一、表变量
表变量在SQL Server
2000中首次被引入。表变量的具体定义包括列定义,列名,数据类型和约束。而在表变量中可以使用的约束包括主键约束,唯一约束,NULL约束和
CHECK约束(外键约束不能在表变量中使用)。定义表变量的语句是和正常使用Create Table定义表语句的子集。只是表变量通过DECLARE
@local_variable语句进行定义。
表变量的特征:
-
表变量拥有特定作用域(在当前批处理语句中,但不在任何当前批处理语句调用的存储过程和函数中), 表变量在批处理结束后自动被清除 。
-
表变量较临时表产生更少的存储过程重编译。
-
针对表变量的事务仅仅在更新数据时生效,所以锁和日志产生的数量会更少。
-
由于表变量的作用域如此之小,而且不属于数据库的持久部分,所以事务回滚不会影响表变量。
表变量可以在其作用域内像正常的表一样使用。更确切的说,表变量可以被当成正常的表或者表表达式一样在SELECT,DELETE,UPDATE,INSERT语句中使用,但是表变量不能在类似"SELECT select_list INTO table_variable"这样的语句中使用。而在SQL Server2000中,表变量也不能用于INSERT INTO table_variable EXEC stored_procedure这样的语句中。
表变量不能做如下事情:
-
虽然表变量是一个变量,但是其不能赋值给另一个变量。
-
check约束,默认值和计算列不能引用自定义函数。
-
不能为约束命名。
-
不能Truncate表变量。
-
不能向标识列中插入显式值(也就是说表变量不支持SET IDENTITY_INSERT ON)
下面来玩玩表变量吧。
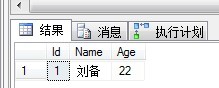
定义一个表变量,插入一条数据,然后查询:
DECLARE @tb1 Table (
Id int,
Name varchar(20),
Age int )
INSERT INTO @tb1 VALUES(1,'刘备',22)
SELECT * FROM @tb1
输出结果如下:
再来试试一些不符合要求的情况,例如添加表变量后,添加约束,并对约束命名:
ALTER TABLE @tb1 ADD CONSTRAINT CN_AccountAge CHECK (Account_Age > 18);
SQL Server提示错误如下:

SQL Server不支持定义表变量时对Constraint命名,也不支持定义表变量后,对其建Constraint。
更多的不允许,请查看上面的要求。
二、临时表
在深入临时表之前,我们要了解一下会话(Session),一个会话仅仅是一个客户端到数据引擎的连接。在SQL Server
Management
Studio中,每一个查询窗口都会和数据库引擎建立连接。一个应用程序可以和数据库建立一个或多个连接,除此之外,应用程序还可能建立连接后一直不释放
知道应用程序结束,也可能使用完释放连接需要时建立连接。
临时表和Create Table语句创建的表有着相同的物理工程,但临时表与正常的表不同之处有:
1、临时表的名称不能超过116个字符,这是由于数据库引擎为了辨别不同会话建立不同的临时表,所以会自动在临时表的名字后附加一串。
2、
局部临时表(以"#"开头命名的)作用域仅仅在当前的连接内
,从在存储过程中建立局部临时表的角度来看,局部临时表会在下列情况下被Drop:
a、显示调用Drop Table语句
b、当局部临时表在存储过程内被创建时,存储过程结束也就意味着局部临时表被Drop。
c、当前会话结束,在会话内创建的所有局部临时表都会被Drop。
3、
全局临时表(以"##"开头命名的)在所有的会话内可见,所以在创建全局临时表之前首先检查其是否存在,否则如果已经存在,你将会得到重复创建对象的错误。
a、全局临时表会在创建其的会话结束后被Drop,Drop后其他会话将不能对全局临时表进行引用。
b、引用是在语句级别进行,如:
1.新建查询窗口,运行语句:
CREATE TABLE ##temp(RowID int)
INSERT INTO ##temp VALUES(3)
2.再次新建一个查询窗口,每5秒引用一次全局临时表
While 1=1 BEGIN SELECT * FROM ##temp WAITFOR delay '00:00:05' END
3.回到第一个窗口,关闭窗口。 4.下一次第二个窗口引用时,将产生错误。

4、不能对临时表进行分区。
5、不能对临时表加外键约束。
6、临时表内列的数据类型不能定义成没有在TempDb中没有定义自定义数据类型(自定义数据类型是数据库级别的对象,而临时表属于
TempDb)。由于TempDb在每次SQL Server重启后会被自动创建,所以你必须使用startup stored
procedure来为TempDb创建自定义数据类型。你也可以通过修改Model数据库来达到这一目标。
7、XML列不能定义成XML集合的形式,除非这个集合已经在TempDb中定义。
临时表既可以通过Create Table语句创建,也可以通过"SELECT <select_list> INTO
#table"语句创建。你还可以针对临时表用"INSERT INTO #table EXEC stored_procedure"这样的语句。
临时表可以拥有命名的约束和索引。但是,当两个用户在同一时间调用同一存储过程时,将会产生”There is already an object
named ‘<objectname>’ in the
database”这样的错误。所以最好的做法是不用为建立的对象进行命名,而使用系统分配的在TempDb中唯一的。
三、误区
误区1.表变量仅仅在内存中。
误区2.临时表仅仅存储在物理介质中。
这两种观点都是错误的,只有内存足够,表变量和临时表都会在内存中创建和处理。他们也同样可以在任何时间被存入磁盘。
注意表变量的名字是系统分配的,表变量的第一个字符”@”并不是一个字母,所以它并不是一个有效的变量名。系统会在TempDb中为表变量创建一个系统分配的名称,所以任何在sysobjects或sys.tables查找表变量的方法都会失败。
正确的方法应该是我前面例子中的方法,我看到很多人使用如下查询查表变量:
select * from sysobjects where name like'#tempTables%'
上述代码看上去貌似很好用,但会产生多用户的问题。你建立两个连接,在第一个连接中创建临时表,在第二个窗口中运行上面的语句能看到第一个连接创建的临时表,如果你在第二个连接中尝试操作这个临时表,那么可能会产生错误,因为这个临时表不属于你的会话。
误区3.表变量不能拥有索引。
这个误区也同样错误。虽然一旦你创建一个表变量之后,就不能对其进行DDL语句了,这包括Create Index语句。然而你可以在表变量定义的时候为其创建索引)比如如下语句。
declare @MyTableVariable table (RowID intPRIMARY KEY CLUSTERED)
这个语句将会创建一个拥有聚集索引的表变量。由于主键有了对应的聚集索引,所以一个系统命名的索引将会被创建在RowID列上。
下面的例子演示你可以在一个表变量的列上创建唯一约束以及如何建立复合索引。
declare @temp TABLE (
RowID int NOT NULL,
ColA int NOT NULL,
ColB char(1)UNIQUE,
PRIMARY KEY CLUSTERED(RowID, ColA))
1) SQL
并不能为表变量建立统计信息,就像其能为临时表建立统计信息一样。这意味着对于表变量,执行引擎认为其只有1行,这也意味着针对表变量的执行计划并不是最
优。虽然估计的执行计划对于表变量和临时表都为1,但是实际的执行计划对于临时表会根据每次存储过程的重编译而改变。如果临时表不存在,在生成执行计划的
时候会产生错误。
2) 一旦建立表变量后就无法对其进行DDL语句操作。因此如果需要为表建立索引或者加一列,你需要临时表。
3) 表变量不能使用select …into语句,而临时表可以。
4) 在SQL Server 2008中,你可以将表变量作为参数传入存储过程。但是临时表不行。在SQL Server 2000和2005中表变量也不行。
5)
作用域:表变量仅仅在当前的批处理中有效,并且对任何在其中嵌套的存储过程等不可见。局部临时表只在当前会话中有效,这也包括嵌套的存储过程。但对父存储
过程不可见。全局临时表可以在任何会话中可见,但是会随着创建其的会话终止而DROP,其它会话这时就不能再引用全局临时表。
6) 排序规则:表变量使用当前数据库的排序规则,临时表使用TempDb的排序规则。如果它们不兼容,你还需要在查询或者表定义中进行指定。
7) 你如果希望在动态SQL中使用表变量,你必须在动态SQL中定义表变量。而临时表可以提前定义,在动态SQL中进行引用。
四、如何选择
微软推荐使用表变量,如果表中的行数非常小,则使用表变量。很多”网络专家”会告诉你100是一个分界线,因为这是统计信息创建查询计划效率高低
的开始。但是我还是希望告诉你针对你的特定需求对临时表和表变量进行测试。很多人在自定义函数中使用表变量,如果你需要在表变量中使用主键和唯一索引,你
会发现包含数千行的表变量也依然性能卓越。但如果你需要将表变量和其它表进行join,你会发现由于不精准的执行计划,性能往往会非常差。
为了证明这点,请看本文的附件。附件中代码创建了表变量和临时表.并装入了AdventureWorks数据库的
Sales.SalesOrderDetail表。为了得到足够的测试数据,我将这个表中的数据插入了10遍。然后以ModifiedDate
列作为条件将临时表和表变量与原始的Sales.SalesOrderDetail表进行了Join操作,从统计信息来看IO差别显著。从时间来看表变量
做join花了50多秒,而临时表仅仅花了8秒。
如果你需要在表建立后对表进行DLL操作,那么选择临时表吧。
临时表和表变量有很多类似的地方。所以有时候并没有具体的细则规定如何选择哪一个。对任何特定的情况,你都需要考虑其各自优缺点并做一些性能测试。下面的表格会让你比较其优略有了更详细的参考。
五、总结
|
特性
|
表变量
|
临时表
|
|
作用域
|
当前批处理
|
当前会话,嵌套存储过程,全局:所有会话
|
|
使用场景
|
自定义函数,存储过程,批处理
|
自定义函数,存储过程,批处理
|
|
创建方式
|
DECLARE statement only.只能通过DECLEARE语句创建
|
CREATE TABLE 语句
SELECT INTO 语句.
|
|
表名长度
|
最多128字节
|
最多116字节
|
|
列类型
|
可以使用自定义数据类型
可以使用XML集合
|
自定义数据类型和XML集合必须在TempDb内定义
|
|
Collation
|
字符串排序规则继承自当前数据库
|
字符串排序规则继承自TempDb数据库
|
|
索引
|
索引必须在表定义时建立
|
索引可以在表创建后建立
|
|
约束
|
PRIMARY KEY, UNIQUE, NULL, CHECK约束可以使用,但必须在表建立时声明
|
PRIMARY KEY, UNIQUE, NULL, CHECK. 约束可以使用,可以在任何时后添加,但不能有外键约束
|
|
表建立后使用DDL (索引,列)
|
不允许
|
允许.
|
|
数据插入方式
|
INSERT 语句 (SQL 2000: 不能使用INSERT/EXEC).
|
INSERT 语句, 包括 INSERT/EXEC.
SELECT INTO 语句.
|
|
Insert explicit values into identity columns (SET IDENTITY_INSERT).
|
不支持SET IDENTITY_INSERT语句
|
支持SET IDENTITY_INSERT语句
|
|
Truncate table
|
不允许
|
允许
|
|
析构方式
|
批处理结束后自动析构
|
显式调用 DROP TABLE 语句. 当前会话结束自动析构 (全局临时表: 还包括当其它会话语句不在引用表.)
|
|
事务
|
只会在更新表的时候有事务,持续时间比临时表短
|
正常的事务长度,比表变量长
|
|
存储过程重编译
|
否
|
会导致重编译
|
|
回滚
|
不会被回滚影响
|
会被回滚影响
|
|
统计数据
|
不创建统计数据,所以所有的估计行数都为1,所以生成执行计划会不精准
|
创建统计数据,通过实际的行数生成执行计划。
|
|
作为参数传入存储过程
|
仅仅在SQL Server2008, 并且必须预定义 user-defined table type.
|
不允许
|
|
显式命名对象 (索引, 约束).
|
不允许
|
允许,但是要注意多用户的问题
|
|
动态SQL
|
必须在动态SQL中定义表变量
|
可以在调用动态SQL之前定义临时表
|
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330