于Google PageRank算法)-------
pagerank() not defined for graphs with multiedges.
对一些词解释下:
枢纽:一个人同时属于两个不怎么想干的群体,那么这个人就处于枢纽的位置。
幕后黑手:顾名思义,一个人不怎么和大部分人联系,只和关键人物发生联系,通过关键人来影响群体。
在分析中后两个算法因为底层数据构造的社交网络为无向网络,所以在这一个具体分析中不适用。
2)核心交往圈
扯那么多基本人我不可能都认识,networkx还提供了分析某人的核心交往圈的算法,还是以我为例:

---------------2014-06-08 21时20分39秒开始整体分析----------------
社交网总共有502个好友
其他的分析因为是用同一个模块来实现的,和上面相同,就不重复了。
3)圈里圈外
上面的还只是宏观层面的结果,从微观层面看,在大群体中也总是少不了一个一个的小圈子,这个圈子里的人关系更为紧密,有着共同的话题,一般对圈子之外的人有一定的排斥性,而对圈子里的人信任度会很高,正所谓圈里圈外。
对于一门发展了将近半个世纪的学科,还是那句话,你想到的东西早就有人想到了。
比如我的好友圈中:
第45个小圈子为:
崔文英 殷渤涛 郑新玉 孙昊 陈欣 张辰星 陆伯文
这是我的一帮高中同学。
4)最短路径
已经有非常成熟的算法来寻找社交网络中的两个节点之间的最短路径。也就是所谓的六度空间。即我如果想认识某某,那么应该找那些最少的中间人来达到目的?
举一反三一下,如果是由各种书籍来组成的一个网络,书是节点,一个人如果读过两本书,那么这两本书就有个连线。问题来了,在各种小说APP上,如果一个人读了两本书,如何给他推荐第三本书?这两本书最短路径上的其它书嘛,有人会问,这不是两本书已经有连线了,路径不是最短了吗?这就涉及到了路径的权重问题,有了权重,直接的连线就不一定最短咯。权重如何得到?Well,It depands.
由于我只抓了两层好友,so,最短路径不会超过2.
随便找一个:colipso ---谷雨--- 范文卓 我想认识范,那么找谷雨就对了。
5)三人行
对于任意三个人,可以有如下16种关系:
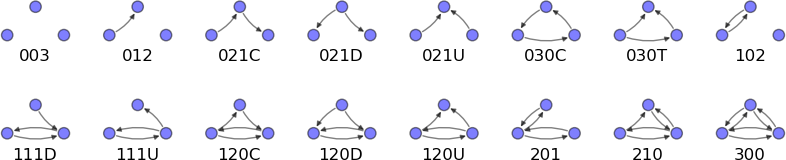
比如对于012C这种类型,作为中间人,是不是可以介绍另外两人认识那?
看看我的交往圈里面这16种类型各占多少:
201类型的三节点有94109个
021C类型的三节点有0个
021D类型的三节点有0个
210类型的三节点有0个
120U类型的三节点有0个
030C类型的三节点有0个
003类型的三节点有19747819个
300类型的三节点有3605个
012类型的三节点有0个
021U类型的三节点有0个
120D类型的三节点有0个
102类型的三节点有1112967个
111U类型的三节点有0个
030T类型的三节点有0个
120C类型的三节点有0个
111D类型的三节点有0个
当然,因为我只抓了两层交往圈,可以说还是比较核心的交往圈,所以很多三节点类型都没有出现,如果抓取的层数更多,结果会更显著。
仍然是举一反三,网络中的节点无论是人还是物,对于16种结构中的每一种其实都可以制定一定的策略来达到一定的目的。上述分析已经完成了行动的第一步,识别目标。
三:乱七八糟的一些想法
1)传统统计和现代分析
最近同时在研究R和社交网络分析,发现传统统计分析方法和现代分析方法还是有一些差别的。
传统统计分析方法起源于19世纪,无论是点估计/区间估计/假设检验都是依赖于一定的分布假设前提,更不要提贝叶斯统计,有大量的学术研究搞定了小样本下检验整体的方法,目的是想方设法降低计算量。但问题是现在的环境/用户偏好变化非常快,也就是分布变化快。用传统统计方法在分析的群体变化,分析的参数变化下还是有一定局限。
而现代的分析方法无论是蒙特卡洛模拟还是社交网络分析都是基于密集计算,管你什么分布,模拟100次不够,那就模拟10000次,100000次。根据大数定律,结果跑也跑出来了,八九不离十。
2)工具
上面的所有分析都是用python 和networkx模块完成。Python的灵活数据结构,大量的开源模块(numpy/scipy/matplotlib/networkx/webpy等等)可以说是居家旅行,数据分析的必备良药。清晰的语言规范也避免了括号风暴。我很欣赏。
networkx分析规模的瓶颈首先在于内存/存储,其次在于算法的合理性。对于10万以内的节点数还是容易应付的。如果节点数量级在于千万甚至亿,那就得好好设计了。
3)分析价值
分析能产生的价值一种是用于决策/一种用在产品。决策的对错在中长期能看到效果。产品则更直接,分析价值快速见于用户数量/意见。
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330