数据分析实例:在一线城市的你,生活有多苦逼
曾经,“逃离北上广”成为年轻人中一个口号式的选择,但是,这个口号根本就没喊上多久,就没人响应了,因为,“逃离北上广”的人又都回来了。只有“北上广”加上深圳,才聚集着中国最多的资源、最好的机会,逃是逃不掉的。那么,只有“拼”,拼就拼一个星光灿烂。
滴滴打车与生鲜电商“本来生活网”对交通出行、回家吃饭这两件大事进行联合调查。数据显示,北京晚上20点以后回家的人群,占到了30%。综合各项标准,北上广深四个城市中,北京人仍然是最拼最累的。
上班里程
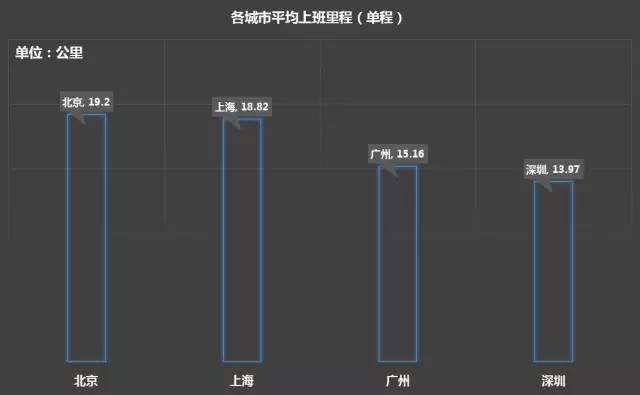
北京城市面积最大,人均上班里程也最长,为19.2公里;其次为上海18.82公里;广州和深圳平均就要短一些,分别为15.16公里和13.97公里。拿北京而言,翻山越岭中关村,望眼欲穿CBD都不算事,光是上班路上就得非常拼。
上班时间
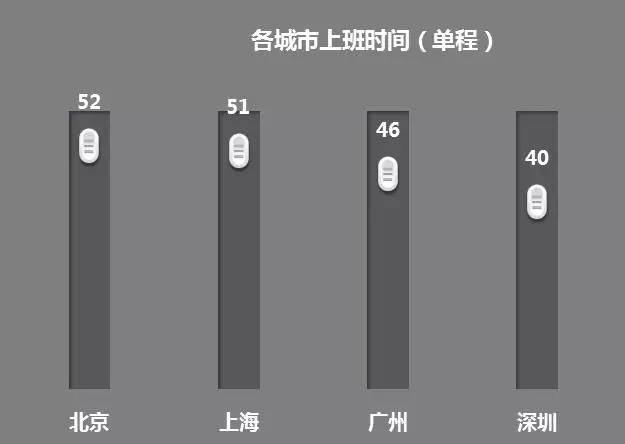
整体来看,北京平均上班要52分钟,上海要51分钟,差异不是很大;广州需46分钟,深圳得40分钟。每天早晚高峰各堵1小时,从22岁到80岁,会有30624个小时,相当于10.48年,而这就少了许多对家人的陪伴。
深夜出行范围
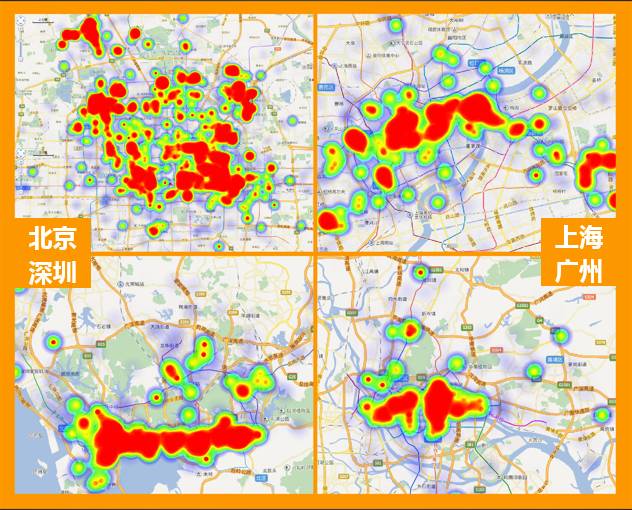
这是四大城市晚间出行的热力图,看吧,颜色最重、范围最大的是北京吧?
热力图上看,夜22:00-23:00,上海、深圳、广州三个城市的打车地点集中在城市商区,而北京的集中打车地点遍布整个城市,每个角落的人都在以自己的方式奔忙。再细微观察北京,深夜打车的人,大CBD地区和大中关村地区仍然是最重要的区域,这两个地方集中了北京最多的大型公司、互联网公司。想一想,这些拖着疲惫身躯刚刚走出办公室的人们,他们那倦怠的身心吧。
4月,一项“吸血加班楼”的评选活动中,北京国贸地区、上海陆家嘴、深圳深南大道是这三个城市加班最集中的地区,果然到了晚上热力不减。快节奏的大时代,每分钟都在翻天覆地变化着。
出行时间峰值
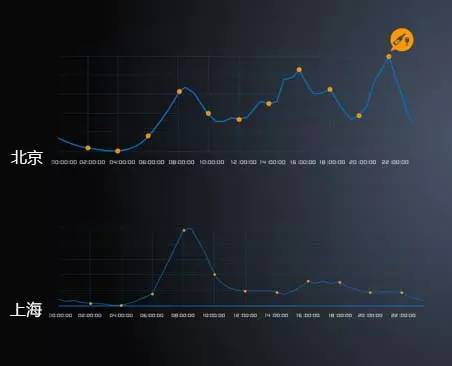
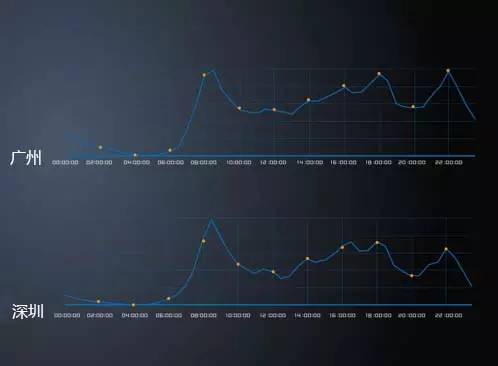
数据显示,上海只有上午9:00出现一次早高峰,没有晚高峰和夜高峰,也说明上海人比较享受生活,而非工作。广州和深圳的出行波峰走向非常一致,下午高峰和晚高峰峰值也基本相同。而在北京,一天中三次高峰非常明显,夜高峰的订单量远远高于早高峰和晚高峰,加班到深夜才回家的人是上班族的大多数。

在程序员、工程师等聚齐的北京西二旗,到了晚上,只有26%的人能正常下班回家,18%的人22点回家。而凌晨以后,还有10%的人在忙着改变世界。
晚回家人数
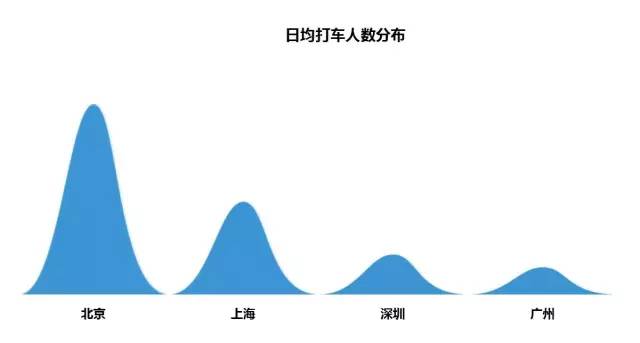
四个城市中,北京和上海人口数量相仿,但日均打车人数北京远远高于上海;深圳和广州人数差不多,打车人数深圳稍高于广州。北京城市过大,市中心到家的距离很远,紧张忙碌的城市中,分分秒秒都很可贵,这时候选择叫车回家最为方便。
互联网大数据
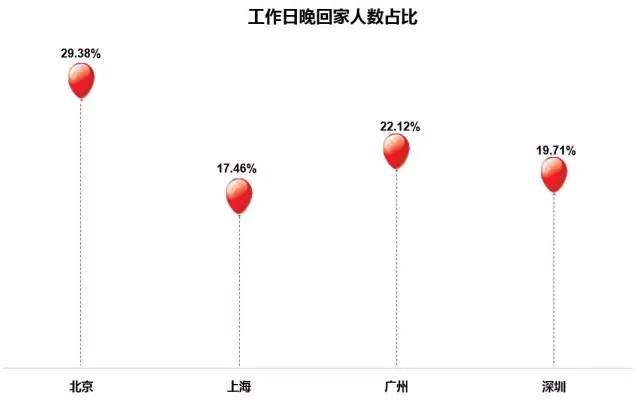
在晚回家人数的比例中,北京占到29.38%,广州居于其次为22.12%,深圳19.71%,而上海人的比例最少,这也与打车峰值分布相符合。
北上广深四个城市的上班族每天步履匆匆,繁忙的工作也在挤压着私人空间。四个城市中,北京人出行时间最长、加班时间最晚、加班范围最广、不能回家吃饭比例最高,各项指标都完胜上海、广州、深圳。
数据不能说明一切,每个人的生活体验更直观、更细致。在这个城市里打拼,你的前景将有更多的可能性,有梦想就有希望,有坚持就有价值。也许每年都有那么几个瞬间,虽然挤在人海中,仍觉得这是一座希望之城。
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330