数据分析系列篇:互联网金融数据分析应用
互联网金融在国内发展也才2年多的时间,从货币基金到P2P到众筹到股票基金,从传统ATM和手机银行短信银行,感慨这个互联网金融的到来,让我们有更多的信息渠道可以来了解金额。
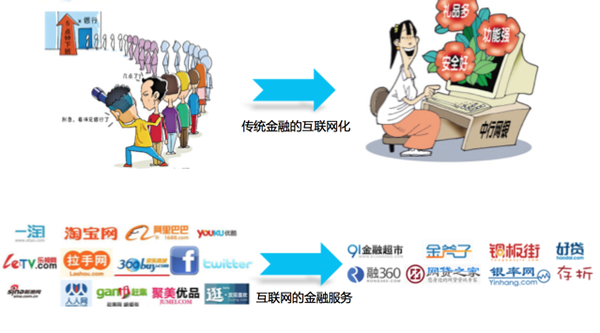 还有像越女读财介绍的高暴利的钱宝网、MMM、百川币这些,如果没有互联网,相信他们也很难发展的起来。
还有像越女读财介绍的高暴利的钱宝网、MMM、百川币这些,如果没有互联网,相信他们也很难发展的起来。
主要介绍下互联网金融行业的相关公司主要应用的数据分析有哪些,这个区别于之前介绍的在电商、零售中的数据分析应用,零售中得数据分析解决的更多是卖得问题,而金融中更多涉及到得是风险的问题。
好了,不废话。直接上干货。
互联网金融中的数据分析主要体现在个人征信、贷款授信、风险控制、洗钱套现识别、保险定价和云计算平台、量化投资这些应用。
1.个人征信
目前国内外的个人征信这块的发展如下:
一、美国的征信业务发展现状
··········1)FICO和三大征信机构
··········2)ZestFiance
··········3)Credit Karma及其他
二、中国的征信业务发展概况
··········1)聚信立
··········2)安融征信
··········3)快查
··········4)闪银奇异
··········5)京东金融
··········6)腾讯(腾讯信用)——腾讯征信
··········7)阿里(蚂蚁金服)——芝麻信用
··········8)平安(前海征信)
美国征信:
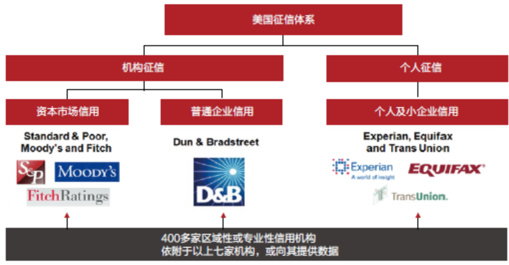 其中的数据应用
其中的数据应用
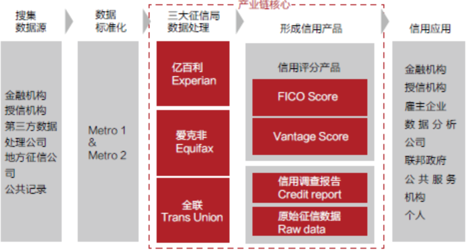
1)FICO和三大征信机构
最主流的FICO信用评分体系(Fair Isaac公司旗下的产品)现已覆盖了全美90%的借贷机构和85%的人群,三大征信局Experian、Equifax和Trans Union都是采用FICO的模型计算信用分,只是数据来源略有差异。 2)ZestFiance及它与FICO的区别ZestFiance,原名ZestCash,是美国一家新兴的互联网金融公司。在美国,ZestFiannce和FICO是完全对立的另一种信用评分体系,所以不存在“美国FICO信用积分指标从ZestFinance获得用户行为信用数据”的情况,ZestFiannce主要服务对象是FICO评分低于500甚至无信用评分的人群,而且市场很小,只有大约10万用户量。和FICO的区别在于:
2)ZestFiance及它与FICO的区别ZestFiance,原名ZestCash,是美国一家新兴的互联网金融公司。在美国,ZestFiannce和FICO是完全对立的另一种信用评分体系,所以不存在“美国FICO信用积分指标从ZestFinance获得用户行为信用数据”的情况,ZestFiannce主要服务对象是FICO评分低于500甚至无信用评分的人群,而且市场很小,只有大约10万用户量。和FICO的区别在于:
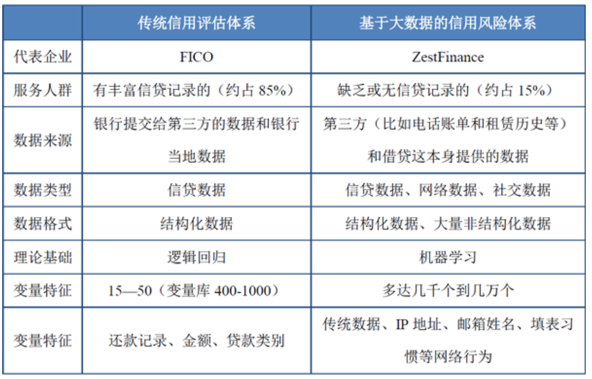 在其模型中,往往要用到 3500 个数据项,从中提取 70,000 个变量,利用10个预测分析模型,如欺诈模型、身份验证模型、预付能力模型、还款能力模型、还款意愿模型以及稳定性模型,进行集成学习或者多角度学习,并得到最终的消费者信用评分。其次,ZestFinance公司另辟蹊径,充分利用丢失数据之间的关联和正常数据的交叉,探寻数据丢失的原因。另外,每个季度ZestFinance公司都会推出一个新的信用评估模型,目前已覆盖信贷、市场营销、收债、助学贷款收债、法律收债和次级汽车抵押贷款等方面。
在其模型中,往往要用到 3500 个数据项,从中提取 70,000 个变量,利用10个预测分析模型,如欺诈模型、身份验证模型、预付能力模型、还款能力模型、还款意愿模型以及稳定性模型,进行集成学习或者多角度学习,并得到最终的消费者信用评分。其次,ZestFinance公司另辟蹊径,充分利用丢失数据之间的关联和正常数据的交叉,探寻数据丢失的原因。另外,每个季度ZestFinance公司都会推出一个新的信用评估模型,目前已覆盖信贷、市场营销、收债、助学贷款收债、法律收债和次级汽车抵押贷款等方面。
3)Credit Karma及其他
一个免费查FICO分(TransUnion和Equifax)和简版信用报告的平台(美国政府规定,三大征信局每年为用户提供仅一次免费查询信用记录的机会)。并且用户可以在平台上查看自己的各项财务状况,根据用户的信用信息及个人金融信息推荐合适的信用卡、更优惠的车贷和房贷等信贷产品,当会员购买了金融机构的产品后,机构变付费给Credit Karma。产品运营模式: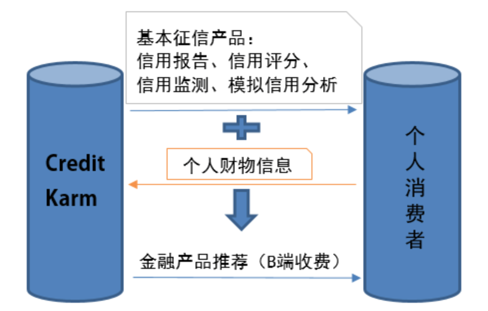 中国征信:
中国征信:
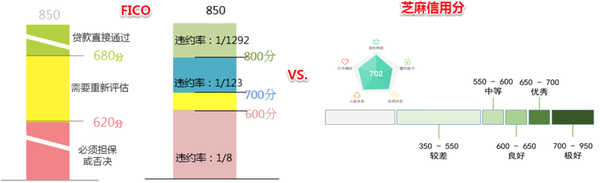
国内的个人征信方面,芝麻信用是长的最像FICO的。
-
Base FICO范围:300-850(Industry-Specific FICO范围:250-900);芝麻信用分范围:350-950。
-
FICO数据维度:偿还历史×35% + 信用账户数×30% + 使用信用的年限×15% + 正在使用的信用种类×10% + 新开立的信用账户×10%;蚂蚁信用分:信用历史×35% + 行为偏好×25% + 履约能力×20% + 身份特征×15% + 人脉关系×5%。
-
信用等级划分
2.风险控制
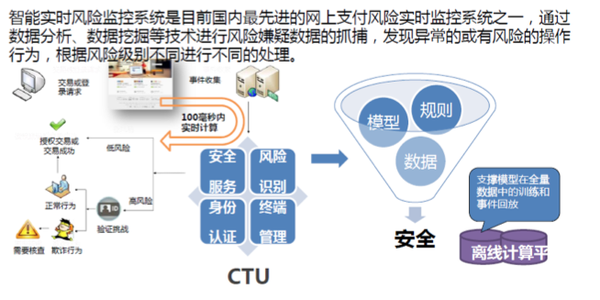
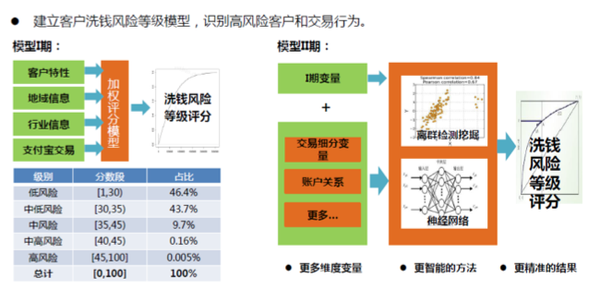
风险控制这块主要包括用户行为识别比如盗卡盗号、洗钱套现等
3.贷款授信
传统的贷款方式
 互联网金融的贷款方式:
互联网金融的贷款方式:
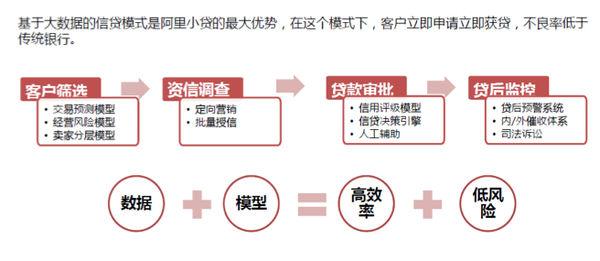
1)阿里小贷
2)宜人贷
宜人贷的数据源包括:
信用卡数据
淘宝天猫京东购买数据
运营商的通话记录
爬虫数据
生态伙伴第三方数据
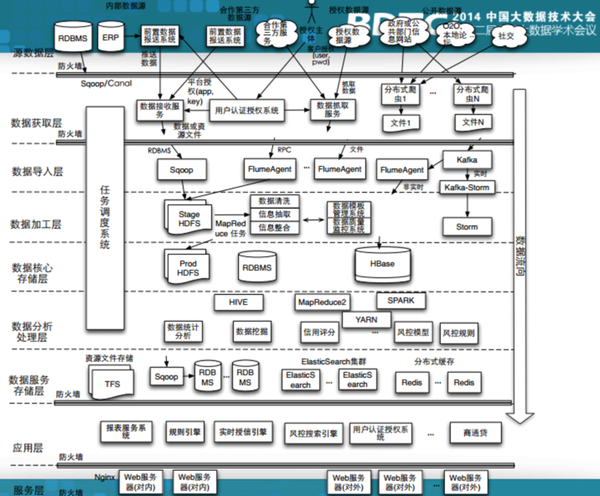 可能很多人会问我说,因为时间关系,没有办法我只能说做一个非常非常简单的展示,传统的金融机构,大家也做模型,做算法很多诸如此类的数据挖掘,传统的数据模型,比如说,他可能会放几十个变量,或者撑死了放几百个变量,我们的方法不一样,我的有几十万个或者更多的变量,传统的模型里头,非常强调说所有的这些特征,要是可以解释的。所以他需要非常非常强的特征。在我的这个模型里头,在我们这个平台的模型里头,对于我来讲,所有的数据,都是信用数据。当中交易数据,流水数据这些数据大家可以想象到,其他很多的数据,比如你的搜搜数据,网上的很多其他点击数据也是特征。如果这些特征被吸收的话,可能非常弱的特征没有关系,最后我能做出不管是信用,还是反欺诈,我后面有一堆模型在这边,我做的手段跟传统机构不一样的。
可能很多人会问我说,因为时间关系,没有办法我只能说做一个非常非常简单的展示,传统的金融机构,大家也做模型,做算法很多诸如此类的数据挖掘,传统的数据模型,比如说,他可能会放几十个变量,或者撑死了放几百个变量,我们的方法不一样,我的有几十万个或者更多的变量,传统的模型里头,非常强调说所有的这些特征,要是可以解释的。所以他需要非常非常强的特征。在我的这个模型里头,在我们这个平台的模型里头,对于我来讲,所有的数据,都是信用数据。当中交易数据,流水数据这些数据大家可以想象到,其他很多的数据,比如你的搜搜数据,网上的很多其他点击数据也是特征。如果这些特征被吸收的话,可能非常弱的特征没有关系,最后我能做出不管是信用,还是反欺诈,我后面有一堆模型在这边,我做的手段跟传统机构不一样的。
4.保险定价
保险定价这块主要的场景包括车险的定价、运费险。
车险:其实根据车主的日常行车路线、里程、行车习惯、出险记录、职业、年龄、性别,可以给出非常不同的定价。比如一个开中级车,每天固定路线往返几公里通勤的熟练女白领车主,和一个开同样车型每天在珠三角或者长三角跑生意的中年暴躁小老板车主,假设后者出险概率是前者的3倍,那么完全可以定3倍于前者的价格(商业部分)。对于保险公司,前者才是优质客户,后者做了生意也是赔钱货,不如赶到竞争对手那里去。
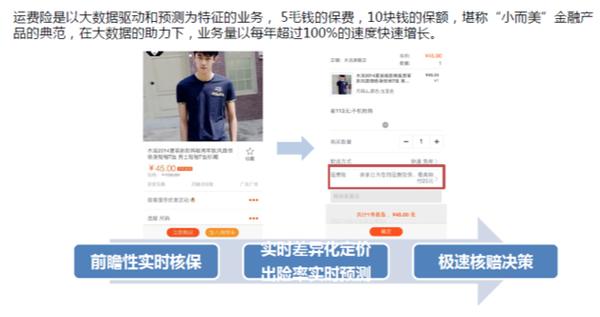
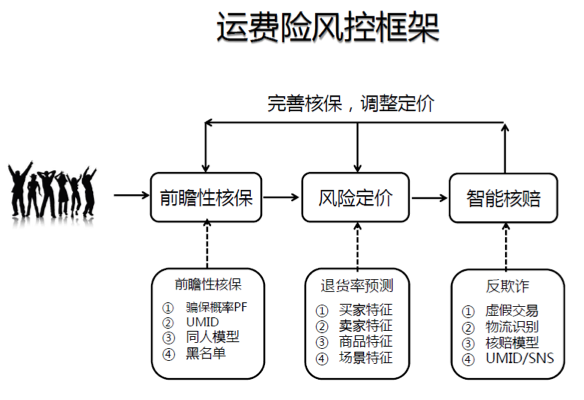
运费险:
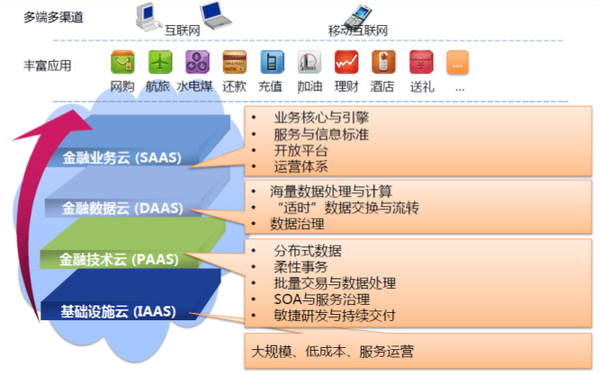
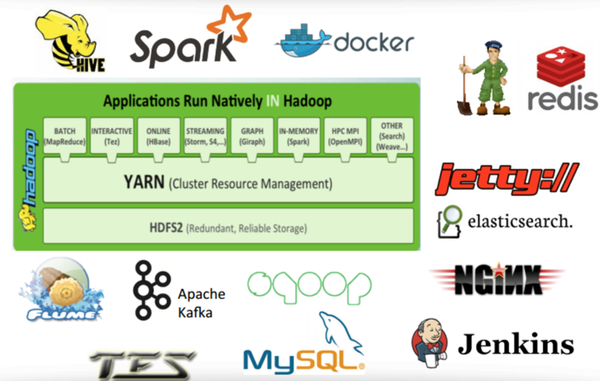
5.云计算
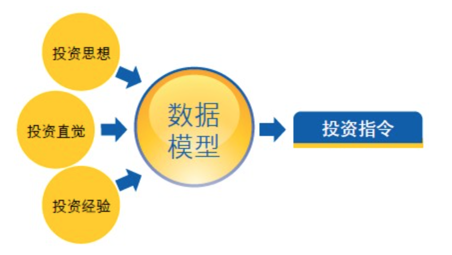
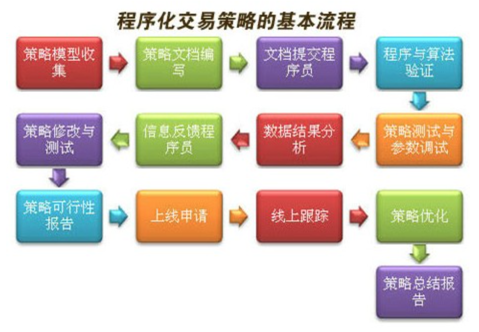
6.量化投资
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330