python 实例简述 k-近邻算法的基本原理
首先我们一个样本集合,也称为训练样本集,在训练样本集中每个数据都存在一个标签用来指明该数据的所属分类。在输入一个新的未知所属分类的数据后,将新数据的所有特征和样本集中的所有数据计算距离。从样本集中选择与新数据距离最近的 k 个样本,将 k 个样本中出现频次最多的分类作为新数据的分类,通常 k 是小于20的,这也是 k 的出处。
k近邻算法的优点:精度高,对异常值不敏感,无数据输入假定。
k 近邻算法的缺点:时间复杂度和空间复杂度高
数据范围:数值型和标称型
简单的k 近邻算法实现
第一步:使用 python 导入数据
from numpy import *
import operator
'''simple kNN test'''
#get test data
def createDataSet():
group=array([[1.0,1.1],[1.0,1.0],[0,0],[0,0.1]])
labels=['A','A','B','B']
return group,labels
作为例子,直接创建数据集和标签,实际应用中往往是从文件中读取数据集和标签。array 是 numpy 提供的一种数据结构,用以存储同样类型的数据,除了常规数据类型外,其元素也可以是列表和元组。这里 group 就是元素数据类型为 list 的数据集。labels 是用列表表示的标签集合。其中 group 和 labels 中的数据元素一一对应,比如数据点[1.0,1.1]标签是 A,数据点[0,0.1]标签是 B。
第二步:实施 kNN 算法
kNN 算法的自然语言描述如下:
1. 计算已知类别数据集中的所有点与未分类点之间的距离。
2. 将数据集中的点按照与未分类点的距离递增排序。
3. 选出数据集中的与未分类点间距离最近的 n 个点。
4. 统计这 n 个点中所属类别出现的频次。
5. 返回这 n 个点中出现频次最高的那个类别。
实现代码:
def classify0(inX,dataSet,labels,k):
dataSetSize=dataSet.shape[0]
diffMat=tile(inX,(dataSetSize,1))-dataSet
sqDiffMat=diffMat**2
sqDistances=sqDiffMat.sum(axis=1)
distances=sqDistances**0.5
sortedDistIndicies=distances.argsort()
classCount={}
for i in range(k):
voteIlabel=labels[sortedDistIndicies[i]]
classCount[voteIlabel]=classCount.get(voteIlabel,0)+1
sortedClassCount=sorted(classCount.iteritems(),key=operator.itemgetter(1),reverse=True)
return sortedClassCount[0][0]
classify0函数中的四个参数含义分别如下:inX 是希望被分类的数据点的属性向量,dataSet 是训练数据集向量,labels 是标签向量,k 是 kNN 算法的参数 k。
接下来来看看本函数的语句都做了那些事。
第一行dataSetSize=dataSet.shape[0],dataSet 是 array 类型,那么dataSet.shape表示 dataSet 的维度矩阵,dataSet.shape[0]表示第二维的长度,dataSet.shape[1]表示第一维的长度。在这里dataSetSize 表示训练数据集中有几条数据。
第二行tile(inX,(dataSetSize,1))函数用以返回一个将 inX 以矩阵形式重复(dataSetSize,1)遍的array,这样产生的矩阵减去训练数据集矩阵就获得了要分类的向量和每一个数据点的属性差,也就是 diffMat。
第三行**在 python 中代表乘方,那么sqDiffMat也就是属性差的乘方矩阵。
第四行array 的 sum 函数若是加入 axis=1的参数就表示要将矩阵中一行的数据相加,这样,sqDistances的每一个数据就代表输入向量和训练数据点的距离的平方了。
第五行不解释,得到了输入向量和训练数据点的距离矩阵。
第六行sortedDistIndicies=distances.argsort(),其中 argsort 函数用以返回排序的索引结果,直接使用 argsort 默认返回第一维的升序排序的索引结果。
然后创建一个字典。
接下来进行 k 次循环,每一次循环中,找到 i 对应的数据的标签,并将其所在字典的值加一,然后对字典进行递减的按 value 的排序。
这样循环完成后,classCount 字典的第一个值就是kNN 算法的返回结果了,也就是出现最多次数的那个标签。
二维的欧式距离公式如下,很简单:
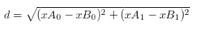
相同的,比如说四维欧式距离公式如下:

第三步:测试分类器
在测试 kNN 算法结果的时候,其实就是讨论分类器性能,至于如何改进分类器性能将在后续学习研究中探讨,现在,用正确率来评估分类器就可以了。完美分类器的正确率为1,最差分类器的正确率为0,由于分类时类别可能有多种,注意在分类大于2时,最差分类器是不能直接转化为完美分类器的。
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330