数据新闻最常见的四大问题
人们通常觉得数据新闻从本质上就比其它类型的报道更客观。数字不会说谎,对吧?
错了。
和数据打交道时,有太多办法可以欺骗受众,甚至误导自己,这些错误甚至可能是无心之失。过去一年研究数据新闻的第一手经验让我发现,要犯一些最终导致结论完全歪曲的错误实在是太容易了。以下便是过去这一年里我所遇到的糟糕的数据新闻最常见的四大问题:
1. 缺乏上下文或比例系数
没有语境的数字是没有意义的。缺乏背景信息的问题在有关财政支出的新闻中尤其明显,其它类型的报道中这种错误也经常蹦出来。
举个例子:
“纳税人花费十亿美元为非法移民儿童买单”、“福利津贴花掉64亿英镑”——这些天文数字组成的标题听上去让人愤慨不已。但事实是,公共支出数据常常都是天文数字,把数据放到上下文里看,分解到每个人头上,你会发现这些数字可能是完全合理的。
这个故事告诉我们?比例系数通常比绝对数值更有内涵。但比例系数也并不总是最正确的呈现方式。从你的数据出发,想想有什么办法能够最忠实的呈现它。
卫报(The Guardian)数据新闻记者James Ball建议所有数据新闻记者汇总一些基本的数字,既避免犯初级错误,也更容易一眼看出数据和结论是否合理,比如全国处于工作年龄段的人有多少、平均工资、就业率等。这不失为一种办法。
2. 相关性不等于因果关系
只要你懂哪怕一点点统计学,你应该知道,相关性和因果关系是两个截然不同的东西。
然而,这一点却总是被新闻编辑室的人忽略。不要仅仅因为刚好有两个变量呈现相关性,就以为你有了条独家新闻。这种相关性完全有可能是其它一些潜在变量引起的,又或者,纯属巧合。
比如下图:
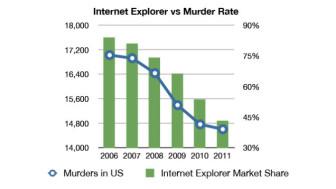
IE浏览器的市场份额 VS 美国谋杀率数据(图片来自Gizmodo)
这张图中IE浏览器的市场份额与美国谋杀率的关系是我最爱的例子之一-它们俩的超高相关性是不是看上去容易让人迷惑?想了解更多具有欺骗性的相关性,可以上这个名叫“伪相关”(Spurious Correlations)的网站看看(别怪我害你在那儿流连忘返浪费了一整个下午!)
3. 不知道怎样把数据可视化
这个问题值得专门写一篇文章,甚至好几篇文章,不过这里我只能点到为止。
好不容易,你做完了数据分析,挖出了一条大新闻,但一个差劲的视觉化呈现就能让你前功尽弃。糟糕的可视化可能会让读者产生疑问,甚至可能误导他们。比如,请不要这样……
(图片来自Business Insider)
不要用线形图表 (line chart) 表现离散数据,更不要去尝试那些看上去炫酷的3D饼状图,有可能你还在参与那场关于到底能否截短Y轴的永恒辩论。
数据可视化是艺术,更是科学。这里有一些好的指导书和网站,教你如何避免这些可视化中的潜在陷阱:
The Functional Art, by Alberto Cairo
Data Visualization – Principles and Practice, by Alexandru Telea
VisualisingData.com
4. 忽略文字叙述
在我看来,这是最重要的一点:
数据新闻给了我们以量化方式探索某个话题的力量,但它仍是新闻的一种,也就是说,它的本质还是storytelling(讲故事)。如果你只是扔出一堆随机数字,那你并没有做好这项工作。数据及其呈现只是一个开端,你要引导你的读者,讲完这个故事。你要让他们理解为什么那些数字如此重要,它们代表了什么。正如数据记者Tanveer Ali在《哥伦比亚新闻评论》(Columbia Journalism Review)中所说:

“数据是讲故事的一种方式,而非故事本身。”
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330